이 글은 파이썬 머신 러닝의 저자 세바스찬 라쉬카(Setabstian Raschka)가 쓴 ‘Model evaluation, model selection, and algorithm selection in machine learning Part I – The basics‘를 원저자의 동의하에 번역한 것입니다. 이 시리즈 글의 전체 번역은 Model evaluation, selection and algorithm selection에 있습니다.
소개
머신 러닝machine learning은 소비자나 고객으로서 또 연구자나 기술자 입장에서도 우리 생활의 중심이 되었습니다. 예측 모델을 연구나 비즈니스에 적용할 때 공통으로 원하는 한가지는 바로 “좋은” 예측입니다. 훈련 데이터에 모델을 학습시키는 것도 중요하지만 이 모델이 이전에 본 적이 없는 데이터에도 잘 일반화 될지 어떻게 알 수 있을까요? 입력한 훈련 데이터를 단순히 기억하는 것이 아니라 미래의 데이터, 즉 한 번도 본 적이 없는 데이터에 대해 좋은 예측을 만들 것이라고 어떻게 알 수 있을까요? 어떻게 한번에 좋은 모델을 선택할 수 있을까요? 혹시 문제에 더 잘 맞는 다른 머신 러닝 알고리즘이 있는 건 아닐까요?

모델 평가가 머신 러닝 파이프라인pipeline의 종착지는 아닙니다. 어떤 데이터를 다루던지 사전에 계획을 세우고 목적에 맞는 방법을 사용해야 합니다. 이 글에서는 이런 방법들 중 하나를 선택해서, 좀 더 큰 그림의 전형적인 머신 러닝 워크플로우workflow에 적용하는 방법을 살펴 보겠습니다.
성능 추정: 일반화 성능 vs 모델 선택
간단한 절의 응답으로 시작해 보겠습니다.
Q: “어떻게 머신 러닝 모델의 성능을 추정하나요?”
A: “첫째 모델을 학습시키기 위해 알고리즘에 훈련 데이터를 주입합니다. 둘째 테스트 세트의 레이블을 예측합니다. 셋째 테스트 세트에서 잘못 예측한 수를 카운트해서 모델의 예측 정확도를 계산합니다.”
그리 간단하지 않군요. 목적에 따라서 모델의 성능을 추정하는 일은 그리 쉽지 않습니다. 앞의 질문을 다른 각도로 봐야할지 모릅니다. “왜 성능 추정이 중요한가요?” 이상적으로는 추정된 모델의 성능이 새로운 데이터에 모델이 얼마나 잘 작동하는지를 말해 줍니다. 미래의 데이터에 대해 예측하는 것이 종종 새로운 알고리즘의 개발이나 머신 러닝 애플리케이션에서 우리가 풀려고 하는 주된 문제입니다. 전형적으로 머신 러닝은 많은 실험을 해야 합니다. 예를 들면 알고리즘 내부 설정인 하이퍼파라미터hyperparameter를 튜닝하는 일입니다. 훈련 데이터셋에 대해 다른 하이퍼파라미터 설정으로 알고리즘을 학습시키면 다른 모델이 만들어집니다. 이 중에서 가장 잘 작동하는 모델을 선택하고 싶기 때문에 각각의 성능을 추정하여 순위를 매기기는 방법이 필요합니다. 알고리즘을 세세하게 튜닝하는 것에서 더 나아가 주어진 환경에서 최선의 솔루션을 찾기 위해 하나의 알고리즘만 테스트하지 않습니다. 예측 성능과 연산 성능 측면에서 종종 다른 알고리즘들을 서로 비교할 때가 많습니다.
왜 우리가 모델의 예측 성능을 평가해야 하는지 요약해 보겠습니다.
- 모델이 미래의 (처음 본) 데이터에 대한 예측 성능인 일반화 정확도generalization accuracy를 추정하고 싶습니다.
- 학습 알고리즘을 튜닝하고 주어진 가설 공간hypothesis space안에서 가장 성능 좋은 모델을 골라 예측 성능을 높이고 싶습니다.
- 문제 해결에 가장 적합한 머신 러닝 알고리즘을 찾길 원합니다. 즉 알고리즘의 가설 공간에서 최대 성능의 모델을 찾는 것은 물론 최대 성능을 내는 알고리즘을 선택하기 위해 여러 알고리즘들을 비교하고 싶습니다.
