2.3.2 k-최근접 이웃 | 목차 | 2.3.4 나이브 베이즈 분류기
–
선형 모델linear model은 100여 년 전에 개발되었고, 지난 몇십 년 동안 폭넓게 연구되고 현재도 널리 쓰입니다. 곧 보겠지만 선형 모델은 입력 특성에 대한 선형 함수를 만들어 예측을 수행합니다.
회귀의 선형 모델
회귀의 경우 선형 모델을 위한 일반화된 예측 함수는 다음과 같습니다.
ŷ = w[0] × x[0] + w[1] × x[1] + … + w[p] × x[p] + b
이 식에서 x[0]부터 x[p]까지는 하나의 데이터 포인트에 대한 특성을 나타내며(특성의 개수는 p + 1), w와 b는 모델이 학습할 파라미터입니다. 1 그리고 ŷ은 모델이 만들어낸 예측값입니다. 특성이 하나인 데이터셋이라면 이 식은 다음과 같아집니다.
ŷ = w[0] × x[0] + b
수학 시간에 배운 직선의 방정식을 기억하나요? 이 식에서 w[0]는 기울기고 b는 y 축과 만나는 절편입니다. 특성이 많아지면 w는 각 특성에 해당하는 기울기를 모두 가집니다. 다르게 생각하면 예측값은 입력 특성에 w의 각 가중치(음수일 수도 있음)를 곱해서 더한 가중치 합으로 볼 수 있습니다.
1차원 wave 데이터셋으로 파라미터 w[0]와 b를 [그림 2-11]의 직선처럼 되도록 학습시켜 보겠습니다.
In[26]:
mglearn.plots.plot_linear_regression_wave()
Out[26]:
w[0]: 0.393906 b: -0.031804
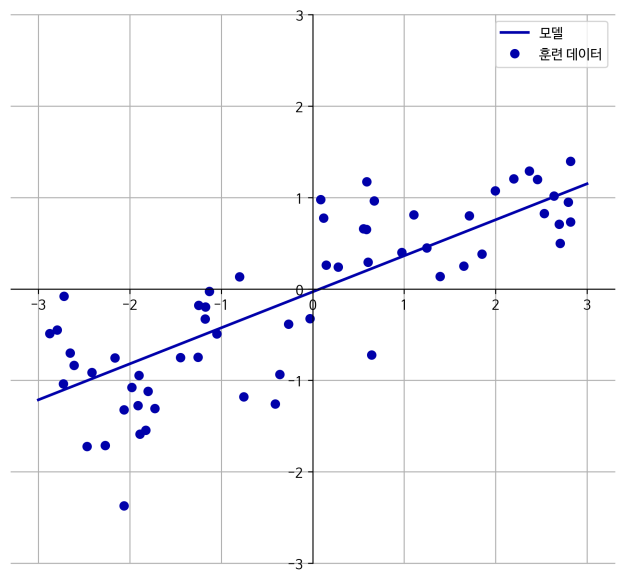
그림 2-11 wave 데이터셋에 대한 선형 모델의 예측
직선 방정식을 이해하기 쉽도록 그래프의 중앙을 가로질러서 x, y 축을 그렸습니다. w[0] 값을 보면 기울기는 대략 0.4 정도여야 하며, 그래프에서 이를 눈으로 확인할 수 있습니다.
회귀를 위한 선형 모델은 특성이 하나일 땐 직선, 두 개일 땐 평면이 되며, 더 높은 차원(특성이 더 많음)에서는 초평면hyperplane이 되는 회귀 모델의 특징을 가지고 있습니다.
이 직선과 KNeighborsRegressor를 사용하여 만든 [그림 2-10]의 선과 비교해보면 직선을 사용한 예측이 더 제약이 많아 보입니다. 즉 데이터의 상세 정보를 모두 잃어버린 것처럼 보입니다. 어느 정도는 사실입니다. 타깃 y가 특성들의 선형 조합이라는 것은 매우 과한 (때론 비현실적인) 가정입니다. 하지만 1차원 데이터만 놓고 봐서 생긴 편견일 수 있습니다. 특성이 많은 데이터셋이라면 선형 모델은 매우 훌륭한 성능을 낼 수 있습니다. 특히 훈련 데이터보다 특성이 더 많은 경우엔 어떤 타깃 y도 완벽하게 (훈련 세트에 대해서) 선형 함수로 모델링할 수 있습니다. 2
회귀를 위한 선형 모델은 다양합니다. 이 모델들은 훈련 데이터로부터 모델 파라미터 w와 b를 학습하는 방법과 모델의 복잡도를 제어하는 방법에서 차이가 납니다. 우리는 회귀에서 가장 인기 있는 선형 모델들을 살펴보겠습니다.
선형 회귀(최소제곱법)
선형 회귀linear regression 또는 최소제곱법OLS, ordinary least squares은 가장 간단하고 오래된 회귀용 선형 알고리즘입니다. 선형 회귀는 예측과 훈련 세트에 있는 타깃 y 사이의 평균제곱오차mean squared error를 최소화하는 파라미터 w와 b를 찾습니다. 평균제곱오차는 예측값과 타깃값의 차이를 제곱하여 더한 후에 샘플의 개수로 나눈 것입니다. 3 선형 회귀는 매개변수가 없는 것이 장점이지만, 그래서 모델의 복잡도를 제어할 방법도 없습니다.
다음은 [그림 2-11]의 선형 모델을 만드는 코드입니다.
In[27]:
from sklearn.linear_model import LinearRegression X, y = mglearn.datasets.make_wave(n_samples=60) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) lr = LinearRegression().fit(X_train, y_train)
기울기 파라미터(w)는 가중치weight 또는 계수coefficient라고 하며 lr 객체의 coef_ 속성에 저장되어 있고 편향offset 또는 절편intercept 파라미터(b)는 intercept_ 속성에 저장되어 있습니다.
In[28]:
print("lr.coef_: {}".format(lr.coef_))
print("lr.intercept_: {}".format(lr.intercept_))
Out[28]:
lr.coef_: [ 0.394] lr.intercept_: -0.031804343026759746
노트_ coef_와 intercept_ 뒤의 밑줄이 이상하게 보일지 모르겠습니다. scikit-learn은 훈련 데이터에서 유도된 속성은 항상 끝에 밑줄을 붙입니다. 그 이유는 사용자가 지정한 매개변수와 구분하기 위해서입니다.
intercept_ 속성은 항상 실수float 값 하나지만, coef_ 속성은 각 입력 특성에 하나씩 대응되는 NumPy 배열입니다. wave 데이터셋에는 입력 특성이 하나뿐이므로 lr.coef_도 원소를 하나만 가지고 있습니다.
