2.3.5 결정 트리 | 목차 | 2.3.7 커널 서포트 벡터 머신
–
앙상블ensemble은 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법입니다. 머신러닝에는 이런 종류의 모델이 많지만, 그중 두 앙상블 모델이 분류와 회귀 문제의 다양한 데이터셋에서 효과적이라고 입증되었습니다. 랜덤 포레스트random forest와 그래디언트 부스팅gradient boosting 결정 트리는 둘 다 모델을 구성하는 기본 요소로 결정 트리를 사용합니다.
랜덤 포레스트
앞서 확인한 것처럼 결정 트리의 주요 단점은 훈련 데이터에 과대적합되는 경향이 있다는 것입니다. 랜덤 포레스트는 이 문제를 회피할 수 있는 방법입니다. 랜덤 포레스트는 기본적으로 조금씩 다른 여러 결정 트리의 묶음입니다. 랜덤 포레스트의 아이디어는 각 트리는 비교적 예측을 잘 할 수 있지만 데이터의 일부에 과대적합하는 경향을 가진다는 데 기초합니다. 예컨대 잘 작동하되 서로 다른 방향으로 과대적합된 트리를 많이 만들면 그 결과를 평균냄으로써 과대적합된 양을 줄일 수 있습니다. 이렇게 하면 트리 모델의 예측 성능이 유지되면서 과대적합이 줄어드는 것이 수학적으로 증명되었습니다.
이런 전략을 구현하려면 결정 트리를 많이 만들어야 합니다. 각각의 트리는 타깃 예측을 잘 해야 하고 다른 트리와는 구별되어야 합니다. 랜덤 포레스트는 이름에서 알 수 있듯이 트리들이 달라지도록 트리 생성 시 무작위성을 주입합니다. 랜덤 포레스트에서 트리를 랜덤하게 만드는 방법은 두 가지 입니다. 트리를 만들 때 사용하는 데이터 포인트를 무작위로 선택하는 방법과 분할 테스트에서 특성을 무작위로 선택하는 방법입니다. 이 방식들을 자세히 살펴보겠습니다.
랜덤 포레스트 구축
랜덤 포레스트 모델을 만들려면 생성할 트리의 개수를 정해야 합니다(RandomForestRegressor나 RandomForestClassifier의 n_estimators 매개변수). 여기에서는 트리가 10개 필요하다고 가정하겠습니다. 이 트리들은 완전히 독립적으로 만들어져야 하므로 알고리즘은 각 트리가 고유하게 만들어지도록 무작위한 선택을 합니다. 트리를 만들기 위해 먼저 데이터의 부트스트랩 샘플bootstrap sample을 생성합니다. 다시 말해 n_samples개의 데이터 포인트 중에서 무작위로 데이터를 n_samples 횟수만큼 반복 추출합니다(한 샘플이 여러 번 중복 추출될 수 있습니다). 이 데이터셋은 원래 데이터셋 크기와 같지만, 어떤 데이터 포인트는 누락될 수도 있고(대략 1/3 정도 1 ) 어떤 데이터 포인트는 중복되어 들어 있을 수 있습니다.
예를 들면 리스트 [‘a’, ‘b’, ‘c’, ‘d’]에서 부트스트랩 샘플을 만든다고 해보겠습니다. 가능한 부트스트랩 샘플은 [‘b’, ‘d’, ‘d’, ‘c’]도 될 수 있고 [‘d’, ‘a’, ‘d’, ‘a’]와 같은 샘플도 만들어질 수 있습니다.
그다음 이렇게 만든 데이터셋으로 결정 트리를 만듭니다. 그런데 우리가 본 결정 트리 알고리즘과 조금 다릅니다. 각 노드에서 전체 특성을 대상으로 최선의 테스트를 찾는 것이 아니고 알고리즘이 각 노드에서 후보 특성을 랜덤하게 선택한 후 이 후보들 중에서 최선의 테스트를 찾습니다. 몇 개의 특성을 고를지는 max_features 매개변수로 조정할 수 있습니다. 후보 특성을 고르는 것은 매 노드마다 반복되므로 트리의 각 노드는 다른 후보 특성들을 사용하여 테스트를 만듭니다.
