3.5 뉴스 기사 분류: 다중 분류 문제 | 목차 | 3.7 요약
앞의 두 예제는 분류 문제입니다. 입력 데이터 포인트의 개별적인 레이블 하나를 예측하는 것이 목적입니다. 또 다른 종류의 머신 러닝 문제는 개별적인 레이블 대신에 연속적인 값을 예측하는 회귀regression입니다. 예를 들어 기상 데이터가 주어졌을 때 내일 기온을 예측하거나, 소프트웨어 명세가 주어졌을 때 소프트웨어 프로젝트가 완료될 시간을 예측하는 것입니다.
Note: 회귀와 로지스틱 회귀logistic regression 알고리즘을 혼동하지 마세요. 로지스틱 회귀는 회귀 알고리즘이 아니라 분류 알고리즘입니다.37
3.6.1 보스턴 주택 가격 데이터셋
1970년 중반 보스턴 외곽 지역의 범죄율, 지방세율 등의 데이터가 주어졌을 때 주택 가격의 중간 값을 예측해 보겠습니다. 여기서 사용할 데이터셋은 이전 2개의 예제와 다릅니다. 데이터 포인트가 506개로 비교적 개수가 적고 404개는 훈련 샘플로, 102개는 테스트 샘플로 나뉘어 있습니다. 입력 데이터에 있는 각 특성feature(예를 들어 범죄율)은 스케일이 서로 다릅니다. 어떤 값은 0과 1 사이의 비율을 나타내고, 어떤 것은 1과 12 사이의 값을 가지거나 1과 100 사이의 값을 가집니다.
from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
데이터를 살펴보겠습니다.
>>> train_data.shape (404, 13) >>> test_data.shape (102, 13)
여기서 볼 수 있듯이 404개의 훈련 샘플과 102개의 테스트 샘플이 있고 모두 13개의 수치 특성이 있습니다. 이 특성들은 1인당 범죄율, 주택당 평균 방의 개수, 고속도로 접근성 등입니다.
타깃은 주택의 중간 가격으로 천 달러 단위입니다.
>>> train_targets [ 15.2, 42.3, 50. .. . 19.4, 19.4, 29.1]
이 가격은 일반적으로 1만 달러에서 5만 달러 사이입니다. 저렴하게 느껴질 텐데 1970년대 중반이라는 것을 기억하세요. 아직 인플레이션에 영향을 받지 않은 가격입니다.
3.6.2 데이터 준비
상이한 스케일을 가진 값을 신경망에 주입하면 문제가 됩니다. 네트워크가 이런 다양한 데이터에 자동으로 맞추려고 할 수 있지만 이는 확실히 학습을 더 어렵게 만듭니다.38 이런 데이터를 다룰 때 대표적인 방법은 특성별로 정규화를 하는 것입니다. 입력 데이터에 있는 각 특성(입력 데이터 행렬의 열)에 대해서 특성의 평균을 빼고 표준 편차로 나눕니다.39 특성의 중앙이 0 근처에 맞추어지고 표준 편차가 1이 됩니다. 넘파이를 사용하면 간단하게 할 수 있습니다.
mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std
테스트 데이터를 정규화할 때 사용한 값이 훈련 데이터에서 계산한 값임을 주목하세요. 머신 러닝 작업 과정에서 절대로 테스트 데이터에서 계산한 어떤 값도 사용해서는 안 됩니다. 데이터 정규화처럼 간단한 작업조차도 그렇습니다.40
3.6.3 모델 구성
샘플 개수가 적기 때문에 64개의 유닛을 가진 2개의 은닉 층으로 작은 네트워크를 구성하여 사용하겠습니다. 일반적으로 훈련 데이터의 개수가 적을수록 과대적합이 더 쉽게 일어나므로 작은 모델을 사용하는 것이 과대적합을 피하는 한 방법입니다.
from keras import models from keras import layers def build_model(): 동일한 모델을 여러 번 생성할 것이므로 함수를 만들어 사용합니다. model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) return model
이 네트워크의 마지막 층은 하나의 유닛을 가지고 있고 활성화 함수가 없습니다(선형 층이라고 부릅니다). 이것이 전형적인 스칼라 회귀(하나의 연속적인 값을 예측하는 회귀)를 위한 구성입니다. 활성화 함수를 적용하면 출력 값의 범위를 제한하게 됩니다. 예를 들어 마지막 층에 sigmoid 활성화 함수를 적용하면 네트워크가 0과 1 사이의 값을 예측하도록 학습될 것입니다. 여기서는 마지막 층이 순수한 선형이므로 네트워크가 어떤 범위의 값이라도 예측하도록 자유롭게 학습됩니다.
