이 글은 파이썬 머신 러닝의 저자 세바스찬 라쉬카(Setabstian Raschka)가 쓴 ‘Model evaluation, model selection, and algorithm selection in machine learning Part IIII – Cross-validation and hyperparameter tuning‘를 원저자의 동의하에 번역한 것입니다. 이 시리즈 글의 전체 번역은 Model evaluation, selection and algorithm selection에 있습니다.
소개
대부분의 머신러닝 알고리즘에는 연구자나 기술자들이 지정해야 할 설정들이 많습니다. 이런 튜닝 옵션을 하이퍼파라미터hyperparameter라고 부르며 성능을 최적화하거나 편향bias과 분산variance 사이의 균형을 맞출 때 알고리즘을 조절하기 위해 사용됩니다. 성능 최적화를 위해 하이퍼파라미터를 튜닝하는 것은 그 자체로 예술적인 일이며 어떤 데이터셋에서 최고의 성능을 보장하는 쉽고 빠른 길은 없습니다. 1장과 2장에서 모델의 일반화된 성능을 추정하기 위해 홀드아웃holdout과 부트스트랩bootstrap 기법을 보았습니다. 편향-분산의 트레이드오프bias-variance trade-off에 관해 배웠고 추정치의 불확실성을 계산했습니다. 이번 장에서 모델 평가와 모델 선택을 위한 교차 검증cross validation의 다른 방법을 살펴보겠습니다. 여러가지 다른 하이퍼파라미터 설정을 가진 모델의 순위를 매기고 별도의 테스트 데이터셋에 얼마나 잘 일반화되는지 추정하기위해 교차 검증 기법을 사용하겠습니다.
하이퍼파라미터와 모델선택
이전에 우리는 홀드아웃과 부트스트래핑을 사용하여 예측 모델의 일반화 성능을 추정했습니다. 데이터셋을 훈련 세트와 테스트 세트 두 부분으로 나누었습니다. 머신러닝 알고리즘이 훈련 세트로 모델을 학습시킨 후에 학습에 사용되지 않은 별도의 테스트 세트로 모델을 평가했습니다. 편향-분산 트레이드오프 같은 문제들에 관해 이야기할 때 학습 알고리즘에 고정된 하이퍼파라미터 설정을 사용했습니다. k-최근접 이웃k-nearest neighbors 알고리즘의 k 같은 값입니다. 하이퍼파라미터는 모델 학습 전에 미리 지정해야 하는 학습 알고리즘이 자체적으로 가지고 있는 파라미터입니다. 반대로 만들어진 모델의 파라미터를 모델 파라미터라고 합니다.
그렇다면 정확히 하이퍼파라미터가 무엇인가요? k-최근접 이웃 알고리즘에서는 정수값 k 가 하나의 하이퍼파라미터입니다. k=3 으로 지정하면 k-최근접 이웃 알고리즘이 훈련 세트에 있는 세개의 가장 가까운 이웃으로 다수결 투표를 해서 클래스 레이블을 예측합니다. 가장 가까운 이웃을 찾는 거리 측정 방식은 알고리즘에 있는 또 다른 하이퍼파라미터입니다.

k-최근접 이웃 알고리즘이 하이퍼파라미터와 모델 파라미터의 차이를 설명하는데 아주 적합하지 않을지 모릅니다. 이 알고리즘은 게으른 학습기lazy learner이고 비모수적nonparametric 방법이기 때문입니다. 여기에서 게으른 학습(또는 사례 기반instance-based 학습)이란 훈련이나 모델 학습 단계가 없다는 것을 의미합니다. k-최근접 이웃 모델은 말 그대로 훈련 데이터를 저장, 기억하고 예측 시에 사용만합니다. 그러므로 각 훈련 샘플이 k-최근접 이웃 모델에 있는 하나의 파라미터가 됩니다. 요약하면, 비모수적 모델은 훈련 세트에 맞추어 한정된 수의 파라미터로 기술할 수 없는 모델입니다. 비모수적 모델 구조는 사전에 정의되는 것이 아니고 훈련 데이터에 의해 결정됩니다. 비모수적 모델은 모수적parametric 모델과 달리 데이터가 어떤 확률 분포를 따른다고 가정 하지 않습니다(이런 가정의 예외적인 비모수적 방식은 베이지안 비모수 방법Bayesian nonparametric method입니다). 그러므로 비모수적 방식이 모수적 방식보다 데이터에 적은 가정을 한다고 말합니다.
k-최근접 이웃과 반대인 모수적 모델의 간단한 예는 로지스틱 회귀logistric regression입니다. 이 모델은 데이터셋에 있는 특성 변수마다 하나의 가중치 계수weight coefficient와 편향1(또는 절편) 같이 한정된 모델 파라미터를 가진 일반적인 선형 모델입니다. 로지스틱 회귀의 가중치 계수, 즉 모델 파라미터는 로그 가능도 함수log likelihood function를 최대화하거나 로지스틱 비용을 최소화시키는 방향으로 업데이트됩니다. 그래디언트gradient 기반의 최적화로 훈련 데이터에 모델을 학습시키는 경우, 훈련 세트의 반복 횟수 또는 에포크epoch가 로지스틱 회귀 알고리즘의 하이퍼파라미터가 됩니다. 또 다른 하이퍼파라미터는 L2-규제 로지스틱 회귀에서 람다lambda 항2 같은 규제 파라미터입니다:

훈련 세트에 학습 알고리즘을 적용할 때 하이퍼파라미터 값을 바꾸면 다른 모델이 만들어집니다. 서로 다른 하이퍼파라미터 설정으로 만들어진 모델중에서 가장 성능이 높은 모델을 찾는 과정을 모델 선택model selection이라고 합니다. 다음 섹션에서 이런 선택 과정에 도움이 되는 확장된 홀드아웃 방법을 살펴보겠습니다.
하이퍼파라미터 튜닝을 위한 3방향 홀드아웃 방법
1장에서 재치환resubstitution 검증은 일반화 성능을 추정하는데 나쁜 방법이라는 것을 배웠습니다. 새로운 데이터에 모델이 얼마나 잘 일반화 되는지를 알고 싶기 때문에 데이터셋을 훈련 데이터와 테스트 세트로 나누는 홀드아웃 방법을 사용했습니다. 하이퍼파라미터 튜닝을 위해 홀드아웃 방법을 사용할 수 있을까요. 대답은 “네!”입니다. 하지만 이전에 사용한 2방향two-way 분할을 조금 바꿔서 훈련training, 검증validation, 테스트test 세트 3가지로 데이터셋을 나누어야 합니다.
하이퍼파라미터 튜닝과 모델 선택 과정을 메타 최적화meta-optimization 작업으로 볼 수 있습니다. (게으른 학습기를 제외하고는) 학습 알고리즘이 목적 함수를 훈련 세트에서 최적화하는 반면, 하이퍼파라미터 최적화는 그 위에 있는 또 다른 작업입니다. 전형적으로 분류 정확도나 ROCReceiver Operating Charateristic 곡선 아래의 면적을 성능 지표로 하여 최적화합니다. 튜닝 단계 후에 테스트 세트 성능에 기반하여 모델을 선택하는 것이 적절한 방법처럼 보일 수 있습니다. 하지만 테스트 세트를 여러번 재사용하면 편향에 영향을 미치고 과대하게 낙관적으로 일반화 성능을 추정하게 됩니다. 이럴 때 “테스트 세트의 정보가 새어 나갔다”라고 말합니다. 이런 문제를 피하기 위해 데이터셋을 훈련, 검증, 테스트 데이터셋 3가지로 나눕니다. 하이퍼파라미터 튜닝과 모델 선택을 위해 훈련, 검증 세트를 사용하고 테스트 세트는 모델 평가를 위해 별도로 유지합니다. 성능 추정의 세가지 목적을 기억하시나요?
- 미래 (보지 못한) 데이터에 대한 모델의 예측 성능인 일반화 정확도를 추정하려고 합니다.
- 학습 알고리즘 튜닝하고 주어진 가설 공간으로부터 가장 성능이 뛰어난 모델을 선택해서 예측 성능을 증가 시키려고 합니다.
- 문제에 가장 적합한 머신러닝 알고리즘을 찾으려고 합니다. 그러므로 여러가지 알고리즘을 비교하고 알고리즘의 가설 공간에서 가장 성능이 좋은 모델은 물론 가장 가장 성능이 좋은 알고리즘을 선택하려고 합니다.
“3방향three-way 홀드아웃 방법”은 1번과 2번을 다루기 위한 한가지 방법입니다(3번 항목은 다음 글인 4장에서 살펴보겠습니다). 하지만 우리가 가장 성능이 좋은 모델을 고르는 2번에만 관심이 있고 편향되지 않은 일반화 성능을 추정하는데 관심이 없다면, 모델 선택에서 2방향 분할만 사용하면 됩니다. 2장에서 보았던 학습 곡선과 비관적 편향에 대해 얘기했던 것을 떠올려보면, 머신러닝 알고리즘은 레이블 된 데이터가 더 많을 때 효과를 봅니다. 데이터셋이 작을수록 비관적 편향과 분산이 증가됩니다. 즉 데이터를 나누는 방식에 따라 모델이 매우 민감해집니다.
“세상에 공짜 점심은 없습니다.” 하이퍼파라미터 튜닝과 모델 선택을 위한 3방향 홀드아웃 방법이 이 문제를 해결하기 위한 유일한 방법도 아니고 종종 최선의 방법도 아닙니다. 다음 섹션에서 대안적인 방법과 그들의 장점과 트레이드오프에 대해서 배우겠습니다. 아마도 모델 선택에서 가장 인기있는 방법인 k-겹 교차 검증k-fold cross-validation(예전에는 회전 평가rotation estimation라고도 불렀습니다)으로 넘어가기 전에, 3-방향 홀드아웃 방법의 그림을 한번 보겠습니다.
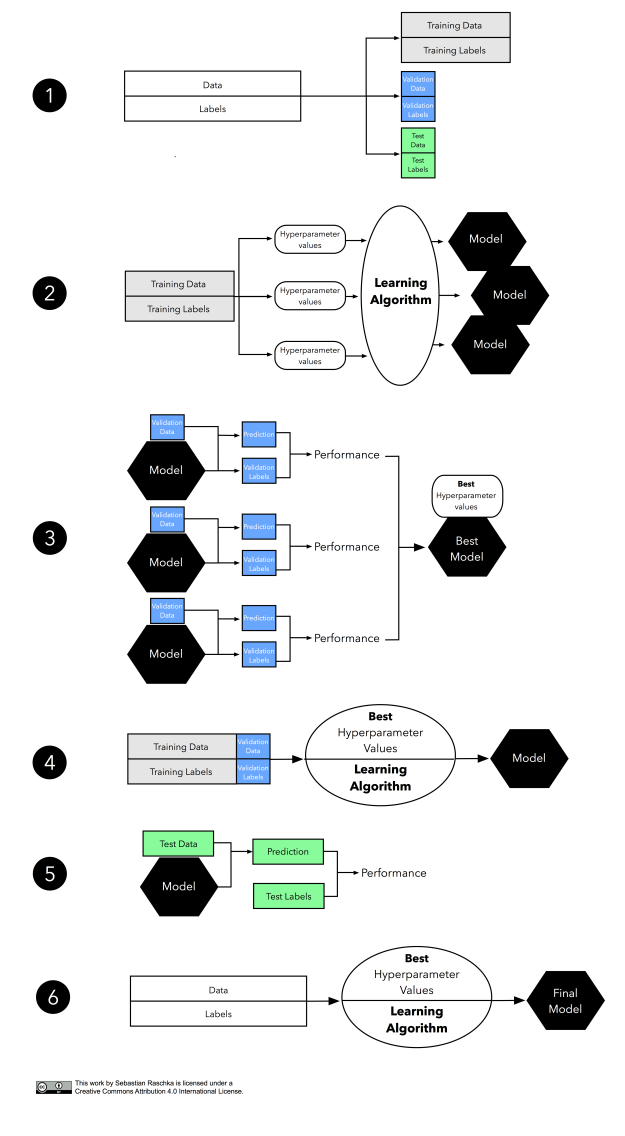
그림이 꽤 길기 때문에 단계별로 살펴보도록 하겠습니다

데이터셋을 먼저 모델 학습을 위한 훈련 세트와 모델 선택을 위한 검증 세트, 최종 선택된 모델을 평가하기 위한 테스트 세트, 3개 부분으로 나눕니다.

두 번째는 하이퍼파라미터 튜닝 단계를 보여줍니다. 학습 알고리즘을 사용하여 여러가지 (여기서는 세가지) 하이퍼파라미터 세팅으로 훈련 데이터에 모델을 학습시킵니다.

다음은 검증 세트로 모델의 성능을 평가합니다. 이 단계는 모델 선택 단계를 보여 줍니다. 성능 추정을 비교한 후에 가장 성능이 좋은 하이퍼파라미터 설정을 선택합니다. 실제로는 두 번째와 세 번째 단계를 함께 사용하는 경우가 많습니다. 학습된 모델을 메모리에 모두 유지하지 않으려고 다음 모델을 만들기 전에 학습시킨 모델의 성능을 계산합니다.
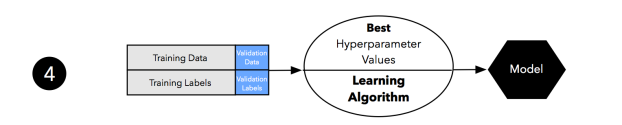
1장과 2장에서 논의한 것처럼 훈련 세트가 너무 작으면 추정값에 비관적 편향에 영향을 받습니다. 그러므로 모델 선택 후에 훈련 세트와 검증 세트를 합쳐 좀 더 큰 데이터셋으로 이전 단계에서 얻은 최선의 하이퍼파라미터 설정을 사용하여 모델을 학습시킵니다.