위에 나열한 세 개의 작업은 모두 공통으로 모델의 성능을 추정해야 하지만 각기 다른 접근 방법이 필요합니다. 이 글에서 이 세 가지 작업을 위한 각기 다른 방법에 대해 다루어 보겠습니다.
당연하게 모델의 미래 성능을 가능한 정확하게 예측하고 싶습니다. 그러나 이 글에서 딱 하나를 얻어 갈 것이 있다면, 모델과 알고리즘 선택에서 편향bias이 모든 모델에 동일하게 영향을 미친다면 편향된 성능 추정이 아무런 문제가 안된다는 사실입니다. 우리가 가장 높은 성능의 모델을 선택하기 위해 여러가지 모델과 알고리즘의 랭킹을 매길때 필요한 것은 상대적인 성능입니다. 예를 들어 우리의 성능 평가가 매우 편향되어 있어서 10%정도 과소 평가되더라도 순위에는 영향을 미치지 않습니다. 정확히 말해서 세 개 모델의 예측 성능 평가가
M2: 75% > M1: 70% > M3: 65%
이라면 10% 비관적인 편향을 더하더라도 순위는 같습니다.
M2: 65% > M1: 60% > M3: 55%
하지만 가장 좋은 모델(M2)의 예측 정확도가 65%라고 보고한다면 이는 매우 잘못된 것입니다. 모델의 절대적인 성능을 추정하는 것은 아마도 머신 러닝 분야에서 가장 어려운 과제 중 하나일 것입니다.
가정과 용어
모델 평가는 진짜 복잡한 주제입니다. 핵심에서 너무 벗어나지 않기 위해 필요한 가정과 이 글에서 사용할 기술 용어를 살펴 보겠습니다.
i.i.d
우리는 샘플이 i.i.d(독립적이고 동일한 확률분포independent and identically distributed)라고 가정합니다. 즉 모든 샘플은 동일한 확률 분포로 선택되어지고 통계적으로 서로 독립적입니다. 샘플이 독립적이지 않는 경우는 일시적인 데이터나 시계열 데이터를 다룰 때 입니다.
지도 학습과 분류
이 글은 머신 러닝의 하위 분야로서 데이터셋에 타깃 값이 들어 있는 지도 학습supervised learning에 촛점을 맞출 것입니다. 여러가지 개념이 회귀regression에도 적용될 수 있지만, 범주형의 타깃 레이블을 샘플에 할당하는 분류classification 문제에 집중하겠습니다.
0-1 손실과 예측 정확도
다음으로 예측 정확도에 대해 알아 보겠습니다. 예측 정확도는 예측이 맞는 샘플 수를 전체 샘플 수 n 으로 나눈 것입니다. 또는 수식으로는 예측 정확도 ACC를 다음과 같이 정의합니다

예측 오차 ERR 은 데이터셋 S 에서 샘플 n 에 대해 0-1 손실의 기대값입니다:

0-1 손실 L(·) 은 아래와 같이 정의 됩니다
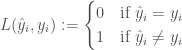
여기서 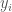

우리의 목적은 일반화 성능이 좋은 모델 h 를 학습시키는 것입니다. 그 모델은 예측 성능을 극대화하거나 반대로 잘못된 예측 가능성 C(h) 를 최소화합니다.
![C(h) = \underset{(x,y) \sim D}{Pr} [h(x) \ne y]](https://s0.wp.com/latex.php?latex=C%28h%29+%3D+%5Cunderset%7B%28x%2Cy%29+%5Csim+D%7D%7BPr%7D%C2%A0%5Bh%28x%29+%5Cne+y%5D&bg=ffffff&fg=444444&s=0&c=20201002)
D 는 데이터를 구성하는 분포를 나타내고 x 는 샘플의 특성 벡터, y 는 클래스 레이블입니다.
마지막으로 우리는 대부분 이 글에서 (에러 대신) 예측 정확도를 언급하기 때문에 디렉 델타 함수Dirac Delta function를 사용하겠습니다.1
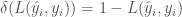
그러므로