부트스트랩 샘플링은 랜덤 포레스트의 트리가 조금씩 다른 데이터셋을 이용해 만들어지도록 합니다. 또 각 노드에서 특성의 일부만 사용하기 때문에 트리의 각 분기는 각기 다른 특성 부분 집합을 사용합니다. 이 두 메커니즘이 합쳐져서 랜덤 포레스트의 모든 트리가 서로 달라지도록 만듭니다.
이 방식에서 핵심 매개변수는 max_features입니다. max_features를 n_features로 설정하면 트리의 각 분기에서 모든 특성을 고려하므로 특성 선택에 무작위성이 들어가지 않습니다(하지만 부트스트랩 샘플링으로 인한 무작위성은 그대로입니다). max_features=1로 설정하면 트리의 분기는 테스트할 특성을 고를 필요가 없게 되며 그냥 무작위로 선택한 특성의 임계값을 찾기만 하면 됩니다. 결국 max_features 값을 크게 하면 랜덤 포레스트의 트리들은 매우 비슷해지고 가장 두드러진 특성을 이용해 데이터에 잘 맞춰질 것입니다. max_features를 낮추면 랜덤 포레스트 트리들은 많이 달라지고 각 트리는 데이터에 맞추기 위해 깊이가 깊어지게 됩니다.
랜덤 포레스트로 예측을 할 때는 먼저 알고리즘이 모델에 있는 모든 트리의 예측을 만듭니다. 회귀의 경우에는 이 예측들을 평균하여 최종 예측을 만듭니다. 분류의 경우는 약한 투표 전략을 사용합니다. 즉 각 알고리즘은 가능성 있는 출력 레이블의 확률을 제공함으로써 간접적인 예측을 합니다. 트리들이 예측한 확률을 평균내어 가장 높은 확률을 가진 클래스가 예측값이 됩니다.
랜덤 포레스트 분석
앞서 사용한 two_moon 데이터셋을 가지고 트리 5개로 구성된 랜덤 포레스트 모델을 만들어보겠습니다.
In[69]:
from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import make_moons X, y = make_moons(n_samples=100, noise=0.25, random_state=3) X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42) forest = RandomForestClassifier(n_estimators=5, random_state=2) forest.fit(X_train, y_train)
랜덤 포레스트 안에 만들어진 트리는 estimator_ 속성에 저장됩니다. 각 트리에서 학습된 결정 경계와 이를 취합해 만든 결정 경계를 함께 시각화해보겠습니다(그림 2-33).
In[70]:
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title("트리 {}".format(i))
mglearn.plots.plot_tree_partition(X, y, tree, ax=ax)
mglearn.plots.plot_2d_separator(forest, X, fill=True, ax=axes[-1, -1], alpha=.4)
axes[-1, -1].set_title("랜덤 포레스트")
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
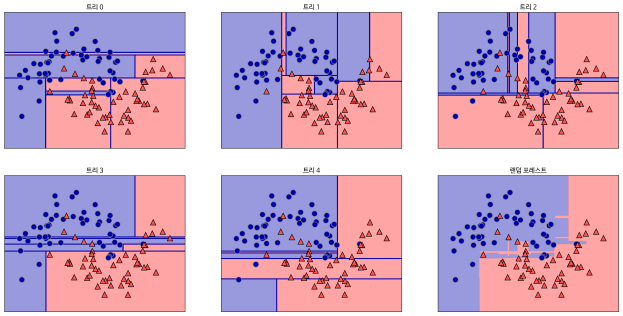
그림 2-33 다섯 개의 랜덤한 결정 트리의 결정 경계와 예측한 확률을 평균내어 만든 결정 경계
다섯 개의 트리가 만든 결정 경계는 확연하게 다르다는 것을 알 수 있습니다. 부트스트랩 샘플링 때문에 한쪽 트리에 나타나는 훈련 포인트가 다른 트리에는 포함되지 않을 수 있어 각 트리는 불완전합니다.
랜덤 포레스트는 개개의 트리보다는 덜 과대적합되고 훨씬 좋은 결정 경계를 만들어줍니다. 실제 애플리케이션에서는 매우 많은 트리를 사용하기 때문에(수백, 수천 개) 더 부드러운 결정 경계가 만들어집니다.