이 모델은 mse 손실 함수를 사용하여 컴파일합니다. 이 함수는 평균 제곱 오차mean squared error의 약어로 예측과 타깃 사이 거리의 제곱입니다. 회귀 문제에서 널리 사용되는 손실 함수입니다.
훈련하는 동안 모니터링을 위해 새로운 지표인 평균 절대 오차Mean Absolute Error, MAE를 측정합니다. 이는 예측과 타깃 사이 거리의 절댓값입니다. 예를 들어 이 예제에서 MAE가 0.5면 예측이 평균적으로 500달러 정도 차이가 난다는 뜻입니다.
3.6.4 K-겹 검증을 사용한 훈련 검증
(훈련에 사용할 에포크의 수 같은) 매개변수들을 조정하면서 모델을 평가하기 위해 이전 예제에서 했던 것처럼 데이터를 훈련 세트와 검증 세트로 나눕니다. 데이터 포인트가 많지 않기 때문에 검증 세트도 매우 작아집니다(약 100개의 샘플). 결국 검증 세트와 훈련 세트로 어떤 데이터 포인트가 선택되었는지에 따라 검증 점수가 크게 달라집니다. 검증 세트의 분할에 대한 검증 점수의 분산이 높습니다. 이렇게 되면 신뢰 있는 모델 평가를 할 수 없습니다.
이런 상황에서 가장 좋은 방법은 K-겹 교차 검증K-fold cross-validation을 사용하는 것입니다(그림 3–11 참고). 데이터를 K개의 분할(즉 폴드(fold))로 나누고(일반적으로 K = 4 또는 5), K개의 모델을 각각 만들어 K – 1개의 분할에서 훈련하고 나머지 분할에서 평가하는 방법입니다. 모델의 검증 점수는 K개의 검증 점수 평균이 됩니다. 코드로 보면 이해하기 쉽습니다.41

그림 3-11 3-겹 교차 검증
import numpy as np k = 4 num_val_samples = len(train_data) // k num_epochs = 100 all_scores = [] for i in range(k): print('처리중인 폴드 #', i) val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples] # 검증 데이터 준비: k번째 분할 val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples] partial_train_data = np.concatenate( # 훈련 데이터 준비: 다른 분할 전체 [train_data[:i * num_val_samples], train_data[(i + 1) * num_val_samples:]], axis=0) partial_train_targets = np.concatenate( [train_targets[:i * num_val_samples], train_targets[(i + 1) * num_val_samples:]], axis=0) model = build_model() # 케라스 모델 구성(컴파일 포함) model.fit(partial_train_data, partial_train_targets, # 모델 훈련(verbose=0이므로 훈련 과정이 출력되지 않습니다.) epochs=num_epochs, batch_size=1, verbose=0) val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0) # 검증 세트로 모델 평가 all_scores.append(val_mae)
num_epochs = 100으로 실행하면 다음 결과를 얻습니다.
>>> all_scores [2.0956787838794217, 2.220593797098292, 2.859968412040484, 2.40535704039111] >>> np.mean(all_scores) 2.3953995083523267
검증 세트가 다르므로 확실히 검증 점수가 2.1에서 2.9까지 변화가 큽니다. 평균값(2.4)이 각각의 점수보다 훨씬 신뢰할 만합니다. 이것이 K–겹 교차 검증의 핵심입니다. 이 예에서는 평균적으로 3,000달러 정도 차이가 납니다. 주택 가격의 범위가 1만 달러에서 5만 달러 사이인 것을 감안하면 비교적 큰 값입니다.
신경망을 조금 더 오래 500 에포크 동안 훈련해 보죠. 각 에포크마다 모델이 얼마나 개선되는지 기록하기 위해 훈련 루프를 조금 수정해서 에포크의 검증 점수를 로그에 저장하겠습니다.
num_epochs = 500 all_mae_histories = [] for i in range(k): print('처리중인 폴드 #', i) val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples] #검증 데이터 준비: k번째 분할 val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples] partial_train_data = np.concatenate( # 훈련 데이터 준비: 다른 분할 전체 [train_data[:i * num_val_samples], train_data[(i + 1) * num_val_samples:]], axis=0) partial_train_targets = np.concatenate( [train_targets[:i * num_val_samples], train_targets[(i + 1) * num_val_samples:]], axis=0) model = build_model() # 케라스 모델 구성(컴파일 포함) history = model.fit(partial_train_data, partial_train_targets, # 모델 훈련(verbose=0이므로 훈련 과정이 출력되지 않습니다.) validation_data=(val_data, val_targets), epochs=num_epochs, batch_size=1, verbose=0) mae_history = history.history['val_mean_absolute_error'] all_mae_histories.append(mae_history)
그다음 모든 폴드에 대해 에포크의 MAE 점수 평균을 계산합니다.42
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
그래프로 나타내면 그림 3–12와 같습니다.
import matplotlib.pyplot as plt plt.plot(range(1, len(average_mae_history) + 1), average_mae_history) plt.xlabel('Epochs') plt.ylabel('Validation MAE') plt.show()

그림 3-12 에포크별 검증 MAE
이 그래프는 범위가 크고 변동이 심하기 때문에 보기가 좀 어렵습니다. 다음과 같이 해 보죠.