이제 모델의 일반화된 성능을 조정하기 위해 별도의 테스트 세트를 사용합니다. 테스트 세트의 목적은 모델이 이전에 본 적이 없는 새로운 데이터의 역할을 흉내내는 것입니다. 테스트 세트를 재사용하면 모델의 일반화된 성능 추정에 과하게 낙관적인 편향을 만들게 됩니다.

마지막으로 훈련 세트와 테스트 세트를 합쳐 전체 데이터를 사용해 실제 운영 환경에 사용할 모델을 학습시킵니다.
K-겹 교차 검증
실전 머신 러닝에서 모델 평가와 모델 선택을 위해 가장 널리 사용되는 기법인 k-겹 교차 검증을 소개할 차례입니다. 기술자나 연구자들이 훈련/테스트 홀드아웃 방법도 교차 검증이란 용어로 이따금씩 표현하곤 합니다. 그러나 교차 검증은 연속적으로 훈련과 검증 단계를 교차시키는 것으로 생각하는 것이 더 낫습니다. 교차 검증 이면의 주요 아이디어는 데이터셋에 있는 모든 샘플이 테스트될 기회를 갖도록 하는 것입니다. K-겹 교차 검증은 데이터셋을 k 번 반복하는 교차 검증의 특별한 케이스입니다. 각 반복에서 데이터셋을 k 개의 부분으로 나눕니다. 모델 평가를 위해 한 부분은 검증으로 사용되고 나머지 k-1 부분은 훈련용 서브셋으로 합쳐져서 사용됩니다. 아래 그림은 5-겹 교차 검증의 과정을 나타냅니다.

2방향 홀드아웃 방법처럼 모델 평가를 위해 k-겹 교차 검증을 사용한다면, 학습 알고리즘이 매 반복에서 고정된 하이퍼파라미터 설정으로 훈련 폴드를 사용해 모델을 학습시킵니다. 5-겹 교차 검증에서 이 과정은 학습된 5개의 다른 모델을 만듭니다. 이 모델을 학습할 때 사용한 훈련 세트는 부분적으로 겹쳐져 있으며, 평가는 중복되지 않은 검증 세트를 사용 합니다. 결국 검증 세트로부터 구한 k 개의 성능 추정을 산술 평균하여 교차 검증 성능을 계산합니다.
2방향 홀드아웃 방식과 k-겹 교차 검증 간의 주요한 차이점을 보았습니다. k-겹 교차 검증은 훈련과 테스트를 위해 모든 데이터를 사용합니다. 이 방식 이면에 있는 아이디어는 테스트 데이터를 위해 데이터셋에서 비교적 큰 부분을 따로 떼어 놓지 않고 많은 훈련 데이터를 사용하여 비관적 편향을 감소시키려는 것입니다. 2장에서 보았던 반복적인 홀드아웃 방법과 다른 점은 k-겹 교차 검증의 테스트 폴더는 중첩되지 않는다는 것입니다. 반복적인 홀드아웃 방법에서 테스트를 위해 샘플 데이터를 재사용하는 것은 반복 과정 사이의 독립적인 성능 추정을 만들어내지 못합니다. 이런 의존성은 4장에서 논의할 통계적인 비교에 문제가 될 수 있습니다. 또한 k-겹 교차 검증은 모든 샘플이 검증에 활용된다는 것을 보장하지만 반복적인 홀드아웃 방법은 일부 샘플이 테스트 세트에 포함되지 않을 수 있습니다.
이번 섹션에서 모델 평가를 위한 k-겹 교차 검증을 소개했습니다. 하지만 실제로는 k-겹 교차 검증이 모델 선택과 알고리즘 선택에 더 많이 사용되고 있습니다. 모델 선택을 위한 k-겹 교차 검증은 이 글의 후반부에 다루겠습니다. 알고리즘 선택에 관해서는 다음 글인 4장에서 더 자세히 다루겠습니다.
특별 사례: 2-겹 교차 검증과 Leave-One-Out 교차 검증
이 시점에서 이젠 섹션에 있는 k-겹 교차 검증 예시에서 왜 k=5 를 선택했는지 궁금해 할 수 있습니다. 한가지 이유는 k-겹 교차 검증을 간단하게 설명하기 쉽기 때문입니다. 더군다나 k=5 는 큰 k 값에 비해 연산 비용이 크지 않기 때문에 실제로 자주 사용되는 값입니다. k가 너무 작으면 추정값의 비관적 편향이 증가되고(모델 학습에 더 적은 훈련 데이터가 사용되기 때문에), 데이터를 어떻게 분할하느냐에 모델이 더 민감해지기 때문에 추정의 분산도 증가될 것입니다(나중에 k=10 이 좋은 선택임을 알려주는 연구에 대해 알아보겠습니다).
사실 두 개의 유명한, 그리고 특별한 k-겹 교차 검증의 사례가 있습니다. k=2 와 k=n 입니다. 대부분의 글에서는 2-겹 교차 검증을 홀드아웃 방법과 같은 것으로 이야기합니다. 하지만 이 말은 홀드아웃 방법이 훈련과 검증 세트를 바꾸어 2번 반복될 경우에만 맞습니다(예를 들어 정확히 50% 데이터를 훈련용으로 사용하고 50%를 검증용으로 사용하고, 이 두 세트를 바꾼 다음 훈련과 검증 과정을 반복합니다. 결국 검증 세트에 대한 두 성능 추정의 산술평균으로 성능 추정을 계산합니다). 홀드아웃 방법이 대부분 보편적으로 널리 사용되지만 저는 홀드아웃 방법과 2-겹 교차 검증을 아래 그림과 같이 다른 프로세스로 나타내는 것을 선호합니다:

이제 k=n 일 때, 즉 폴드의 수를 훈련 샘플의 수와가 같게 했을 때 k-겹 교차 검증 과정을 LOOCVLeave-One-Out cross-validation라고 합니다. LOOCV의 각 반복에서는 데이터셋에 있는 n-1 개의 샘플로 모델을 학습 시키고 남아 있는 하나의 데이터 포인트로 모델을 평가합니다. 이런 프로세스는 n 번 반복 해야 하기 때문에 계산 비용이 많이 들지만, 훈련 세트에서 데이터를 떼어내는 것이 너무 큰 손실이 되는 작은 데이터셋에는 유용합니다.