다른 예로 유방암 데이터셋에 100개의 트리로 이뤄진 랜덤 포레스트를 적용해보겠습니다.
In[71]:
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=0)
forest = RandomForestClassifier(n_estimators=100, random_state=0)
forest.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(forest.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(forest.score(X_test, y_test)))
Out[71]:
훈련 세트 정확도: 1.000 테스트 세트 정확도: 0.972
랜덤 포레스트는 아무런 매개변수 튜닝 없이도 선형 모델이나 단일 결정 트리보다 높은 97% 정확도를 내고 있습니다. 단일 결정 트리에서 한 것처럼 max_features 매개변수를 조정하거나 사전 가지치기를 할 수도 있습니다. 하지만 랜덤 포레스트는 기본 설정으로도 좋은 결과를 만들어줄 때가 많습니다.
결정 트리처럼 랜덤 포레스트도 특성 중요도를 제공하는데 각 트리의 특성 중요도를 취합하여 계산한 것입니다. 일반적으로 랜덤 포레스트에서 제공하는 특성 중요도가 하나의 트리에서 제공하는 것보다 더 신뢰할 만합니다. [그림 2-34]를 참고하세요.
In[72]:
plot_feature_importances_cancer(forest)

그림 2-34 유방암 데이터로 만든 랜덤 포레스트 모델의 특성 중요도
그림에서 알 수 있듯이 랜덤 포레스트에서는 단일 트리의 경우보다 훨씬 많은 특성이 0 이상의 중요도 값을 갖습니다. 단일 트리의 결과와 마찬가지로 랜덤 포레스트도 “worst radius” 특성이 매우 중요하다고 보지만, 가장 많은 정보를 가진 특성으로는 “worst perimeter”를 선택했습니다. 랜덤 포레스트를 만드는 무작위성은 알고리즘이 가능성 있는 많은 경우를 고려할 수 있도록 하므로, 그 결과 랜덤 포레스트가 단일 트리보다 더 넓은 시각으로 데이터를 바라볼 수 있습니다.
장단점과 매개변수
회귀와 분류에 있어서 랜덤 포레스트는 현재 가장 널리 사용되는 머신러닝 알고리즘입니다. 랜덤 포레스트는 성능이 매우 뛰어나고 매개변수 튜닝을 많이 하지 않아도 잘 작동하며 데이터의 스케일을 맞출 필요도 없습니다.
기본적으로 랜덤 포레스트는 단일 트리의 단점을 보완하고 장점은 그대로 가지고 있습니다. 만약 의사 결정 과정을 간소하게 표현해야 한다면 단일 트리를 사용할 수 있습니다. 왜냐하면 수십, 수백 개의 트리를 자세히 분석하기 어렵고 랜덤 포레스트의 트리는 (특성의 일부만 사용하므로) 결정 트리보다 더 깊어지는 경향도 있기 때문입니다. 그러므로 비전문가에게 예측 과정을 시각적으로 보여주기 위해서는 하나의 결정 트리가 더 좋은 선택입니다. 대량의 데이터셋에서 랜덤 포레스트 모델을 만들 때 다소 시간이 걸릴 수 있지만 CPU 코어가 많다면 손쉽게 병렬 처리할 수 있습니다. 멀티 코어 프로세서일 때는 (요즘의 모든 컴퓨터는 코어가 둘 이상입니다) n_jobs 매개변수를 이용하여 사용할 코어 수를 지정할 수 있습니다. 사용하는 CPU 코어 개수에 비례해서 속도도 빨라집니다(코어를 두 개 사용하면 랜덤 포레스트의 훈련 속도도 두 배 빨라집니다). 하지만 n_jobs 매개변수를 코어 개수보다 크게 지정하는 것은 별로 도움이 되지 않습니다. n_jobs=-1로 지정하면 컴퓨터의 모든 코어를 사용합니다. 2
유념할 점은 랜덤 포레스트는 이름 그대로 랜덤합니다. 그래서 다른 random_state를 지정하면 (또는 random_state를 지정하지 않으면) 전혀 다른 모델이 만들어집니다. 랜덤 포레스트의 트리가 많을수록 random_state 값의 변화에 따른 변동이 적습니다. 만약 같은 결과를 만들어야 한다면 random_state 값을 고정해야 합니다.