이고
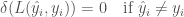
입니다.
편향
이 글에서 편향bias이란 용어를 사용할 땐 (머신 러닝 시스템에서의 편향이 아니라) 통계적인 편향을 의미합니다. 일반적인 용어로 추정량estimator 
![E[\hat{\beta}]](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Cbeta%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002)
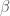
![Bias = E[\hat{\beta}] - \beta](https://s0.wp.com/latex.php?latex=Bias+%3D+E%5B%5Chat%7B%5Cbeta%7D%5D+-+%5Cbeta&bg=ffffff&fg=444444&s=0&c=20201002)
그래서 만약 ![E[\hat{\beta}] - \beta = 0](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Cbeta%7D%5D+-+%5Cbeta+%3D+0&bg=ffffff&fg=444444&s=0&c=20201002)
분산
분산variance은 추정량
![Variance = E \left[ (\hat{\beta} - E[\hat{\beta}])^2 \right]](https://s0.wp.com/latex.php?latex=Variance+%3D+E+%5Cleft%5B+%28%5Chat%7B%5Cbeta%7D+-+E%5B%5Chat%7B%5Cbeta%7D%5D%29%5E2+%5Cright%5D+&bg=ffffff&fg=444444&s=0&c=20201002)
분산은 우리가 훈련 세트를 조금씩 변화시키면서 학습 과정을 반복할 때 모델의 예측의 변화량을 측정한 것입니다. 모델 구축 프로세스가 데이터의 변화에 민감할수록 분산은 더 커집니다.
마지막으로 모델, 가설, 분류기, 학습 알고리즘, 파라미터 용어를 정리하겠습니다:
- 목적 함수target function: 예측 모델링에서는 전형적으로 특정 프로세스를 모델링하게 됩니다. 즉 어떤 알려지지 않은 함수를 학습 또는 근사하는 것입니다. 목적 함수 f(x) = y 는 우리가 모델링 하려고 하는 진짜 함수 f(·) 입니다.
- 가설hypothesis: 가설은 우리가 모델링하려는 타깃 함수, 즉 진짜 함수와 비슷할거라 믿는 (혹은 희망하는) 어떤 함수입니다. 스팸 분류에서라면 스팸 이메일을 구분하는 분류 규칙이 됩니다.
- 모델: 머신 러닝 분야에서는 가설과 모델이 종종 혼용되어 사용됩니다. 다른 과학 분야에서는 이 둘이 다른 의미를 가지기도 합니다. 가설은 과학자에 의해 성립된 추측이고 모델은 이 가설을 테스트하기 위한 추측의 구현체입니다.
- 학습 알고리즘: 우리의 목표는 목적 함수를 찾거나 근사하는 것이고, 학습 알고리즘은 훈련 데이터셋을 사용해 목적 함수를 모델링하려는 일련의 명령 집합입니다. 학습 알고리즘은 가설 공간을 동반하며 미지의 목적 함수를 모델링하기 위해 가능한 가설들을 탐색하여 최종 가설을 만듭니다.
- 분류기classifier: 분류기는 가설의 (요즘엔 종종 머신 러닝 알고리즘으로 학습된) 특별한 경우입니다. 하나의 개개의 데이터 포인트에 (범주형) 클래스 레이블을 지정하는 가설 또는 이산값discrete value을 출력하는 함수입니다. 이메일 분류의 경우 스팸 또는 스팸이 아닌 것으로 이메일을 분류하기 위한 하나의 가설이 분류기가 될 수 있습니다. 그러나 가설이 분류기와 동의로 사용되어서는 안됩니다. 다른 애플리케이션의 경우엔 가설이 학생의 학습시간과 교육 이력을 (연속형이므로 회귀에 적합한) 앞으로 받을 SAT 점수와 매핑하는 하나의 함수일 수 있습니다.
- 하이퍼파라미터: 하이퍼파라미터는 머신 러닝 알고리즘의 튜닝 파라미터입니다. 예를 들면, 회귀 분석의 평균 제곱 오차mean squared error 비용 함수cost function에서 L2 페널티penalty의 규제regularization 강도나 결정 트리의 최대 깊이 설정 값입니다. 반대로 모델 파라미터는 학습 알고리즘이 훈련 데이터에서 학습하는 파라미터입니다. 즉 모델 자체가 가지고 있는 파라미터입니다. 예를 들어 선형 회귀의 가중치 계수coefficient(또는 기울기)와 편향3(또는 y 축의 절편)이 모델 파라미터입니다.
재치환 검증과 홀드아웃 방법
홀드아웃holdout 방법은 아주 단순한 모델 평가 방법입니다. 레이블된 데이터셋을 훈련 세트와 테스트 세트 두 부분으로 나눕니다. 그런 다음 훈련 데이터에서 모델을 학습시키고 테스트 세트의 레이블을 예측합니다. 정확한 예측의 비율이 예측 정확도에 대한 추정치가 됩니다. 물론 예측하는 동안 테스트 레이블은 감추어져 있습니다. 우리는 같은 훈련 데이터셋으로 모델을 훈련하고 평가하고 싶지 않습니다(이를 재치환 평가resubstitution evaluation라고 부릅니다). 왜냐하면 과대적합overfitting으로 인해 편향이 매우 감소하기 때문입니다. 다른 말로하면 모델이 단순히 훈련 데이터를 모두 외워버린게 아닌지 또는 새로 처음 본 데이터에 잘 일반화 되었는지를 말할 수 없습니다.(다시말해 훈련 정확도와 테스트 정확도의 차이인 편향을 낙관적으로 추정하게 됩니다)
전형적으로 데이터셋을 훈련 세트와 테스트 세트로 나누는 것은 간단한 랜덤 서브샘플링random subsampling입니다. 모든 데이터는 동일한 확률 분포(각 클래스에 대해)로 부터 추출된다고 가정합니다. 이 샘플의 2/3 정도를 훈련 세트로 하고 1/3을 테스트 세트로 합니다. 그런데 여기에 두 가지 문제가 있습니다.
계층 샘플링
우리가 가진 데이터셋은 어떤 확률 분포에서 추출한 랜덤 샘플이라는 것을 기억하세요. 즉 이 샘플이 진짜 분포를 어느정도 대표한다고 가정합니다. 이 데이터셋을 중복없이 다시 샘플링4하면 샘플의 통계(평균, 비율, 분산)가 변경됩니다. 중복없는 서브샘플링subsampling이 통계에 미치는 정도는 샘플의 사이즈에 반비례합니다. Iris 데이터셋을 이용해 예를 들어 보겠습니다. 랜덤하게 2/3 은 훈련 데이터로 1/3 은 테스트 데이터로 나눕니다.