훈련 세트와 테스트 세트의 성능을 확인해보겠습니다.
In[29]:
print("훈련 세트 점수: {:.2f}".format(lr.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(lr.score(X_test, y_test)))
Out[29]:
훈련 세트 점수: 0.67 테스트 세트 점수: 0.66
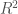
In[30]:
X, y = mglearn.datasets.load_extended_boston() X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) lr = LinearRegression().fit(X_train, y_train)
훈련 세트와 테스트 세트의 점수를 비교해보면 훈련 세트에서는 예측이 매우 정확한 반면 테스트 세트에서는 R2 값이 매우 낮습니다.
In[31]:
print("훈련 세트 점수: {:.2f}".format(lr.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(lr.score(X_test, y_test)))
Out[31]:
훈련 세트 점수: 0.95 테스트 세트 점수: 0.61
훈련 데이터와 테스트 데이터 사이의 이런 성능 차이는 모델이 과대적합되었다는 확실한 신호이므로 복잡도를 제어할 수 있는 모델을 사용해야 합니다. 기본 선형 회귀 방식 대신 가장 널리 쓰이는 모델은 다음에 볼 릿지 회귀입니다.
릿지 회귀
릿지Ridge도 회귀를 위한 선형 모델이므로 최소적합법에서 사용한 것과 같은 예측 함수를 사용합니다. 하지만 릿지 회귀에서의 가중치(w) 선택은 훈련 데이터를 잘 예측하기 위해서 뿐만 아니라 추가 제약 조건을 만족시키기 위한 목적도 있습니다. 가중치의 절댓값을 가능한 한 작게 만드는 것입니다. 다시 말해서 w의 모든 원소가 0에 가깝게 되길 원합니다. 직관적으로 생각하면 이는 모든 특성이 출력에 주는 영향을 최소한으로 만듭니다(기울기를 작게 만듭니다). 이런 제약을 규제regularization라고 합니다. 규제란 과대적합이 되지 않도록 모델을 강제로 제한한다는 의미입니다. 릿지 회귀에 사용하는 규제 방식을 L2 규제라고 합니다. 4
릿지 회귀는 linear_model.Ridge에 구현되어 있습니다. 릿지 회귀가 확장된 보스턴 주택가격 데이터셋에 어떻게 적용되는지 살펴보겠습니다.
In[32]:
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train, y_train)
print("훈련 세트 점수: {:.2f}".format(ridge.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(ridge.score(X_test, y_test)))
Out[32]:
훈련 세트 점수: 0.89 테스트 세트 점수: 0.75
결과를 보니 훈련 세트에서의 점수는 LinearRegression보다 낮지만 테스트 세트에 대한 점수는 더 높습니다. 기대한 대로입니다. 선형 회귀는 이 데이터셋에 과대적합되지만 Ridge는 덜 자유로운 모델이기 때문에 과대적합이 적어집니다. 모델의 복잡도가 낮아지면 훈련 세트에서의 성능은 나빠지지만 더 일반화된 모델이 됩니다. 관심 있는 것은 테스트 세트에 대한 성능이기 때문에 LinearRegression보다 Ridge 모델을 선택해야 합니다.
Ridge는 모델을 단순하게 (계수를 0에 가깝게) 해주고 훈련 세트에 대한 성능 사이를 절충할 수 있는 방법을 제공합니다. 사용자는 alpha 매개변수로 훈련 세트의 성능 대비 모델을 얼마나 단순화할지를 지정할 수 있습니다. 앞의 예제에서는 매개변수의 기본값인 alpha=1.0을 사용했습니다. 5 하지만 이 값이 최적이라고 생각할 이유는 없습니다. 최적의 alpha 값은 사용하는 데이터셋에 달렸습니다. alpha 값을 높이면 계수를 0에 더 가깝게 만들어서 훈련 세트의 성능은 나빠지지만 일반화에는 도움을 줄 수 있습니다. 예를 들면 다음과 같습니다.
In[33]:
ridge10 = Ridge(alpha=10).fit(X_train, y_train)
print("훈련 세트 점수: {:.2f}".format(ridge10.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(ridge10.score(X_test, y_test)))
Out[33]:
훈련 세트 점수: 0.79 테스트 세트 점수: 0.64
alpha 값을 줄이면 계수에 대한 제약이 그만큼 풀리면서 [그림 2-1]의 오른쪽으로 이동하게 됩니다. 아주 작은 alpha 값은 계수를 거의 제한하지 않으므로 LinearRegression으로 만든 모델과 거의 같아집니다. 6
In[34]:
ridge01 = Ridge(alpha=0.1).fit(X_train, y_train)
print("훈련 세트 점수: {:.2f}".format(ridge01.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(ridge01.score(X_test, y_test)))
Out[34]:
훈련 세트 점수: 0.93 테스트 세트 점수: 0.77
이 코드에서 alpha=0.1이 꽤 좋은 성능을 낸 것 같습니다. 테스트 세트에 대한 성능이 높아질 때까지 alpha 값을 줄일 수 있을 것입니다. 여기서는 alpha 값이 [그림 2-1]의 모델 복잡도와 어떤 관련이 있는지를 살펴보았습니다. 좋은 매개변수를 선택하는 방법은 5장에서 알아보도록 하겠습니다.
또한 alpha 값에 따라 모델의 coef_ 속성이 어떻게 달라지는지를 조사해보면 alpha 매개변수가 모델을 어떻게 변경시키는지 더 깊게 이해할 수 있습니다. 높은 alpha 값은 제약이 더 많은 모델이므로 작은 alpha 값일 때보다 coef_의 절댓값 크기가 작을 것이라고 예상할 수 있습니다. [그림 2-12]를 보면 이러한 사실을 확인할 수 있습니다.