몇가지 연구에서 k-겹 교차 검증의 k 값이 바뀔 때 추정값의 편향과 분산에 어떻게 영향을 미치는지 분석하여 비교하였습니다. 아쉽게도 요슈아 벤지오Yohsua Bengio 와 이브 그랜드발렛Yves Grandvalet이 “No unbiased estimator of the variance of k-fold cross-validation”에서 공짜 점심은 없다는 것을 보여 주었습니다.
핵심 정리theorem는 k-겹 교차 검증의 분산을 (모든 분포에서 통용되는) 편향없이 추정하는 보편적인 방법은 없습니다. (Bengio and Grandvalet, 2004)
그러나 대부분의 경우에 우리는 분산과 편향 사이에 적절한 절충점으로 보이는 최선의 지점을 찾는 것에 관심이 있습니다. 다음 섹션에서 편향-분산 트레이드오프에 대해 논의를 이어나가겠습니다. 여기서는 호킨스Hawkins와 다른 사람들이 LOOCV와 홀드아웃 방법을 사용해 성능 추정을 비교하고 연산 비용이 타당하다면 후자보다 LOOCV를 추천한 흥미로운 연구를 살펴보는 것으로 마치겠습니다.
[…] 샘플 사이즈가 중간 정도 규모일 때 모델 테스트를 위해 데이터를 떼어놓는 것은 권장되지 않습니다. 샘플을 이렇게 쪼개는 것은 모델 학습에 좋지 않으며 신뢰할만한 평가를 만들지 못합니다. 학습 단계에서 모든 데이터를 사용하고 올바르게 수행되는 교차 검증으로 체크하는 것이 맞습니다. […] 교차 검증보다 홀드아웃 샘플에 의존하는 유일한 경우는 교차 검증이 신뢰하지 못하다고 생각되는 이유가 있을 때-편향되어 있거나 변동이 클 때-입니다. 하지만 이론적인 결과나 경험적인 결과에서도 교차 검증 결과를 믿을 수 없다는 이유를 찾지 못했습니다. (Hawkins and others, 2003)
이 결론은 연구에서 469개의 샘플 데이터셋을 사용해 수행한 실험을 근거로 하고 있습니다. 다음 테이블은 각기 다른 릿지Ridge 회귀모델 비교해서 얻은 것을 요약한 것입니다.
| 실험 | 평균 | 표준편차 |
|---|---|---|
| true R2—q2 | 0.010 | 0.149 |
| true R2—hold 50 | 0.028 | 0.184 |
| true R2—hold 20 | 0.055 | 0.305 |
| true R2—hold 10 | 0.123 | 0.504 |
첫 번째와 네 번째까지 행에서 호킨스는 여러가지 모델 평가 방법을 비교하려고 백 개 샘플의 훈련 세트를 사용했습니다. 첫 번째 행은 연구자들이 LOOCV를 사용해서 회귀 모델을 100개 샘플의 훈련 서브세트로 학습시킨 실험의 결과입니다. 평균이 나타내는 것은 다른 100개 샘플의 훈련 세트로 이 과정을 반복한 후에 실제 결정 계수coefficiant of determination와 LOOCV를 통해서 얻은 결정 계수(여기서는 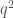
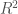
이 데이터 포인트의 3분의 1을 취하면 150개 정도의 데이터셋을 얻을 수 있습니다. 이를 랜덤하게 학습용으로 100개, 테스트용으로 50개 조금 넘게 분할할 수 있습니다. 그러나 이런 방법을 왜 써야 하는지 모르겠습니다.
홀드아웃 방법이 선호되는 한가지 이유는 데이터 셋이 충분히 클 경우 계산의 효율성 때문일 것입니다. 경험적으로 봤을 때 큰 용량의 데이터셋에서는 비관적 편향과 큰 분산을 걱정하지 않아도 됩니다. 더군다나 더 안정적인 추정을 얻으려고 랜덤 시드seed를 달리해서 k-겹 교차 검증 과정을 반복하는 것은 일반적이지 않습니다. 예를 들면 우리가 5-겹 교차 검증을 100번 반복한다면 500번 테스트 폴더의 성능 추정을 계산하고 500개 폴드의 산술 평균을 교차 검증 성능으로 리포트하게 됩니다(실제 일반적으로 사용되지만 여기서는 테스트 폴드가 겹쳐집니다). 그러나 LOOCV는 항상 같은 분할을 만들기 때문에3, LOOCV 반복에는 이런 점이 없습니다.
K와 편향-분산 트레이드오프
이전 섹션에서 보았던 실험 결과를 바탕으로 작거나 중간 규모의 데이터셋에서 홀드아웃 방법을 통한 하나의 훈련/테스트 분할 보다 LOOCV 방식이 나을 것 같습니다. 더군다나 LOOCV 추정은 거의 편향되지 않았다고 생각할 수 있습니다. 거의 모든(예를 들어, n-1) 훈련 샘플이 모델 학습에 사용되기 때문에 LOOCV(k=n)의 비관적 편향은 k<n-겹 교차 검증에 비해 당연히 낮습니다.
LOOCV가 거의 편향되지 않았지만 k<n 인 k-겹 교차 검증에 비해 LOOCV를 사용하는 한가지 단점은 LOOCV의 추정에 있는 큰 분산입니다. 분류에서 사용하는 0-1 손실 같은 불연속적인 손실 함수를 사용할 때나 평균 제곱 오차mean squared error같은 연속적인 손실 함수를 사용할 때도 마찬가지 입니다. 종종 LOOCV 는 다음과 같다고 이야기합니다.
테스트 세트가 하나의 샘플만 담고 있기 때문에 [LOOCV]는 분산이 큽니다. (Tan and others, 2005)
하나의 관측치(x1, y1)에 기반하기 때문에 [LOOCV]는 매우 변동이 심합니다. (Gareth and others, 2013)
폴드 간의 분산을 얘기할 때 이 문장들은 확실히 맞습니다. 0-1 손실 함수(예측에 맞았거나 틀렸거나)를 사용하면 각 예측은 베르누이 시행Bernoulli trial으로 간주할 수 있고 정확히 예측한 수 
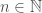
![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=444444&s=0&c=20201002)

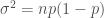
우리는 서브샘플subsample 간의 통계 변동량을 사용해 모델의 통계(여기서는 모델의 성능) 변동량을 추정할 수 있습니다. 하지만 폴더 간의 분산은 훈련 데이터에 있는 무작위성으로 인한 변동과 같아 확실히 LOOCV 추정값에 대한 분산은 좋지 않습니다. 여기서 LOOCV 분산에 관하여 이야기할 때, 어떤 분포로부터 여러번 샘플링하는 과정을 반복하여 얻은 결과의 차이를 의미합니다. 그래서 해스티Hastie, 팁쉬라니Tibshirani, 프리드만Friedman 이 더 흥미로운 점을 지적하였습니다:
K = N 이면, 교차 검증 추정은 진짜 (예상) 예측 에러에 대해 거의 편향되지 않습니다. 하지만 N 개의 훈련 세트가 서로 매우 비슷하기 때문에 높은 분산을 갖습니다. (Hastie and others, 2009)
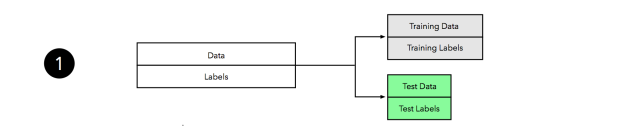
또는 다른 말로, 매우 연관되어 있는 변수들의 평균이 그렇지 않은 변수들의 평균값보다 높은 분산을 갖는다는 잘 알려진 사실로 높은 분산을 설명할 수 있습니다. 아마도 공분산covariance(cov)과 분산(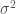