(소스 코드는 여기에서 확인할 수 있습니다)
데이터셋을 훈련 세트와 테스트 세트로 랜덤하게 나눌 때 통계적 독립성statistical independence의 가정을 위반하고 있습니다. Iris 데이터셋은 50개의 Setosa, 50개의 Versicolor, 50개의 Virginica 품종으로 구성되어 있습니다. 즉 꽃의 품종이 균일하게 분포되어 있습니다.
- 33.3% Setosa
- 33.3% Versicolor
- 33.3% Virginica
랜덤 함수가 붓꽃의 2/3을 (100개) 훈련 세트로 1/3을 (50개) 테스트 세트로 나눌 때 아래와 같은 분포를 만들었습니다.
- 훈련 세트 → 38 × Setosa, 28 × Versicolor, 34 × Virginica
- 테스트 세트 → 12 × Setosa, 22 × Versicolor, 16 × Virginica
Iris 데이터셋이 진짜 분포를 대변한다고 가정하면 (예를 들어 자연에서 이 세 품종이 균일하게 분포되어 있다고 가정하면), 우리는 불균형한, 즉 균일하지 않은 클래스 분포를 가진 데이터를 만든 셈입니다. 학습 알고리즘이 모델을 학습시키기 위해 사용할 클래스 비율은 “38% / 28% / 34%” 입니다. 그런 다음 모델을 평가할 때에 사용할 데이터셋은 거꾸로 불균형한 “24% / 44% / 32%” 의 클래스 비율을 가집니다. 학습 알고리즘이 이런 불균형에 완전히 무감하지 않는한 바람직한 상황이 아닙니다. 데이터셋의 클래스 불균형이 커지면 문제는 더 심각해 집니다. 최악의 경우 테스트 세트에는 소수 클래스의 샘플이 하나도 들어 있지 않을 수도 있습니다. 그러므로 데이터셋을 나눌때 계층적stratified 방식이 일반적인 관례입니다. 계층 샘플링stratification은 각 클래스가 훈련 세트와 테스트 세트에 정확하게 분포되도록 데이터셋을 랜덤하게 나눕니다.
아주 크고 균형있는 데이터셋에서 비계층적non-stratified 방식을 사용해 랜덤 서브샘플링random subsampling하는 것은 큰 문제되지 않습니다. 그러나 개인적으로 계층 샘플링은 머신 러닝 애플리케이션에 일반적으로 도움이 됩니다. 더군다나 계층 샘플링은 매우 쉽게 구현할 수 있습니다. Ron Kohavi는 계층 샘플링이 이 글의 뒷 부분에 설명할 k-겹 교차 검증k-fold cross validation에서 추정치의 분산과 편향에 긍정적인 효과를 준다는 것을 입증하였습니다.(Kohavi 1995)
홀드아웃
홀드아웃 검증 방법의 장단점으로 들어가기 전에 전체 과정을 그림으로 요약해 보겠습니다.