In[35]:
plt.plot(ridge10.coef_, '^', label="Ridge alpha=10")
plt.plot(ridge.coef_, 's', label="Ridge alpha=1")
plt.plot(ridge01.coef_, 'v', label="Ridge alpha=0.1")
plt.plot(lr.coef_, 'o', label="LinearRegression")
plt.xlabel("계수 목록")
plt.ylabel("계수 크기")
plt.hlines(0, 0, len(lr.coef_))
plt.ylim(-25, 25)
plt.legend()
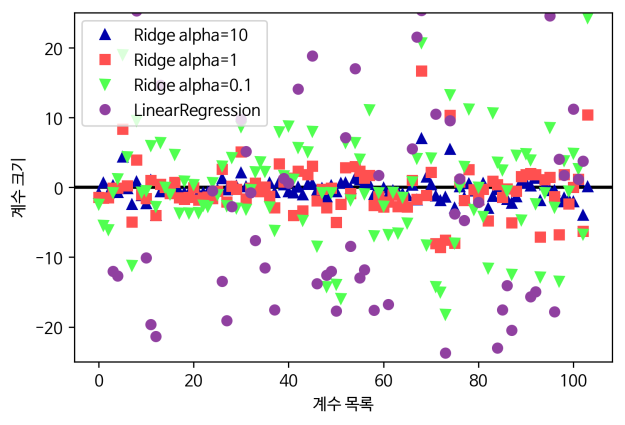
그림 2-12 선형 회귀와 몇 가지 alpha 값을 가진 릿지 회귀의 계수 크기 비교
이 그림에서 x 축은 coef_의 원소를 위치대로 나열한 것입니다. 즉 x=0은 첫 번째 특성에 연관된 계수이고 x=1은 두 번째 특성에 연관된 계수입니다. 이런 식으로 x=100까지 계속됩니다. y 축은 각 계수의 수치를 나타냅니다. alpha=10일 때 대부분의 계수는 -3과 3 사이에 위치합니다.
alpha=1일 때 Ridge 모델의 계수는 좀 더 커졌습니다. alpha=0.1일 때 계수는 더 커지며 아무런 규제가 없는(alpha=0) 선형 회귀의 계수는 값이 더 커져 그림 밖으로 넘어갑니다.
규제의 효과를 이해하는 또 다른 방법은 alpha 값을 고정하고 훈련 데이터의 크기를 변화시켜 보는 것입니다. [그림 2-13]은 보스턴 주택가격 데이터셋에서 여러 가지 크기로 샘플링하여 LinearRegression과 Ridge(alpha=1)을 적용한 것입니다(데이터셋의 크기에 따른 모델의 성능 변화를 나타낸 그래프를 학습 곡선learning curve이라고 합니다). 7
In[36]:
mglearn.plots.plot_ridge_n_samples()

그림 2-13 보스턴 주택가격 데이터셋에 대한 릿지 회귀와 선형 회귀의 학습 곡선
예상대로 모든 데이터셋에 대해 릿지와 선형 회귀 모두 훈련 세트의 점수가 테스트 세트의 점수보다 높습니다. 릿지에는 규제가 적용되므로 릿지의 훈련 데이터 점수가 전체적으로 선형 회귀의 훈련 데이터 점수보다 낮습니다. 그러나 테스트 데이터에서는 릿지의 점수가 더 높으며 특별히 작은 데이터셋에서는 더 그렇습니다. 데이터셋 크기가 400 미만에서는 선형 회귀는 어떤 것도 학습하지 못하고 있습니다. 두 모델의 성능은 데이터가 많아질수록 좋아지고 마지막에는 선형 회귀가 릿지 회귀를 따라잡습니다. 여기서 배울 수 있는 것은 데이터를 충분히 주면 규제 항은 덜 중요해져서 릿지 회귀와 선형 회귀의 성능이 같아질 것이라는 점입니다(이 예에서는 우연히 전체 데이터를 사용했을 때 이런 일이 생겼습니다). [그림 2-13]에서 또 하나의 흥미로운 점은 선형 회귀의 훈련 데이터 성능이 감소한다는 것입니다. 이는 데이터가 많아질수록 모델이 데이터를 기억하거나 과대적합하기 어려워지기 때문입니다.
라쏘
선형 회귀에 규제를 적용하는 데 Ridge의 대안으로 Lasso가 있습니다. 릿지 회귀에서와 같이 라쏘lasso도 계수를 0에 가깝게 만들려고 합니다. 하지만 방식이 조금 다르며 이를 L1 규제라고 합니다. 8 L1 규제의 결과로 라쏘를 사용할 때 어떤 계수는 정말 0이 됩니다. 이 말은 모델에서 완전히 제외되는 특성이 생긴다는 뜻입니다. 어떻게 보면 특성 선택feature selection이 자동으로 이뤄진다고 볼 수 있습니다. 일부 계수를 0으로 만들면 모델을 이해하기 쉬워지고 이 모델의 가장 중요한 특성이 무엇인지 드러내줍니다.
확장된 보스턴 주택가격 데이터셋에 라쏘를 적용해보겠습니다.
In[37]:
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print("훈련 세트 점수: {:.2f}".format(lasso.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(lasso.score(X_test, y_test)))
print("사용한 특성의 수: {}".format(np.sum(lasso.coef_ != 0)))
Out[37]:
훈련 세트 점수: 0.29 테스트 세트 점수: 0.21 사용한 특성의 수: 4
결과에서 볼 수 있듯이 Lasso는 훈련 세트와 테스트 세트 모두에서 결과가 좋지 않습니다. 이는 과소적합이며 105개의 특성 중 4개만 사용한 것을 볼 수 있습니다. Ridge와 마찬가지로 Lasso도 계수를 얼마나 강하게 0으로 보낼지를 조절하는 alpha 매개변수를 지원합니다. 앞에서는 기본값인 alpha=1.0을 사용했습니다. 과소적합을 줄이기 위해서 alpha 값을 줄여보겠습니다. 이렇게 하려면 max_iter(반복 실행하는 최대 횟수)의 기본값을 늘려야 합니다. 8
In[38]:
# "max_iter" 기본값을 증가시키지 않으면 max_iter 값을 늘리라는 경고가 발생합니다.
lasso001 = Lasso(alpha=0.01, max_iter=100000).fit(X_train, y_train)
print("훈련 세트 점수: {:.2f}".format(lasso001.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(lasso001.score(X_test, y_test)))
print("사용한 특성의 수: {}".format(np.sum(lasso001.coef_ != 0)))
Out[38]:
훈련 세트 점수: 0.90 테스트 세트 점수: 0.77 사용한 특성의 수: 33
alpha 값을 낮추면 모델의 복잡도는 증가하여 훈련 세트와 테스트 세트에서의 성능이 좋아집니다. 성능은 Ridge보다 조금 나은데 사용된 특성은 105개 중 33개뿐이어서, 아마도 모델을 분석하기가 조금 더 쉽습니다.
그러나 alpha 값을 너무 낮추면 규제의 효과가 없어져 과대적합이 되므로 LinearRegression의 결과와 비슷해집니다.
In[39]:
lasso00001 = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)
print("훈련 세트 점수: {:.2f}".format(lasso00001.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(lasso00001.score(X_test, y_test)))
print("사용한 특성의 수: {}".format(np.sum(lasso00001.coef_ != 0)))
Out[39]:
훈련 세트 점수: 0.95 테스트 세트 점수: 0.64 사용한 특성의 수: 94
[그림 2-12]와 비슷하게 alpha 값이 다른 모델들의 계수를 그래프로 그려보겠습니다. 결과는 [그림 2-14]와 같습니다.