- 곡선의 다른 부분과 스케일이 많이 다른 첫 10개의 데이터 포인트를 제외시킵니다.
- 부드러운 곡선을 얻기 위해 각 포인트를 이전 포인트의 지수 이동 평균exponential moving average으로 대체합니다.43
결과는 그림 3–13과 같습니다.
def smooth_curve(points, factor=0.9): smoothed_points = [] for point in points: if smoothed_points: previous = smoothed_points[-1] smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_points smooth_mae_history = smooth_curve(average_mae_history[10:]) plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history) plt.xlabel('Epochs') plt.ylabel('Validation MAE') plt.show()
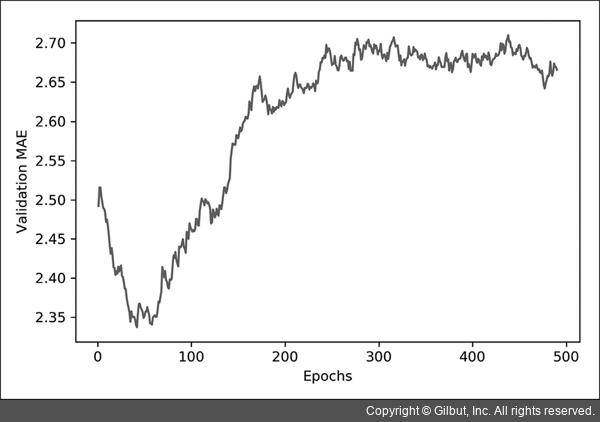
그림 3-13 처음 10개의 데이터 포인트를 제외한 에포크별 검증 MAE
이 그래프를 보면 검증 MAE가 80번째 에포크 이후에 줄어드는 것이 멈추었습니다. 이 지점 이후로는 과대적합이 시작됩니다.
모델의 여러 매개변수에 대한 튜닝이 끝나면(에포크 수뿐만 아니라 은닉 층의 크기도 조절할 수 있습니다) 모든 훈련 데이터를 사용하고 최상의 매개변수로 최종 실전에 투입될 모델을 훈련시킵니다. 그다음 테스트 데이터로 성능을 확인합니다.
model = build_model() # 새롭게 컴파일된 모델을 얻습니다. model.fit(train_data, train_targets, # 전체 데이터로 훈련시킵니다. epochs=80, batch_size=16, verbose=0) test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
최종 결과는 다음과 같습니다.
>>> test_mae_score 2.675027286305147
아직 2,675달러 정도 차이가 나네요.
3.6.5 정리
다음은 이 예제에서 배운 것들입니다.
- 회귀는 분류에서 사용했던 것과는 다른 손실 함수를 사용합니다. 평균 제곱 오차(MSE)는 회귀에서 자주 사용되는 손실 함수입니다.
- 비슷하게 회귀에서 사용되는 평가 지표는 분류와 다릅니다. 당연히 정확도 개념은 회귀에 적용되지 않습니다. 일반적인 회귀 지표는 평균 절대 오차(MAE)입니다.
- 입력 데이터의 특성이 서로 다른 범위를 가지면 전처리 단계에서 각 특성을 개별적으로 스케일 조정해야 합니다.
- 가용한 데이터가 적다면 K-겹 검증을 사용하는 것이 신뢰할 수 있는 모델 평가 방법입니다.
- 가용한 훈련 데이터가 적다면 과대적합을 피하기 위해 은닉 층의 수를 줄인 모델이 좋습니다(일반적으로 1개 또는 2개).
37 역주 로지스틱 회귀는 선형 회귀(linear regression)의 분류 버전으로 중간층이 없고 하나의 유닛과 시그모이드 활성화 함수를 사용한 출력층만 있는 네트워크와 비슷합니다.
38 역주 특성의 스케일이 다르면 전역 최소 점을 찾아가는 경사 하강법의 경로가 스케일이 큰 특성에 영향을 많이 받습니다.
39 역주 정규화는 여러 가지 다른 의미로도 사용되기 때문에 오해하기 쉽습니다. 표준화(standardization)라고 하면 정확히 이 방식을 가리킵니다.