① 첫번째 단계에서, 가용 데이터를 훈련 세트와 테스트 세트 두 부분으로 랜덤하게 나눕니다. 테스트 데이터를 따로 두는 것은 데이터나 리소스 부족같은 현실적인 문제와 더 많은 데이터를 모을 수 없을 때를 위한 해결책입니다. 테스트 세트는 학습 알고리즘을 위한 새로운, 본 적이 없는 데이터의 역할을 합니다. 일반화 정확도를 추정할 때 어떤 편향도 만들지 않도록 테스트 세트는 한 번만 사용해야 합니다. 보통 2/3을 훈련 세트로, 1/3을 테스트 세트로 만듭니다. 다른 경우엔 훈련/테스트 비율을 60/40, 70/30, 80/20 또는 90/10으로 할 때도 있습니다.

② 테스트 샘플을 떼어 놓은 후에 주어진 문제에 적합한 학습 알고리즘을 고릅니다. 위 그림에 나타난 Hyperparameter Values 가 무엇일까요? 간단하게 소개하면 하이퍼파라미터는 학습 알고리즘의 파라미터 또는 메타 파라미터입니다. 하이퍼파라미터는 수동으로 지정해야 합니다. 학습 알고리즘은 모델 파라미터와는 달리 훈련 데이터로부터 하이퍼파라미터를 학습할 수 없습니다.
하이퍼파라미터는 모델이 학습하는 동안 학습되지 않기 때문에 이들을 별도로 최적화하기 위한 추가적인 과정 또는 외부 루프5가 필요합니다. 홀드아웃 방식은 이 작업에는 적합하지 않습니다. 여기서는 어떤 고정된 하이퍼파라미터를 사용해 진행합니다. 직관에 따라 정할 수도 있고 또는 머신 러닝 라이브러리를 사용한다면 알고리즘에 내장된 기본값을 사용할 수도 있습니다.