In[40]:
plt.plot(lasso.coef_, 's', label="Lasso alpha=1")
plt.plot(lasso001.coef_, '^', label="Lasso alpha=0.01")
plt.plot(lasso00001.coef_, 'v', label="Lasso alpha=0.0001")
plt.plot(ridge01.coef_, 'o', label="Ridge alpha=0.1")
plt.legend(ncol=2, loc=(0, 1.05))
plt.ylim(-25, 25)
plt.xlabel("계수 목록")
plt.ylabel("계수 크기")

그림 2-14 릿지 회귀와 alpha 값이 다른 라쏘 회귀의 계수 크기 비교
alpha=1일 때 (이미 알고 있듯) 계수 대부분이 0일 뿐만 아니라 나머지 계수들도 크기가 작다는 것을 알 수 있습니다. alpha를 0.01로 줄이면 대부분의 특성이 0이 되는 (정삼각형 모양으로 나타낸) 분포를 얻게 됩니다. alpha=0.0001이 되면 계수 대부분이 0이 아니고 값도 커져 꽤 규제받지 않은 모델을 얻게 됩니다. 비교를 위해 릿지 회귀를 원 모양으로 나타냈습니다. alpha=0.1인 Ridge 모델은 alpha=0.01인 라쏘 모델과 성능이 비슷하지만 Ridge를 사용하면 어떤 계수도 0이 되지 않습니다.
실제 이 두 모델 중 보통은 릿지 회귀를 선호합니다. 하지만 특성이 많고 그중 일부분만 중요하다면 Lasso가 더 좋은 선택일 수 있습니다. 또한 분석하기 쉬운 모델을 원한다면 Lasso가 입력 특성 중 일부만 사용하므로 쉽게 해석할 수 있는 모델을 만들어줄 것입니다. scikit-learn은 Lasso와 Ridge의 페널티를 결합한 ElasticNet도 제공합니다. 실제로 이 조합은 최상의 성능을 내지만 L1 규제와 L2 규제를 위한 매개변수 두 개를 조정해야 합니다. 10
분류용 선형 모델
선형 모델은 분류에도 널리 사용합니다. 먼저 이진 분류binary classification를 살펴보겠습니다. 이 경우 예측을 위한 방정식은 다음과 같습니다. 11
ŷ = w[0] × x[0] + w[1] × x[1] + … + w[p] × x[p] + b > 0
이 방정식은 선형 회귀와 아주 비슷합니다. 하지만 특성들의 가중치 합을 그냥 사용하는 대신 예측한 값을 임계치 0과 비교합니다. 함수에서 계산한 값이 0보다 작으면 클래스를 -1이라고 예측하고 0보다 크면 +1이라고 예측합니다. 이 규칙은 분류에 쓰이는 모든 선형모델에서 동일합니다. 여기에서도 계수(w)와 절편(b)을 찾기 위한 방법이 많이 있습니다.
회귀용 선형 모델에서는 출력 ŷ이 특성의 선형 함수였습니다. 즉 직선, 평면, 초평면(차원이 3 이상일 때)입니다. 분류용 선형 모델에서는 결정 경계가 입력의 선형 함수입니다. 다른 말로 하면 (이진) 선형 분류기는 선, 평면, 초평면을 사용해서 두 개의 클래스를 구분하는 분류기입니다. 이번 절에서 관련 예제를 살펴보겠습니다.
선형 모델을 학습시키는 알고리즘은 다양한데, 다음의 두 방법으로 구분할 수 있습니다.
- 특정 계수와 절편의 조합이 훈련 데이터에 얼마나 잘 맞는지 측정하는 방법
- 사용할 수 있는 규제가 있는지, 있다면 어떤 방식인지
알고리즘들은 훈련 세트를 잘 학습하는지 측정하는 방법이 각기 다릅니다. 불행하게도 수학적이고 기술적인 이유로, 알고리즘들이 만드는 잘못된 분류의 수를 최소화하도록 w와 b를 조정하는 것은 불가능합니다. 12 많은 애플리케이션에서 앞 목록의 첫 번째 항목(손실 함수loss funtion라 합니다)에 대한 차이는 크게 중요하지 않습니다.
가장 널리 알려진 두 개의 선형 분류 알고리즘은 linear_model.LogisticRegression에 13 구현된 로지스틱 회귀logistic regression와 svm.LinearSVC(SVC는 support vector classifier의 약자입니다)에 14 구현된 선형 서포트 벡터 머신support vector machine입니다. LogisticRegression은 이름에 ‘Regression(회귀)’이 들어가지만 회귀 알고리즘이 아니라 분류 알고리즘이므로 LinearRegression과 혼동하면 안 됩니다.
forge 데이터셋을 사용하여 LogisticRegression과 LinearSVC 모델을 만들고 이 선형 모델들이 만들어낸 결정 경계를 그림으로 나타내보겠습니다.
In[41]:
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
X, y = mglearn.datasets.make_forge()
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
for model, ax in zip([LinearSVC(), LogisticRegression()], axes):
clf = model.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5, ax=ax, alpha=.7)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{}".format(clf.__class__.__name__))
ax.set_xlabel("특성 0")
ax.set_ylabel("특성 1")
axes[0].legend()
그림 2-15 forge 데이터셋에 기본 매개변수를 사용해 만든 선형 SVM과 로지스틱 회귀 모델의 결정 경계
이 그림은 이전처럼 forge 데이터셋의 첫 번째 특성을 x 축에 놓고 두 번째 특성을 y 축에 놓았습니다. LinearSVC와 LogisticRegression으로 만든 결정 경계가 직선으로 표현되었고 위쪽은 클래스 1, 아래쪽은 클래스 0으로 나누고 있습니다. 다르게 말하면 새로운 데이터가 이 직선 위쪽에 놓이면 클래스 1로 분류될 것이고 반대로 직선 아래쪽에 놓이면 클래스 0으로 분류될 것입니다.
이 두 모델은 비슷한 결정 경계를 만들었습니다. 그리고 똑같이 포인트 두 개를 잘못 분류했습니다. 회귀에서 본 Ridge와 마찬가지로 이 두 모델은 기본적으로 L2 규제를 사용합니다.
LogitsticRegression과 LinearSVC에서 규제의 강도를 결정하는 매개변수는 C입니다. C의 값이 높아지면 규제가 감소합니다. 다시 말해 매개변수로 높은 C 값을 지정하면 LogisticRegression과 LinearSVC는 훈련 세트에 가능한 최대로 맞추려 하고, 반면에 C 값을 낮추면 모델은 계수 벡터(w)가 0에 가까워지도록 만듭니다.