증명: 
![cov_{X,X}=E \left[(X-\mu)^2\right]=\sigma_X^2](https://s0.wp.com/latex.php?latex=cov_%7BX%2CX%7D%3DE+%5Cleft%5B%28X-%5Cmu%29%5E2%5Cright%5D%3D%5Csigma_X%5E2&bg=ffffff&fg=444444&s=0&c=20201002)
그리고 공분산 
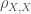
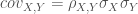
여기에서
![cov_{X,Y}=E\left[(X-\mu_X)(Y-\mu_Y)\right]](https://s0.wp.com/latex.php?latex=cov_%7BX%2CY%7D%3DE%5Cleft%5B%28X-%5Cmu_X%29%28Y-%5Cmu_Y%29%5Cright%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![\rho_{X,Y}=E\left[(X-\mu_X)(Y-\mu_Y)\right]/(\sigma_X \sigma_Y)](https://s0.wp.com/latex.php?latex=%5Crho_%7BX%2CY%7D%3DE%5Cleft%5B%28X-%5Cmu_X%29%28Y-%5Cmu_Y%29%5Cright%5D%2F%28%5Csigma_X+%5Csigma_Y%29&bg=ffffff&fg=444444&s=0&c=20201002)
입니다.
LOOCV에 연관된 큰 분산은 실증적 연구에서도 종종 관찰되어 왔습니다. 예를 들면 론 코하비Ron Kohavi가 쓴 아주 훌륭한 페이퍼 “A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection”(Kohavi, 1995)을 읽어 볼 것을 추천합니다.
이제 LOOCV 추정이 일반적으로 큰 분산과 작은 편향에 연관되어 있다는 것을 설명했습니다. 이 방식이 여러가지 k 값에 대한 k-겹 교차 검증이나 부스트랩 방법과 어떻게 비교할 수 있을까요? 2장에서 우리는 기본적인 부스트랩 방법의 비관적 편향을 설명했습니다. 훈련 세트는 근사적으로 원본 데이터셋의 0.6322 배수 샘플 만을 담고 있습니다. 그러므로 2 또는 3-겹 교차 검증은 같은 문제를 가지고 있습니다. 0.632 부트스트랩은 비관적 편향의 이슈를 다루기 위해 고안되었습니다. 하지만 모하비는 그의 연구(Kohavi, 1995)에서 부트스트랩의 편향이 특정 실제 데이터 세트에 대해 k-겹 교차 검증보다 여전히 매우 높다는 것을 관측했습니다(여기서는 낙관적인 편향). 결국 여러 종류의 실제 데이터 세트에 대한 코하비 실험은 10-겹 교차 검증이 편향과 분산 사이에 가장 좋은 절충점을 준다는 것을 보였습니다. 거기에 더해 여러 연구자들은 반복적인 k-겹 교차 검증이 편향을 작게 유지하면서 추정의 정확도를 증가시킨다고 밝혔습니다(Molinaro and others, 2005; Kim 2009).
모델 선택으로 넘어가기 전에 폴드의 수, k 를 증가시킬 때 나타나는 일반적인 경향을 나열함으로써 편향과 분산 트레이드오프에 대한 논의를 정리하겠습니다.
- 성능 추정에 대한 편향이 감소합니다 (더 정확해집니다)
- 성능 추정에 대한 분산은 증가됩니다 (더 많은 변동성)
- 연산 비용이 증가합니다 (반복이 늘어나고 학습할 훈련 세트가 큽니다)
- 예외: k-겹 교차 검증의 k 값을 작은 값으로 (예를 들면, 2 또 3) 감소시키면 랜덤 샘플링의 효과 때문에 작은 데이터셋에서 분산이 증가됩니다.
K-겹 교차 검증을 통한 모델 선택
이전에는 모델 평가를 위해 k-겹 교차 검증을 사용했습니다. 이제 더 나아가서 모델 선택을 위해 k-겹 교차 검증을 사용하겠습니다. 여기서도 핵심 아이디어는 훈련 단계에서 테스트 데이터를 누설하지 않으려고 훈련과 모델 선택에서 덜어놓은 테스트 데이터셋을 독립적으로 유지하는 것입니다.
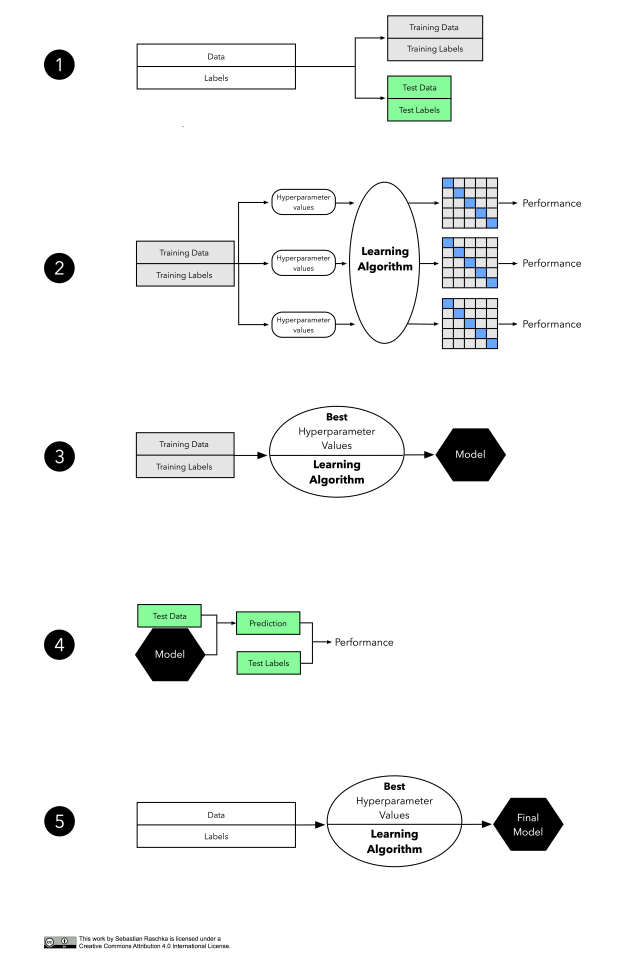
위 그림은 처음보면 조금 복잡해 보일 수 있지만 전체 과정은 매우 단순하고 이 글의 서두에서 이야기 했던 3방향 홀드아웃 워크플로우와 매우 유사합니다. 단계별로 살펴보겠습니다.
홀드아웃 방법과 비슷하게 데이터셋을 훈련과 독립적인 테스트 세트 두 부분으로 나눕니다. 최종 모델 평가 단계를 위해 테스트 세트는 따로 유지합니다.