③ 학습 알고리즘이 이전 단계에서 모델을 학습시켰습니다. 다음 질문은 “이 모델이 얼마나 좋은가?”입니다. 이제 테스트셋이 사용될 차례입니다. 알고리즘은 이전에 테스트 세트를 본 적이 없으므로 새로운 처음 본 데이터에 대해 편향되지 않는 성능 추정을 합니다. 그러므로 해야 할 일은 모델을 사용해 테스트 세트의 클래스 레이블을 예측하는 것입니다. 그런 다음 일반화 성능을 추정하기 위해 예측된 클래스 레이블과 진짜 레이블을 비교를 합니다.

④ 결국 우리는 새로운 데이터에 대해 모델이 얼마나 잘 작동하는지 추정했습니다. 그러므로 더 이상 테스트 데이터를 따로 떼어 놓을 필요가 없습니다.
우리는 샘플이 독립적이고 동일한 분포를 가진다고 가정했으므로 가용한 모든 데이터를 주입한다고 해서 모델의 성능이 더 나빠질 이유가 없습니다. 통상적으로 모델의 성능이 한계치에 이르기 전에는 알고리즘에 유용한 데이터를 더 제공할수록 일반화 성능은 좋아집니다.

비관적인 편향
훈련 세트와 테스트 세트를 나누는 것에 대해 이야기할 때 언급한 두가지 문제를 기억하나요? 첫번째 문제는 독립성의 위반과 서브샘플링으로 인한 클래스 비율의 변화입니다. 두번째 문제는 홀드아웃 그림을 살펴 보면서 다루었습니다. 네번째 단계에서 모델의 성능 한계에 대해 이야기했고 추가 데이터가 유용할지 안할지 이야기했습니다. 성능 한계 이슈를 따라가 보면, 우리 모델이 성능 한계에 도달하지 않았을 경우 성능 추정은 비관적으로 편향되어 있을 수 있습니다. 알고리즘이 더 많은 데이터로 나은 모델을 학습시킬 수 있다고 가정하면, 일반화 성능을 재기위해 떼어 놓았던 (예를 들면 테스트 데이터) 가용한 데이터를 가로막고 있던 셈입니다. 네번째 단계에서 완전한 데이터셋으로 모델을 학습시킵니다. 그러나 테스트 데이터셋을 사용했기 때문에 일반화 성능을 추정할 수 없습니다. 실제 애플리케이션에서는 피할 수 없는 딜레마로 일반화 성능의 추정은 비관적으로 편향되어 있다는 것을 인지해야 합니다.
신뢰구간
위에서 사용한 홀드아웃 방법을 사용하면 모델의 일반화 정확도에 대한 점추정point estimate를 계산한 것입니다. 어떤 애플리케이션에서는 이 추정치 근방의 신뢰 구간confidence interval이 더 유용하고 필요할 뿐만 아니라 특정한 훈련/테스트 세트 묶음에 점추정이 민감할 수도 있습니다(즉 분산이 큰 경우).
실전에서 자주 사용되는 (하지만 저는 추천하지 않습니다) 다른 간단한 방법은 정규 분포Normal Distribution를 가정한 친숙한 공식을 사용하여 중심 극한 정리central limit theorem로 하나의 훈련, 테스트 분할로 만든 평균의 신뢰 구간을 계산하는 것입니다.
확률 이론에서 중심 극한 정리(CLT)란 주어진 조건하에서 잘 정의된 기대값, 분산으로 독립 확률 변수를 충분히 많이 반복하여 계산한 산술 평균은 실제 데이터 분포에 상관없이 정규 분포에 가깝다는 것을 말합니다. [https://en.wikipedia.org/wiki/Central_limit_theorem]
이 단순한 방식을 정규 근사 구간normal approximation interval이라고 부릅니다. 어떻게 작동하는 것일까요? 예측 정확도는 다음과 같이 계산합니다.
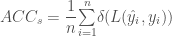
여기서 L(·) 은 0-1 손실 함수이고 n 은 테스트 세트에 있는 샘플의 수, 
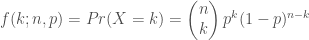
k = 0, 1, 2, …, n 일 때