매개변수 C의 작동 방식을 다르게 설명할 수도 있습니다. 알고리즘은 C의 값이 낮아지면 데이터 포인트 중 다수에 맞추려고 하는 반면, C의 값을 높이면 개개의 데이터 포인트를 정확히 분류하려고 노력할 것입니다. 다음은 LinearSVC를 사용한 예입니다(그림 2-16).
In[42]:
mglearn.plots.plot_linear_svc_regularization()

그림 2-16 forge 데이터셋에 각기 다른 C 값으로 만든 선형 SVM 모델의 결정 경계
왼쪽 그림은 아주 작은 C 값 때문에 규제가 많이 적용되었습니다. 클래스 0의 대부분은 아래에 있고 클래스 1의 대부분은 위에 있습니다. 규제가 강해진 모델은 비교적 수평에 가까운 결정 경계를 만들었고 잘못 분류한 데이터 포인트는 두 개입니다. 중간 그림은 C 값이 조금 더 크며 잘못 분류한 두 샘플에 민감해져 결정 경계가 기울어졌습니다. 오른쪽 그림에서 C 값을 아주 크게 하였더니 결정 경계는 더 기울었고 마침내 클래스 0의 모든 데이터 포인트를 올바로 분류했습니다. 이 데이터셋의 모든 포인트를 직선으로는 완벽히 분류할 수 없기에 클래스 1의 포인트 하나는 여전히 잘못 분류되었습니다. 오른쪽 그림의 모델은 모든 데이터 포인트를 정확하게 분류하려고 애썼지만 클래스의 전체적인 배치를 잘 파악하지 못한 것입니다. 다시 말해 오른쪽 모델은 과대적합된 것 같습니다.
회귀와 비슷하게 분류에서의 선형 모델은 낮은 차원의 데이터에서는 결정 경계가 직선이거나 평면이어서 매우 제한적인 것처럼 보입니다. 하지만 고차원에서는 분류에 대한 선형 모델이 매우 강력해지며 특성이 많아지면 과대적합되지 않도록 하는 것이 매우 중요해집니다.
유방암 데이터셋을 사용해서 LogisticRegression을 좀 더 자세히 분석해보겠습니다.
In[43]:
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=42)
logreg = LogisticRegression().fit(X_train, y_train)
print("훈련 세트 점수: {:.3f}".format(logreg.score(X_train, y_train)))
print("테스트 세트 점수: {:.3f}".format(logreg.score(X_test, y_test)))
Out[43]:
훈련 세트 점수: 0.953 테스트 세트 점수: 0.958
기본값 C=1이 훈련 세트와 테스트 세트 양쪽에 95% 정확도로 꽤 훌륭한 성능을 내고 있습니다. 하지만 훈련 세트와 테스트 세트의 성능이 매우 비슷하므로 과소적합인 것 같습니다. 모델의 제약을 더 풀어주기 위해 C를 증가시켜보겠습니다.
In[44]:
logreg100 = LogisticRegression(C=100).fit(X_train, y_train)
print("훈련 세트 점수: {:.3f}".format(logreg100.score(X_train, y_train)))
print("테스트 세트 점수: {:.3f}".format(logreg100.score(X_test, y_test))
Out[44]:
훈련 세트 점수: 0.972 테스트 세트 점수: 0.965
C=100을 사용하니 훈련 세트의 정확도가 높아졌고 테스트 세트의 정확도도 조금 증가했습니다. 이는 복잡도가 높은 모델일수록 성능이 좋음을 말해줍니다.
이번엔 규제를 더 강하게 하기 위해 기본값(C=1)이 아니라 C=0.01을 사용하면 어떻게 되는지 살펴보겠습니다.
In[45]:
logreg001 = LogisticRegression(C=0.01).fit(X_train, y_train)
print("훈련 세트 점수: {:.3f}".format(logreg001.score(X_train, y_train)))
print("테스트 세트 점수: {:.3f}".format(logreg001.score(X_test, y_test))
Out[45]:
훈련 세트 점수: 0.934 테스트 세트 점수: 0.930
예상대로 이미 과소적합된 모델에서 [그림 2-1]의 왼쪽으로 더 이동하게 되므로 훈련 세트와 테스트 세트의 정확도는 기본 매개변수일 때보다 낮아집니다.
다음으로 규제 매개변수 C 설정을 세 가지로 다르게 하여 학습시킨 모델의 계수를 확인해보겠습니다(그림 2-17).
In[46]:
plt.plot(logreg.coef_.T, 'o', label="C=1")
plt.plot(logreg100.coef_.T, '^', label="C=100")
plt.plot(logreg001.coef_.T, 'v', label="C=0.001")
plt.xticks(range(cancer.data.shape[1]), cancer.feature_names, rotation=90)
plt.hlines(0, 0, cancer.data.shape[1])
plt.ylim(-5, 5)
plt.xlabel("특성")
plt.ylabel("계수 크기")
plt.legend()

그림 2-17 유방암 데이터셋에 각기 다른 C 값을 사용하여 만든 로지스틱 회귀의 계수
노트_ LogisticRegression은 기본으로 L2 규제를 적용하므로 [그림 2-12]에서 Ridge로 만든 모습과 비슷합니다. 규제를 강하게 할수록 계수들을 0에 더 가깝게 만들지만 완전히 0이 되지는 않습니다. 이 그림을 자세히 보면 세 번째 계수(mean perimeter)에서 재미 있는 현상을 확인할 수 있습니다. C=100, C=1일 때 이 계수는 음수지만, C=0.001일 때는 양수가 되며 C=1일 때보다도 절댓값이 더 큽니다. 이와 같은 모델을 해석하면 계수가 클래스와 특성의 연관성을 알려줄 수 있습니다. 예를 들면 높은 “texture error” 특성은 악성인 샘플과 관련이 깊습니다. 그러나 “mean perimeter” 계수의 부호가 바뀌는 것으로 보아 높은 “mean perimeter” 값은 양성이나 악성의 신호 모두가 될 수 있습니다. 그래서 선형 모델의 계수는 항상 의심해봐야 하고 조심해서 해석해야 합니다.
더 이해하기 쉬운 모델을 원한다면 (비록 모델이 몇 개의 특성만 사용하게 되겠지만) L1 규제를 사용하는 것이 좋습니다. 다음은 L1 규제를 사용할 때의 분류 정확도와 계수 그래프입니다(그림 2-18).