두 번째 단계에서 여러가지 하이퍼파라미터 설정으로 실험을 할 수 있습니다. 베이지안 최적화Bayesian Optimization나 랜덤 서치Random Search, 일반적인 그리드 서치Grid Search를 사용할 수 있습니다. 각각의 하이퍼파라미터 설정에서 k-겹 교차 검증을 훈련 세트에 적용하고 여러 개의 모델을 만들어 성능을 추정합니다.

최고의 성능을 내는 모델의 하이퍼파라미터 설정을 선택해 모델 학습을 위해 전체 훈련 세트를 사용합니다.

이제 별도의 테스트 세트를 사용할 차례입니다. 이 테스트 세트를 단계 3에서 얻은 모델을 평가하기 위해 사용합니다.

마지막으로 평가 단계를 완료 했을때 모든 데이터로 소위 운영 모델이라 부르는 모델을 학습합니다.
딥러닝에 관한 글을 볼 때 종종 3방향 홀드아웃 방법이 모델 평가를 위해 선택되는 것을 볼 수 있습니다. 딥러닝 분야가 아닌 옛날 글에서도 자주 볼 수 있습니다. 위에서 언급했듯이 3방향 홀드아웃은 k-겹 교차 검증 보다 비교적 연산 비용이 저렴하기 때문에 선호됩니다. 연산의 효율성을 제외하고 비교적 큰 샘플 크기를 가지고 있을 때 딥러닝 알고리즘을 사용한다면, 데이터셋을 훈련, 검증, 테스트용으로 어떻게 분할하느냐에 따라 추정이 민감해지는 분산에 대해 걱정할 필요가 없습니다.
데이터 정규화normalize나 특성 선택은 일반적으로 데이터를 폴드로 나누기 전 전체 데이터셋에 적용하지 않고 k-겹 교차 검증 반복안에서 수행합니다. 교차 검증 안에서 특성 선택을 하면 훈련 단계에서 테스트 데이터 정보가 누수되는 것을 피할 수 있기 때문에 과대적합되어 편향을 감소시켜줍니다. 반면에 교차 검증 반복 밖에서 특성 선택을 하면 훈련에 더 적은 데이터가 사용되기 때문에 매우 비관적인 추정이 됩니다. 교차 검증 반복 안과 밖에서의 특성 선택에 관한 더 심도있는 논의에 대해서는 리파엘자데Refaeilzadeh의 “On comparison of feature selection algorithms”를 추천합니다. (Refaeilzadeh and others, 2007)
절약의 법칙
이전 섹션에서 모델 선택에 대해 이야기했습니다. 오캄의 면도날Occam’s Razor로 알려진 절약의 법칙Law of Parsimony에 대해 생각해 보겠습니다:
여러 개의 가설 중에서 가정이 가장 적은 것을 선택해야 한다.
또는 제가 가장 좋아하는 인용 중 하나인 다음과 같이 표현하기도 합니다:
“더 간단한 정도가 아니라 모든 것은 가능한 간단해야 한다” – 알버트 아인슈타인
실전 모델 선택에서 다음과 같은 1-표준 오차1-standard error 방법을 사용해 오캄의 면도날를 제공할 수 있습니다.
- 최적의 추정치과 표준오차를 계산한다.
- 1단계에서 얻은 값의 1-표준 오차 내에 성능을 가진 모델을 선택한다.(Breiman and others, 1984)
여러가지 이유로 더 간단한 모델이 선호됩니다. 페드로 도밍고Pedro Domingo는 복잡한 모델의 성능에 대해 좋은 지적을 했습니다. 다음은 그의 최근 글 “Ten Myths About Machine Learning”에서 발췌한 것입니다.
간단한 모델이 더 정확합니다. 이런 믿음은 가끔 오캄의 면도날과 동일시 되지만 면도날 이론은 더 간단한 설명이 좋다고 말하지만 왜 그런지는 말하지 않습니다. 간단한 모델은 이해하거나 기억하기 쉽고 증명하기 쉽기 때문에 선호됩니다. 가끔 같은 데이터에서 간단한 가설은 더 복잡한 것보다 예측 정확도가 떨어집니다. 가장 강력한 학습 알고리즘 중 일부는 데이터에 완벽히 학습된 후에도 계속 무언가를 추가해 불필요하게 복잡한 모델을 만듭니다. 그렇기 때문에 덜 강력한 모델 보다 성능이 높습니다.
성능이 어떤 일정 수준의 범위 안에 있다면 예를 들어 1-표준 오차내의 간단한 모델을 선호하는 몇 가지 이유가 있습니다. 더 간단한 모델이 가장 정확한 것은 아닐 수 있지만 연산에 있어서 더 효율적일 수 있고 구현이 쉬우며 이해하기도 쉽습니다. 그리고 더 복잡한 모델에 비해 증명하기도 좋습니다.
실제로 1-표준 오차 방법이 어떻게 작동되는지 보기 위해 간단한 예시 데이터셋에 적용해보겠습니다. 이 데이터셋은 300개의 테스트 포인트로 동심원을 이루고 있고 균일한 클래스 분포를 가집니다(클래스 1이 150개 샘플, 클래스 2가 150개 샘플). 먼저 데이터셋을 클래스 비율이 같도록 계층 분할 방식으로 70% 훈련 데이터와 30% 테스트 데이터로 나눕니다. 훈련 데이터셋에 있는 210개 샘플은 아래와 같습니다.