(p 는 성공 확률이고 (1 – p) 는 실패 확률-잘 못된 예측-입니다)
이제 예상되는 성공 횟수는 μ = np 로 계산되므로 예측기가 50% 성공 확률을 가진다면 40개의 예측에서 20개를 맞출 것입니다. 성공 횟수에 대한 추정은 σ2 = np(1 – p) = 10 분산을 가지고, 표준 편차는
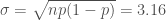
입니다. 그런데 우리는 정확한 값이 아니라 성공의 평균 횟수에 관심이 있으므로 정확도 추정의 분산을 다음과 같이 계산합니다.7
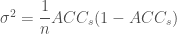
이에 대응하는 표준 편차는

정규 분포로 근사하면 신뢰 구간을 아래와 같이 쓸 수 있습니다.

여기에서 α 는 에러의 분위quantile를 나타내고 z 는 표준 정규 분포의 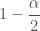
그러나 실제적으로 훈련-테스트 세트를 여러번 분할해서 만든 평균 추정치(각 반복 결과의 평균)로 신뢰 구간을 계산하는 것을 추천합니다. 여기에서 기억해야 할 것은 테스트 세트에 샘플 수가 적으면 분산이 커지고(n 이 분수의 분모이므로) 따라서 신뢰 구간의 폭이 넓어진다는 것입니다.
다음에는
전체 글이 꽤 장문이므로 여러 파트로 나누었습니다. 다음에는 아래 내용에 대해 이야기 하겠습니다.
- 모델링 불확실성을 위한 반복 홀드아웃 검증과 부트스트랩 방법 (2장)
- 하이퍼파라미터 튜닝을 위한 홀드아웃 방법 – 데이터셋의 훈련, 테스트, 검증 세트 분할 (3장).
- K-겹 교차 검증: 모델 선택의 유명한 방법 (3장).
- Nested cross-validation, probably the most common technique for model evaluation with hyperparameter tuning or algorithm selection. (Part IV).
참고문헌
- Kohavi, R., 1995. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Ijcai (Vol. 14, No. 2, pp. 1137-1145). [Citation source] [PDF]
- Efron, B. and Tibshirani, R.J., 1994. An introduction to the bootstrap. CRC press. [Citation source] [PDF]
(역주)
- 디렉 델타 함수는 일종의 이산 함수로 크로네커 델타 함수Kronecker Delta Function와 동일한 의미로 많이 사용됩니다. 즉 손실 함수 L(·) 이 0일 때 델타 함수 값이 1이 되고 그 외에 델타 함수 값은 0입니다.
- 기대값
- 여기서 말하는 편향은 머신 러닝에서 흔히 말하는 선형 모델에 추가되는 상수항을 의미합니다.
- 중복없이 샘플링한다는 것은 샘플링 과정에서 추출한 샘플은 다시 원본 데이터셋에 돌려놓지 않는다는 뜻으로 서브샘플링으로 추출한 데이터에는 동일한 샘플이 중복되어 들어가 있지 않습니다.
- 하이퍼파라미터를 최적화하려면 코드의 바깥쪽 루프에서 하이퍼파라미터 셋팅을 바꾸어 가며 k-폴드 크로스밸리데이션을 반복해서 수행해야 합니다. 파이썬 머신 러닝 라이브러리인 사이킷런scikit-learn에서는 이를 위해
GridSearchCV와 같은 클래스를 제공합니다. - 이항분포 공식은 이산적인 이벤트가 여러번 일어났을 때 성공, 실패의 확률
와 성공, 실패가 나타난 조합의 수
를 곱합니다.
- CLT를 적용하려고 앞의 표준편차 공식을 n 으로 나누어 평균을 내고 제곱을 하여 분산을 계산합니다.
- CLT에서 정규분포의 양끝 꼬리의 에러 분위를 고려해야 하므로
의 표준점수 z 는 1.96입니다.