In[47]:
for C, marker in zip([0.001, 1, 100], ['o', '^', 'v']):
lr_l1 = LogisticRegression(C=C, penalty="l1").fit(X_train, y_train)
print("C={:.3f}인 l1 로지스틱 회귀의 훈련 정확도: {:.2f}".format(
C, lr_l1.score(X_train, y_train)))
print("C={:.3f}인 l1 로지스틱 회귀의 테스트 정확도: {:.2f}".format(
C, lr_l1.score(X_test, y_test)))
plt.plot(lr_l1.coef_.T, marker, label="C={:.3f}".format(C))
plt.xticks(range(cancer.data.shape[1]), cancer.feature_names, rotation=90)
plt.hlines(0, 0, cancer.data.shape[1])
plt.xlabel("특성")
plt.ylabel("계수 크기")
plt.ylim(-5, 5)
plt.legend(loc=3)
Out[47]:
C=0.001인 l1 로지스틱 회귀의 훈련 정확도: 0.91 C=0.001인 l1 로지스틱 회귀의 테스트 정확도: 0.92 C=1.000인 l1 로지스틱 회귀의 훈련 정확도: 0.96 C=1.000인 l1 로지스틱 회귀의 테스트 정확도: 0.96 C=100.000인 l1 로지스틱 회귀의 훈련 정확도: 0.99 C=100.000인 l1 로지스틱 회귀의 테스트 정확도: 0.98

그림 2-18 유방암 데이터와 L1 규제를 사용하여 각기 다른 C 값을 적용한 로지스틱 회귀 모델의 계수
여기서 볼 수 있듯이, 이진 분류에서의 선형 모델과 회귀에서의 선형 모델 사이에는 유사점이 많습니다. 회귀에서처럼, 모델들의 주요 차이는 규제에서 모든 특성을 이용할지 일부 특성만을 사용할지 결정하는 penalty 매개변수입니다. 15
다중 클래스 분류용 선형 모델
(로지스틱 회귀만 제외하고 16) 많은 선형 분류 모델은 태생적으로 이진 분류만을 지원합니다. 즉 다중 클래스multiclass를 지원하지 않습니다. 이진 분류 알고리즘을 다중 클래스 분류 알고리즘으로 확장하는 보편적인 기법은 일대다one-vs.-rest 17 방법입니다. 일대다 방식은 각 클래스를 다른 모든 클래스와 구분하도록 이진 분류 모델을 학습시킵니다. 결국 클래스의 수만큼 이진 분류 모델이 만들어집니다. 예측을 할 때 이렇게 만들어진 모든 이진 분류기가 작동하여 가장 높은 점수를 내는 분류기의 클래스를 예측값으로 선택합니다.
클래스별 이진 분류기를 만들면 각 클래스가 계수 벡터(w)와 절편(b)을 하나씩 갖게 됩니다. 결국 분류 신뢰도를 나타내는 다음 공식의 결괏값이 가장 높은 클래스가 해당 데이터의 클래스 레이블로 할당됩니다.
w[0] × x[0] + w[1] × x[1] + … + w[p] × x[p] + b
다중 클래스 로지스틱 회귀 이면의 수학은 일대다 방식과는 조금 다릅니다. 하지만 여기서도 클래스마다 하나의 계수 벡터와 절편을 만들며, 예측 방법도 같습니다. 18
세 개의 클래스를 가진 간단한 데이터셋에 일대다 방식을 적용해보겠습니다. 이 데이터셋은 2차원이며 각 클래스의 데이터는 정규분포가우시안 분포를 따릅니다(그림 2-19).
In[48]:
from sklearn.datasets import make_blobs
X, y = make_blobs(random_state=42)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.xlabel("특성 0")
plt.ylabel("특성 1")
plt.legend(["클래스 0", "클래스 1", "클래스 2"])

그림 2-19 세 개의 클래스를 가진 2차원 데이터셋
이 데이터셋으로 LinearSVC 분류기를 훈련해보겠습니다.
In[49]:
linear_svm = LinearSVC().fit(X, y)
print("계수 배열의 크기: ", linear_svm.coef_.shape)
print("절편 배열의 크기: ", linear_svm.intercept_.shape)
Out[49]:
계수 배열의 크기: (3, 2) 절편 배열의 크기: (3,)
coef_ 배열의 크기는 (3, 2)입니다. coef_의 행은 세 개의 클래스에 각각 대응하는 계수 벡터를 담고 있으며, 열은 각 특성에 따른 계수 값(이 데이터셋에서는 두 개)을 가지고 있습니다. intercept_는 각 클래스의 절편을 담은 1차원 벡터입니다.
세 개의 이진 분류기가 만드는 경계를 시각화해보겠습니다(그림 2-20).
In[50]:
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_,
mglearn.cm3.colors):
plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)
plt.ylim(-10, 15)
plt.xlim(-10, 8)
plt.xlabel("특성 0")
plt.ylabel("특성 1")
plt.legend(['클래스 0', '클래스 1', '클래스 2', '클래스 0 경계', '클래스 1 경계',
'클래스 2 경계'], loc=(1.01, 0.3))

그림 2-20 세 개의 일대다 분류기가 만든 결정 경계
훈련 데이터의 클래스 0에 속한 모든 포인트는 클래스 0을 구분하는 직선 위에, 즉 이진 분류기가 만든 클래스 0 지역에 있습니다. 그런데 클래스 0에 속한 포인트는 클래스 2를 구분하는 직선 위, 즉 클래스 2의 이진 분류기에 의해 나머지로 분류됩니다. 또한 클래스 0에 속한 포인트는 클래스 1을 구분하는 직선 왼쪽, 즉 클래스 1의 이진 분류기에 의해서도 나머지로 분류되었습니다. 그러므로 이 영역의 어떤 포인트든 최종 분류기는 클래스 0으로 분류할 것입니다(클래스 0 분류 신뢰도 공식의 결과는 0보다 크고 다른 두 클래스의 경우는 0보다 작을 것입니다).
하지만 그림 중앙의 삼각형 영역은 어떨까요? 세 분류기가 모두 나머지로 분류했습니다. 이 곳의 데이터 포인트는 어떤 클래스로 분류될까요? 정답은 분류 공식의 결과가 가장 높은 클래스입니다. 즉 가장 가까운 직선의 클래스가 될 것입니다.
다음 예는 2차원 평면의 모든 포인트에 대한 예측 결과를 보여줍니다(그림 2-21).