비선형 RBFRadial Basis Function 커널을 사용한 서포트 벡터 머신Support Vector Machine의 감마gamma 하이퍼파라미터를 최적화려고 합니다. 여기서 
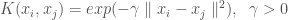
(직관적으로 감마 파라미터는 훈련 샘플이 결정 경계에 미치는 영향을 조절한다고 생각할 수 있습니다.)
계층 10-겹 교차 검증을 사용해 훈련 세트에 대해 여러가지 감마 값으로 RBF 커널 SVM 알고리즘을 실행하면 다음과 같은 성능 추정을 얻었습니다. 여기서 에러 막대는 교차 검증 추정의 표준 오차입니다:

(이 글에 있는 그래프를 그린 코드는 깃허브 주피터 노트북에서 볼 수 있습니다)
0.1에서 100까지의 감마값에서 80% 이상의 예측 정확도를 내고 있습니다. 더군다나 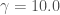
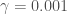
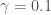
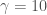
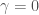
정리 및 결론
예측 모델의 일반화 성능을 평가하는 방법에는 여러 가지가 있습니다. 지금까지 홀드아웃 방법, 여러가지 부트스트랩 방법과 k-겹 교차 검증을 보았습니다. 개인적인 의견으로는 홀드아웃 방법은 비교적 샘플 사이즈가 클때 모델 평가로 아주 적당합니다. 하이퍼파라미터 튜닝을 하려면 10-겹 교차 검증, 작은 샘플사이즈일 경우에는 LOOCV 가 좋습니다. 모델 선택에서는 연산 비용이 제약 때문에 3방향 홀드아웃 방식이 좋습니다. 다른 좋은 대안으로는 독립적인 테스트셋을 둔 k-겹 교차 검증이 있습니다. 모델 선택이나 알고리즘 선택에 더 좋은 방법은 4장에서 이야기할 중첩 교차 검증nested cross-validation입니다.6
다음
이 시리즈의 다음 글에서 가설 테스트 와 알고리즘 선택 방법에 대해 좀 더 자세히 알아 보겠습니다.
증권 분석가를 고용한다고 가정해 보겠습니다. 좋은 증권 분석가를 찾으려고, 인터뷰에 앞서 어떤 주식 가격이 10일 이내에 올라갈지 내려갈지를 지원자들에게 예측해 보라고 요청합니다. 좋은 지원자는 10개의 예측에서 적어도 8개를 맞춰야 합니다. 주식시장이 어떻게 동작하는지 알지 못하면 매일의 트렌드를 정확히 예측할 확률은 50%입니다. 매일 동전 던지기를 하는거죠. 이런 지원자를 인터뷰할 때 10번 중 8번을 맞출 확률은 0.0547 입니다:7

다른 말로 하면 지원자들의 예측 성능이 우연이 아니라고 말할 수 있습니다. 그러나 단 한명만 인터뷰하는 것이 아니라 100명을 초청합니다. 이 100명에게 예측을 요청합니다. 모두 주식 시장이 어떻게 작동하는지 모르고 무작위로 추출한다고 가정합니다. 지원자들 중 적어도 한 명이 10개 중 8개의 예측을 맞출 확률은 다음과 같습니다:8

그래서 10개의 예측 중 8개를 맞춘 지원자가 단순히 추측하지 않았을 거라고 가정할 수 있나요? 이런 가설 테스트와 학습 알고리즘 간의 비교에 대해 4장에서 이어가겠습니다.
참고문헌
- Bengio, Yoshua, and Yves Grandvalet. 2004. “No Unbiased Estimator of the Variance of K-Fold Cross-Validation.” J. Mach. Learn. Res. 5 (December). JMLR.org: 1089–1105.
- Breiman, Leo, Jerome Friedman, Charles J Stone, and Richard A Olshen. 1984. Classification and Regression Trees. CRC press. Breiman, Leo. 1996. “Heuristics of Instability and Stabilization in Model Selection.” The Annals of Statistics 24 (6). Institute of Mathematical Statistics: 2350–83.
- Hastie, Trevor, Robert Tibshirani, and J. H. Friedman. “7.10.1 K-Fold Cross-Validation.” In The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed. New York: Springer, 2009.
- Hawkins, Douglas M., Subhash C. Basak, and Denise Mills. 2003. “Assessing Model Fit by Cross-Validation.” Journal of Chemical Information and Computer Sciences 43 (2). American Chemical Society: 579–86.
- Kohavi, Ron. 1995. “A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection.” International Joint Conference on Artificial Intelligence 14 (12): 1137–43
- James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. “5.1 Cross-Validation” In An Introduction to Statistical Learning: With Applications in R. Vol. 6. New York: Springer, 2013.
- Jiang, Wenyu, and Richard Simon. 2007. “A Comparison of Bootstrap Methods and an Adjusted Bootstrap Approach for Estimating the Prediction Error in Microarray Classification.” Statistics in Medicine 26 (29): 5320–34.
- Kim, Ji-Hyun. 2009. “Estimating Classification Error Rate: Repeated Cross-Validation, Repeated Hold-out and Bootstrap.” Computational Statistics & Data Analysis 53 (11): 3735–45.
- Molinaro, Annette M, Richard Simon, and Ruth M Pfeiffer. 2005. “Prediction Error Estimation: A Comparison of Resampling Methods.” Bioinformatics (Oxford, England) 21 (15). Oxford University Press: 3301–7.
- Refaeilzadeh, Payam, Lei Tang, and Huan Liu. 2007. “On Comparison of Feature Selection Algorithms.” In Proceedings of AAAI Workshop on Evaluation Methods for Machine Learning II, 34–39.
- Tan, Pang-Ning, Michael Steinbach, and Vipin Kumar. “4. Classification: Basic Concepts, Decision Trees, and Model Evaluation.” In Introduction to Data Mining. Boston: Pearson Addison Wesley, 2005.
(역주)
- 여기에서 편향은 선형 모델에 있는 절편을 말합니다.
- 선형 모델에 추가되는 L2 정규화항의 가중치 파라메타를 종종 람다(
)라고 부릅니다.
- k-겹 교차 검증을 여러번 반복하면 랜덤하게 샘플링을 하므로 폴드안의 샘플이 달라지지만 LOOCV는 하나의 샘플을 제외하고 모두 훈련 세트로 사용하므로 LOOCV를 반복하더라도 폴드안의 샘플이 달라지지 않습니다.
- LOOCV의 테스트 성능 추정은 하나의 샘플에 대해서 이루어지고 전체 샘플 개수 만큼 반복하므로 이항분포로 분산을 계산할 수 있습니다. 따라서 LOOCV 추정값의 분산이 샘플 개수 n 에 비례하다는 것을 설명하고 있습니다.
- 피어슨 상관계수
가 클수록 공분산이 커진다는 것을 보이고 있습니다. 상관관계가 있는 두 변수의 분산은 각 변수의 분산과 공분산을 합한 것입니다.
scikit-learn의 예를 들면GridSearchCV를cross_val_score로 감싸면 중첩 크로스 밸리데이션이 됩니다.- 10개 중에서 8개 이상을 맞출 조합의 수를 전체 조합의 수로 나누었습니다.
- 모든 지원자(100명)가 8개 이상 맞추지 못할(
) 확률을 전체에서 빼면 적어도 한 사람이 8개 이상 맞출 확률이 됩니다.