내용 잘 보고 있습니다만 이대로는 이해하기 어렵지 않나 하는 생각이 듭니다. 새로 나온 용어들의 정의가 한 곳에 정리되어 있으면 좋겠습니다. 거의 직역을 한 것 같은데 무슨 뜻인지 알기 어렵습니다. 예를 들어 “훈련 정확도와 테스트 정확도의 차이인 편향을 낙관적으로 추정하게 됩니다” 말의 뜻이 무엇입니까? 낙관적이란 말이 훈련 정확도와 테스트 정확도가 일치하게 나온다는 뜻인지 아니면 또 다른 뜻 예를 들어 그냥 좋다는 뜻인지. 낙관적이란 말은 인문학적인 용어로서 이런 과학적인 문서에 적합한 단어인지 모르겠습니다. 단어들이 보다 정확했으면 좋겠습니다. 그냥 테스트 정확도가 훈련 정확도와 매우 일치하게 나오는 경향이 있다 서술하는게 낫지 않을까요?
좋아요좋아요
안녕하세요. 낙관적인 추정은 우호적으로 테스트 세트의 성능을 평가한다는 의미입니다. 실제로는 성능이 더 나쁠 가능성이 높겠죠. 공식화된 용어는 아니지만 제가 즐겨 쓰고 머신 러닝 분야에서도 종종 접할 수 있는 표현입니다. 감사합니다.
좋아요좋아요
과대적합overfitting으로 인해 편향이 매우 감소한다라고 나와있는데, 예측값과 실제값의 차이가 거의 없다는 말 아닌가요? 성능이 나쁘다기 보단 재치환 테스트로 인한 낙관적 편향은 모델의 성능 추정하기엔 무리가 있다는 말 같은데요. 아예 다른 통계를 가진 테스트 세트를 예측한다면 엉뚱한 결과가 나올 수도 있어서요.
좋아요좋아요
위 그래프를 보니 과대적합일때는 일반화 정확도가 나쁘다고 나와있네요. 그러니까 훈련 세트와 다른 통계를 가진 테스트 세트를 예측하여 정확도를 측정하면 모델의 성능이 떨어지는게 맞는 말이군요.
좋아요좋아요
안녕하세요.
본문 읽다가 질문이 있어 드립니다.
본 챕터 제일 뒤에 추정 성능을 유도하는 부분에 alpha 에 대한 설명이 나오는데요.
본문에서는 alpha 가 언급된 것을 찾기가 어려워서 어떤 맥락에서 나온 변수인지 궁금합니다.
좋아요좋아요
alpha는 α 를 말합니다. 🙂
좋아요좋아요
네 어떤 식에서 α 가 사용되었나요?
좋아요좋아요
바로 위 문장에 설명되어 있습니다. “여기에서 α 는 에러의 분위quantile를 나타내고 z 는 표준 정규 분포의 1 – \dfrac{\alpha}{2} 분위를 나타냅니다.”
좋아요좋아요
“여기에서” 라고 하여 그 문장 앞의 식들 중에 α가 언급된 것으로 착각했네요.
설명 감사합니다.
좋아요Liked by 1명
안녕하세요 머신러닝 지도학습 알고리즘을 파이썬으로 공부하는 학생입니다.
다양한 알고리즘의 정확성과 함께, 적합한 모델인지 아닌지 확인할 수 있는 기준이 있나요?
제가 생각할때 훈련데이터의 정확성과 테스트데이터의 정확성이 표준편차 범위 안에 들어오면 적합하다고 보는데 맞나요?
좋아요좋아요
안녕하세요. 정확성 외에도 정밀도, f1 점수 등 다양한 분류 지표가 있습니다. 일반적으로 복잡도를 조절하면서 최적의 모델을 찾습니다. 정량화된 일반적인 규칙은 없습니다. 감사합니다.
좋아요좋아요