In[51]:
mglearn.plots.plot_2d_classification(linear_svm, X, fill=True, alpha=.7)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_,
mglearn.cm3.colors):
plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)
plt.legend(['클래스 0', '클래스 1', '클래스 2', '클래스 0 경계', '클래스 1 경계',
'클래스 2 경계'], loc=(1.01, 0.3))
plt.xlabel("특성 0")
plt.ylabel("특성 1")

그림 2-21 세 개의 일대다 분류기가 만든 다중 클래스 결정 경계
장단점과 매개변수
선형 모델의 주요 매개변수는 회귀 모델에서는 alpha였고 LinearSVC와 LogisticRegression에서는 C입니다. alpha 값이 클수록, C 값이 작을수록 모델이 단순해집니다. 특별히 회귀 모델에서 이 매개변수를 조정하는 일이 매우 중요합니다. 보통 C와 alpha는 로그 스케일 19 로 최적치를 정합니다. 그리고 L1 규제를 사용할지 L2 규제를 사용할지를 정해야 합니다. 중요한 특성이 많지 않다고 생각하면 L1 규제를 사용합니다. 그렇지 않으면 기본적으로 L2 규제를 사용해야 합니다. L1 규제는 모델의 해석이 중요한 요소일 때도 사용할 수 있습니다. L1 규제는 몇 가지 특성만 사용하므로 해당 모델에 중요한 특성이 무엇이고 그 효과가 어느 정도인지 설명하기 쉽습니다.
선형 모델은 학습 속도가 빠르고 예측도 빠릅니다. 매우 큰 데이터셋과 희소한 데이터셋에도 잘 작동합니다. 수십만에서 수백만 개의 샘플로 이뤄진 대용량 데이터셋이라면 기본 설정보다 빨리 처리하도록 LogisticRegression과 Ridge에 solver=’sag’ 옵션 20 을 줍니다. 다른 대안으로는 여기서 설명한 선형 모델의 대용량 처리 버전으로 구현된 SGDClassifier와 SGDRegressor 21 를 사용할 수 있습니다.
선형 모델의 또 하나의 장점은 앞서 회귀와 분류에서 본 공식을 사용해 예측이 어떻게 만들어지는지 비교적 쉽게 이해할 수 있다는 것입니다. 하지만 계수의 값들이 왜 그런지 명확하지 않을 때가 종종 있습니다. 특히 데이터셋의 특성들이 서로 깊게 연관되어 있을 때 그렇습니다. 그리고 이럴 땐 계수를 분석하기가 매우 어려울 수 있습니다.
선형 모델은 샘플에 비해 특성이 많을 때 잘 작동합니다. 다른 모델로 학습하기 어려운 매우 큰 데이터셋에도 선형 모델을 많이 사용합니다. 그러나 저차원의 데이터셋에서는 다른 모델들의 일반화 성능이 더 좋습니다. 2.3.7절 “커널화 서포트 벡터 머신”에서 선형 모델이 실패하는 예를 보도록 하겠습니다.
–
메서드 연결
모든 scikit-learn의 fit 메서드는 self를 반환합니다. 22 그래서 이 장에서 많이 쓰는 다음 방식으로 코드를 작성할 수 있습니다.
In[52]:
# 한 줄에서 모델의 객체 생성과 학습을 한 번에 실행합니다. logreg = LogisticRegression().fit(X_train, y_train)
fit 메서드의 반환값(즉, self)은 학습된 모델로, 변수 logreg에 할당합니다. 이처럼 메서드 호출을 잇는 것(여기서는 __init__ 23 와 fit)을 메서드 연결method chaining이라고 합니다. scikit-learn에서는 fit과 predict를 한 줄에 쓰는 메서드 연결도 자주 사용합니다.
In[53]:
logreg = LogisticRegression() y_pred = logreg.fit(X_train, y_train).predict(X_test)
심지어 모델의 객체를 만들고, 훈련하고, 예측하는 일을 모두 한 줄에 쓸 수 있습니다.
In[54]:
y_pred = LogisticRegression().fit(X_train, y_train).predict(X_test)
이렇게 짧게 쓰는 것은 그다지 바람직하진 않습니다. 한 줄에 너무 많은 메서드가 들어가면 코드를 읽기 어려워집니다. 더군다나 학습된 로지스틱 회귀 모델은 변수에 할당되지 않아 (예측 결과를 담은 변수만 남습니다) 다른 데이터에 대해 예측하거나 만들어진 모델을 분석할 수 없습니다.
–
–
- 옮긴이_ 머신러닝에서 알고리즘이 주어진 데이터로부터 학습하는 파라미터를 흔히 모델 파라미터라고 부릅니다. 이 책에서는 이런 파라미터를 모델 파라미터, 파라미터 혹은 계수라고 부르고 있습니다. 반대로 모델이 학습할 수 없어서 사람이 직접 설정해 주어야 하는 파라미터를 하이퍼파라미터hyperparameter라고 합니다. 이런 하이퍼파라미터는 파이썬 클래스와 함수에 넘겨주는 인수에 포함되므로 통칭하여 매개변수라고 부르겠습니다.
- 선형 대수를 알고 있다면 쉽게 이해할 수 있습니다.
옮긴이_ 선형대수에서 방정식(훈련 데이터)보다 미지수(모델 파라미터)가 많은 경우를 불충분한 시스템underdetermined system이라고 하며 일반적으로 무수히 많은 해가 존재합니다. - 옮긴이_ 평균제곱오차의 공식은
이고, 여기서 n은 샘플 개수입니다.
- 수학적으로 릿지는 계수의 L2 노름norm의 제곱을 페널티로 적용합니다.
옮긴이_ 평균제곱오차 식에이 추가됩니다. α를 크게 하면 패널티의 효과가 커지고(가중치 감소), α를 작게 하면 그 반대가 됩니다.
- 옮긴이_ Ridge의 객체를 만들 때 아무런 매개변수를 지정하지 않으면 alpha 매개변수의 값이 1.0이 됩니다.
- 옮긴이_ alpha=0.00001로 지정하면 LinearRegression에서 얻은 훈련 세트 점수 0.95, 테스트 세트 점수 0.61과 완전히 같게 됩니다.
- 옮긴이_ 훈련 과정을 여러 번 반복하면서 학습하는 알고리즘에서는 반복의 횟수에 따른 성능 변화를 나타내는 그래프를 학습 곡선이라고 합니다.
- 라쏘는 계수 벡터의 L1 노름을 페널티로 사용합니다. 다른 말로 하면 계수의 절댓값의 합입니다.
옮긴이_ 평균제곱오차 식에 L1 노름이 추가됩니다. 릿지와 마찬가지로 α를 크게 하면 패널티의 효과가 커지고(가중치 감소), α를 작게 하면 그 반대가 됩니다.
- 옮긴이_ Lasso는 L1, L2 규제를 함께 쓰는 엘라스틱넷Elastic-Net 방식에서 L2 규제가 빠진 것입니다. Lasso의 alpha 매개변수는 R의 엘라스틱넷 패키지인 glmnet의 lambda 매개변수와 같은 의미입니다. 이들은 한 특성씩 좌표축을 따라 최적화하는 좌표 하강법coordinate descent 방식을 사용하며 학습 과정이 반복적으로 여러 번 진행되면서 최적의 값을 찾아가게 됩니다. alpha 값을 줄이게 되면 가장 낮은 오차를 찾아가는 이 반복 횟수가 늘어나게 됩니다. 모델이 수행한 반복 횟수는 Lasso 객체의 n_iter_ 속성에 저장되어 있으므로 print(lasso.n_iter_)로 값을 확인할 수 있습니다.