도움이 많이 되었습니다.
기초적인 질문하나 해도 될른지요. K-fold cross validation을 하면 모델이 K개 만들어지고, 각각이 평가되는 것(performance)는 알겠는데, 그럼 K개 모델을 이용해서 최종적으로 어떻게 최종모델을 선택하는지요?
좋아요좋아요
예를 들어 단순히 K개를 평균한다던지… 아니면 performance 결과에 따라 combination을 하는건가요?
좋아요좋아요
한 모델에서 k개의 검증 스코어가 나오는 것이구요. 평균을 내어 해당 모델의 스코어로 사용합니다. ^^
좋아요좋아요
네… 감사합니다. 질문할때는 그 개념을 몰랐는데, 이제 알게 되었습니다. 지금 생각하면 왜 저런 질문을 했을까라는 생각도 드는데, 다 그런 과정을 거쳐 하나하나 알게 되는건가봅니다. 혼자 독학하는거라 ㅋㅋ 항상 감사합니다.
좋아요Liked by 1명
한 모델에서 k개의 검증 스코어가 나온다는 말씀은 오해의 소지가 있는 것 같습니다.
정확하게는 하나의 조건에서 k개의 모델과 k개의 검증스코어가 나온다는 말이 맞지 않나요?
그렇게 해서 최적의 조건(하이퍼파라미터)을 찾게끔 되는 것이구요.
결국 최종 선택 모델은 가장 좋은 성능을 보인 조건으로 전체 set을 학습시킨 모델이 되는거구요.
좋아요좋아요
네 맞습니다. 모델 클래스 객체를 하나 만들어 교차 검증 함수에 넣고 결과를 얻기 때문에 보통 가볍게 이야기할 때는 “이 모델로 5개의 검증 점수를 얻었어요”라고 합니다. 하지만 정확히 말하면 여러개의 모델이 맞죠. 🙂
좋아요좋아요
너무 정리를 잘해주셔서 많이 배우고 갑니다 ^^
좋아요Liked by 1명
도움이 되셨다니 저도 기분이 좋네요. 🙂
좋아요좋아요
4편은 않나오는 건가요?!ㅎㅎ 마지막 “그래서 10개의 예측 중 8개를 맞춘 지원자가 단순히 추측하지 않았을 거라고 가정할 수 있나요?”의 답은 예스인가요 노인가요?! 노라면 위의 평가를 어떻게 바꿔야 되는지요?!
좋아요Liked by 1명
미처 번역만 해 놓고 p-value를 계산해 볼 생각을 못했네요. : ) (세바스찬 라쉬카가 현재 딥러닝 책을 집필하고 있어서 4편을 기대하긴 어려울 듯 싶습니다 ㅎㅎ)
좋아요Liked by 1명
핑백: 머신 러닝의 모델 평가와 모델 선택, 알고리즘 선택 – 3장. 크로스밸리데이션과 하이퍼파라미터 튜닝 – Goooodday's Blog
잘 읽었습니다. 그럼 지금까지 설명해준 k-fold나 loocv는 그냥 모델 선택에만 쓰이고 알고리즘 선택에서는 안쓰이는 건가요..?
좋아요좋아요
보통 모델 선택과 알고리즘 선택은 동일한 의미로 사용합니다. 문맥에 따라서 모델이 어떤 구조(architecture)를 의미하기도 하지만 여기서는 일반적인 머신러닝 모델을 말합니다.
좋아요좋아요
정성스럽고 좋은 글 잘 읽었습니다. 도움 받은것 같아서 고마움을 전합니다.
좋아요Liked by 1명
감사합니다. 도움이 되셨다니 기쁘네요! 🙂
좋아요좋아요
잘 보고 갑니다:) 감사합니다!
좋아요Liked by 1명
댓글 남겨 주셔서 감사합니다! 🙂
좋아요좋아요
안녕하세요 . 혹시 샘플 사이즈가 큰지 작은지는 어떻게 판단하나요?
ex) 만개 이하
감사합니다.
좋아요좋아요
문제와 방법에 따라 다르기 때문에 일반적인 규칙을 찾긴 어렵습니다. https://machinelearningmastery.com/much-training-data-required-machine-learning/ 을 참고하세요. 🙂
좋아요좋아요
안녕하세요! 잘 보고 있습니다.
4편이 현재 웹사이트에 연재가 되었던데, 혹시 번역하실 계획이 있는지 궁금합니다!
그리고 좋은 글 감사드립니다.
좋아요좋아요
넵 그럼요. 그런데 시간이 여의치 않네요. ^^
좋아요좋아요
너무 유익한 글 정말 감사드립니다. 혹시 질문 하나만 드려도 될까요?
모델 선택, 모델 평가에 둘 다 모두 k-fold 교차 검증을 한다면,
먼저 모델 평가를 위해 나눴던 k-fold 각각이, 이제 모두 서로 다른 하이퍼파라미터를 가지게 될텐데,
이 때 최종모델을 선정하기 위해서는 어떤 하이퍼파라미터를 선택해야하는 건가요?
좋아요좋아요
모델 평가는 말 그대로 평가를 위한 단계입니다. 새로운 모델을 선택하는 방법이 아닙니다. 🙂
좋아요좋아요
박해선님, 답변해주셔서 감사합니다! 정말 죄송한데 하나만 더 질문을 드려도 괜찮을까요?
그렇다면 비교적 작은 표본에 대해서 처음 train set과 test set으로 나누어지는 것에 따라 하이퍼 파라미터 선택이 크게 달라지게 되어, 중첩 교차 검증을 하고자 합니다.
nested cross-validation에서는 바깥쪽 루프에서 데이터를 train set와 test set로 나눈 여러개의 fold폴드를 만듭니다. train set과 test set이 나누어지는 것에 따라 하이퍼 파라미터의 선택이 달라지기 때문에 바깥쪽 루프에서 분할된 fold의 train set마다 optimal parameter가 다를 수 있습니다.
그런 다음 바깥쪽에서 분할된 fold의 test set의 점수를 optimal parameter 설정을 사용해 각각 측정합니다.
이런 경우에 특정 데이터셋에서 주어진 모델이 얼마나 잘 일반화되는지 평가할 수가 있다고 생각하는데 알고리즘 선택에 유용하다고 생각하였습니다. 그러나…
이 방법을 통해서는 결국 바깥쪽 루프에서 분할된 fold에서 서로 다른 optimal parameter를 가질 수 있기 때문에, 그러나 바깥쪽 루프는 새로운 모델 선택이 아닌 모델 평가를 위한 단계이므로, 모델 선택하는 것이 불가능한 방법론인가요?
그렇다면 비교적 작은 표본일 때 train set과 test set이 나누어지는 것에 따라 하이퍼 파라미터 선택이 크게 달라지는 경우에는 어떤 식으로 CV를 활용한 하이퍼파라미터 선택이나 모델 선택이 가능한지 여쭤보고 싶습니다.
좋아요좋아요
안녕하세요. 말씀하신대로 교차 검증은 모델을 평가하기 위한 방법입니다. 만약 데이터셋이 작다면 일반화 성능을 포기하고 전체 데이터셋에 그리드서치를 적용하여 모델을 고를 수 있습니다. 하지만 선택한 모델의 일반화 성능은 알 수 없겠죠. 🙂
좋아요좋아요