40 역주 쉽게 생각해서 훈련 데이터와 테스트 데이터를 각각 다른 스케일로 변환하게 되면 훈련 데이터에서 학습한 정보가 쓸모없게 되는 셈입니다. 마찬가지로 실전에 투입하여 새로운 데이터에 대한 예측을 만들 때도 훈련 데이터에서 계산한 값을 사용하여 정규화해야 합니다.
41 역주 사실 훈련 데이터의 통계 값으로 테스트 데이터를 전처리했듯이 검증 데이터도 훈련 데이터의 통계 값을 사용하여 전처리해야 합니다. 이렇게 하려면 앞선 전처리 과정이 K-겹 검증 루프 안으로 들어와야 합니다.
42 역주 파이썬에 익숙하지 않다면 이 코드가 낯설지도 모르겠습니다. 파이썬에서는 리스트 안에 for 문장을 놓는 리스트 내포(list comprehension) 형식이 있습니다. all_mae_histories는 4개의 폴드에 대한 검증 점수를 담고 있으므로 (4, 500) 크기입니다. 첫 번째 리스트 내포에서 폴드별로 i번째 에포크의 점수를 평균하고, 두 번째 리스트 내포에서 전체 에포크를 순회시킵니다. average_mae_ history의 크기는 (500,)이 됩니다. 넘파이를 사용하면 np.mean(all_mae_histories, axis=0)처럼 첫 번째 축을 따라 간단하게 평균을 구할 수 있습니다.
43 역주 지수 이동 평균은 시계열 데이터를 부드럽게 만드는 기법 중 하나입니다. 코드 3-31의 6번째 줄에서 이전에 계산된 이동 평균에 factor를 곱하고 현재 포인트에 (1 – factor)를 곱해 합산한 것을 가리킵니다
3.5 뉴스 기사 분류: 다중 분류 문제 | 목차 | 3.7 요약

안녕하세요
좋은 책 번역해주셔서 너무 감사합니다
책으로 하나씩 따라해보면서 실습해보고 있는데요.
중간에 에러가 발생해서 왜 그런건지 여줘보고자 합니다
코드를 입력후 런을 시키면
500에포크 동안 훈련해보기 위한 코드에서 이런 에러가 발생합니다
mae_history = history.history[‘val_mean_absolute_error’]
Traceback (most recent call last):
File “”, line 1, in
mae_history = history.history[‘val_mean_absolute_error’]
KeyError: ‘val_mean_absolute_error’
val_mean_absolute_error 이 부분에서 keyerror라고 뜨는데요
인터넷을 검색해봐도 알수가 없어 문의 드립니다.
감사합니다.
좋아요좋아요
아마도 케라스 2.3.x 버전을 쓰시는 것 같군요. 2.3.0 버전부터는 compile 메서드에 쓴 손실 이름을 그대로 사용해야 합니다. https://github.com/keras-team/keras/releases/tag/2.3.0 릴리스 노트의 Breaking changes를 참고하세요. 아직 2.3.x은 안정적이지 않습니다. 개인적으로는 2.2.x를 권장합니다. 감사합니다.
좋아요좋아요
안녕하세요? 박해선 개발자님..
val_mae로 바꿔서 해보니 됩니다…
저는 구글 코랩에서 실습을 하고 있는데요..버전이 업그레이드 되면 조금씩 불편감을 느낍니다…
코랩에서도 낮은 버전을 사용하는 방법이 있는지요??
좋아요좋아요
추가해서 질문 드리면…업그레이된 내용은 어디서 확인 할 수 있는지 궁금합니다…
좋아요좋아요
안녕하세요. 코랩에서 낮은 버전의 텐서플로를 다시 설치할 수 있지만 잘 동작된다고 보장하기 어려울 것 같습니다. 버전에 따라 바뀐 내용은 텐서플로 깃허브의 릴리스 노트를 참고하세요. 감사합니다.
좋아요좋아요
아나콘다3에 또 설치해야되는 라이브러리가 잇을까요?
인터넷이 제한되어 CD로 구워서 들어와야되는데
보스턴 집값예측같은걸 쓰고 싶은데 라이브러리 다운해서 다 완료된 아나콘다를 CD로 옮겨서 다른 인터넷 안되는 컴퓨터에 다운로드 가능할까요..?
좋아요좋아요
파이썬의 venv를 사용하시면 될 것 같습니다. 자세한 내용은 https://dojang.io/mod/page/view.php?id=2470 를 참고하세요.
좋아요좋아요
안녕하세요 regression 학습 코드를 독학하고 있는 학생입니다!
다름이 아니라 예측하는 변수를 1개(주택가격)로 두셨는데,
혹시 한개의 학습 모델로 2개의 변수를 예측할 수도 있을까요?
좋아요좋아요
안녕하세요. multi output regression 으로 검색하시면 관련된 정보를 찾으실 수 있을 것 같습니다. 감사합니다.
좋아요좋아요