- 옮긴이_ ElasticNet에 있는 l1_ratio 매개변수는 R의 glimnet 패키지의 alpha 매개변수와 동일한 것으로, L1 규제와 L2 규제의 비율을 조정합니다. l1_ratio는 0과 1 사이의 값을 지정하며 L2의 비율은 1 – l1_ratio가 되는 방식입니다. ElasticNet의 규제 식은 alpha × l1_ratio ×
+ 12 × alpha × (1 − l1_ratio) ×
입니다. 이 식의 L1 규제와 L2 규제를 각각
,
란 매개변수로 표현하면
이 됩니다. 이때 alpha =
가 되고 l1_ratio =
가 되므로 필요한 규제의 정도
- 옮긴이_ 보통 로지스틱 회귀는 선형 함수에 시그모이드 함수가 적용된 것으로 종종 표현됩니다. 분류의 기준이 되는 시그모이드 함수의 결괏값은 0.5로 선형 함수가 0일 때이므로 선형 함수를 기준으로도 나타낼 수 있습니다. scikit-learn에서 로직스틱 회귀의 predict 메서드는 선형 함수 값을 계산해주는 decision_function 메서드를 사용해 0을 기준으로 예측을 만들며 시그모이드 함수를 적용한 확률값은 predict_proba 메서드에서 제공합니다.
- 옮긴이_ 분류에서 잘못 분류된 결과를 직접 나타내는 0-1 손실 함수는 완전한 계단 함수입니다. 따라서 대리할 수 있는 다른 함수surrogate loss function를 사용하여 최적화를 수행합니다.
- 옮긴이_ LogisticRegression은 이진 분류에서 로지스틱logistic 손실 함수를 사용하고 다중 분류에서는 교차 엔트로피cross-entropy 손실 함수를 사용합니다.
- 옮긴이_ LinearSVC 클래스의 기본값은 제곱 힌지squared hinge 손실 함수를 사용합니다.
- 옮긴이_ LogisticRegression과 LinearSVC의 penalty 매개변수에 설정할 수 있는 값은 일부 특성만 사용하게 되는 L1 규제를 나타내는 l1과 전체 특성을 모두 사용하는 L2 규제의 l2입니다.
- 옮긴이_ 로지스틱 회귀는 소프트맥스softmax 함수를 사용한 다중 클래스 분류 알고리즘을 지원합니다.
- 옮긴이_ 또는 one-vs.-all이라고도 합니다. LogisticRegression과 LinearSVC에 있는 multi_class 매개변수의 기본값이 일대다를 의미하는 “ovr”입니다.
- 옮긴이_ 다중 클래스 로지스틱 회귀를 위한 공식은
입니다. i번째 데이터 포인트
의 출력
가 클래스 c일 확률
는 K개의 클래스에 대한 각각의 계수 W를 데이터 포인트에 곱하여 지수함수를 적용한 합으로 클래스 c에 대한 값을 나누어 계산합니다. 보통 소프트맥스 함수의 표현에서 수식의 간소함을 위해 절편(b)은 계수 벡터 W에 포함되어 있는 것으로 나타냅니다. 따라서 다중 클래스 로지스틱 회귀에서도 클래스마다 계수 벡터와 절편이 있습니다.
- 옮긴이_ 보통 자릿수가 바뀌도록 10배씩 변경합니다. 즉 0.01, 0.1, 1, 10 등입니다.
- 옮긴이_ sag는 Stochastic Average Gradient descent(확률적 평균 경사 하강법)의 약자로서 경사 하강법과 비슷하지만, 반복이 진행될 때 이전에 구한 모든 경사의 평균을 사용하여 계수를 갱신합니다. scikit-learn 0.19 버전에서 sag의 성능을 향상시킨 saga 알고리즘이 추가되었습니다. 자세한 내용은 옮긴이의 블로그(https://goo.gl/TLyqdo)를 참고하세요.
- 옮긴이_ SGD 는 ‘Stochastic Gradient Descent’(확률적 경사 하강법)의 약자입니다.
- 옮긴이_ 파이썬에서 self는 호출된 메서드를 정의한 객체 자신을 나타냅니다.
- 옮긴이_ 파이썬에서 __init__ 메서드는 객체가 생성될 때 자동으로 호출되는 특수한 메서드(생성자)입니다.
–
2.3.2 k-최근접 이웃 | 목차 | 2.3.4 나이브 베이즈 분류기
–

안녕하세요. 한가지 여쭙겠습니다.
전자책을 구매하려 하는데 최근에 수정된 사항이 전자책에 바로바로 업데이트가 되는지요?
좋아요좋아요
안녕하세요. 전자책도 책이 중쇄될 때 에러타가 반영됩니다. 이 책의 개정판 에러타는 다음 주소에 있는데요. https://tensorflow.blog/%EA%B0%9C%EC%A0%95%ED%8C%90-%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EB%9D%BC%EC%9D%B4%EB%B8%8C%EB%9F%AC%EB%A6%AC%EB%A5%BC-%ED%99%9C%EC%9A%A9%ED%95%9C-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D/ 최근(2쇄) 전자책에는 30, 31번이 포함되어 있지 않습니다. 양해 부탁드립니다.
좋아요좋아요
감사합니다.
좋아요Liked by 1명
죄송한데 coef_.T 가 뭔가요…
일반적인 coef_와 어떤 차이가 있는지 알고 싶습니다…ㅠ
좋아요좋아요
안녕하세요. coef_.T 는 coef_ 행렬의 전치 행렬을 반환합니다. 감사합니다.
좋아요좋아요
plt.plot(line, -(line * coef[0] + intercept) / coef[1]
이 선형식을 이해해보자면,, y = -(x*W1 + B)/W2 이 되는 것 아닌가요…?
y = xW + B 형태로 작성되어야 한다고 생각했는데 답변해주시면 너무 감사하겠습니다.
제 생각은..
plt.plot(line, line*coef[0]+line*coef[1] + intercept)
이런 사고를 해봤는데,, 답변주시면 감사하겠습니다 ㅠ
좋아요좋아요
안녕하세요. 이 그래프는 특성과 타깃을 그리는 그래프가 아니라 두 개의 특성으로 이루어진 평면이기 때문입니다. 감사합니다.
좋아요좋아요
감사합니다.
좋아요좋아요