랜덤 포레스트는 텍스트 데이터 같이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않습니다. 이런 데이터에는 선형 모델이 더 적합합니다. 랜덤 포레스트는 매우 큰 데이터셋에도 잘 작동하며 훈련은 여러 CPU 코어로 간단하게 병렬화할 수 있습니다. 하지만 랜덤 포레스트는 선형 모델보다 많은 메모리를 사용하며 훈련과 예측이 느립니다. 속도와 메모리 사용에 제약이 있는 애플리케이션이라면 선형 모델이 적합할 수 있습니다.
중요 매개변수는 n_estimators, max_features이고 max_depth 같은 사전 가지치기 옵션이 있습니다. 3 n_estimators는 클수록 좋습니다. 더 많은 트리를 평균하면 과대적합을 줄여 더 안정적인 모델을 만듭니다. 하지만 이로 인해 잃는 것도 있는데, 더 많은 트리는 더 많은 메모리와 긴 훈련 시간으로 이어집니다. 경험적으로 봤을 때 “가용한 시간과 메모리만큼 많이” 만드는 것이 좋습니다.
앞서 이야기한 것처럼 max_features는 각 트리가 얼마나 무작위가 될지를 결정하며 작은 max_features는 과대적합을 줄여줍니다. 일반적으로 기본값을 쓰는 것이 좋은 방법입니다. 분류는 max_features=sqrt(n_features)이고 회귀는 max_features=n_features입니다. 4 max_features나 max_leaf_nodes 매개변수를 추가하면 가끔 성능이 향상되기도 합니다. 또 훈련과 예측에 필요한 메모리와 시간을 많이 줄일 수도 있습니다.
그래디언트 부스팅 회귀 트리
그래디언트 부스팅 회귀 트리는 여러 개의 결정 트리를 묶어 강력한 모델을 만드는 또 다른 앙상블 방법입니다. 이름이 회귀지만 이 모델은 회귀와 분류 모두에 사용할 수 있습니다. 5 랜덤 포레스트와는 달리 그래디언트 부스팅은 이전 트리의 오차를 보완하는 방식으로 순차적으로 트리를 만듭니다. 기본적으로 그래디언트 부스팅 회귀 트리에는 무작위성이 없습니다. 대신 강력한 사전 가지치기가 사용됩니다. 그래디언트 부스팅 트리는 보통 하나에서 다섯 정도의 깊지 않은 트리를 사용하므로 메모리를 적게 사용하고 예측도 빠릅니다. 그래디언트 부스팅의 근본 아이디어는 이런 얕은 트리 같은 간단한 모델(약한 학습기weak learner라고도 합니다)을 많이 연결하는 것입니다. 각각의 트리는 데이터의 일부에 대해서만 예측을 잘 수행할 수 있어서 트리가 많이 추가될수록 성능이 좋아집니다. 6
그래디언트 부스팅 트리는 머신러닝 경연 대회에서 우승을 많이 차지하였고 업계에서도 널리 사용합니다. 랜덤 포레스트보다는 매개변수 설정에 조금 더 민감하지만 잘 조정하면 더 높은 정확도를 제공해줍니다.
앙상블 방식에 있는 사전 가지치기나 트리 개수 외에도 그래디언트 부스팅에서 중요한 매개변수는 이전 트리의 오차를 얼마나 강하게 보정할 것인지를 제어하는 learning_rate입니다. 학습률이 크면 트리는 보정을 강하게 하기 때문에 복잡한 모델을 만듭니다. n_estimators 값을 키우면 앙상블에 트리가 더 많이 추가되어 모델의 복잡도가 커지고 훈련 세트에서의 실수를 바로잡을 기회가 더 많아집니다.
아래는 유방암 데이터셋을 이용해 GradientBoostingClassifier를 사용한 예입니다. 기본값인 깊이가 3인 트리 100개와 학습률 0.1을 사용하였습니다.
In[73]:
from sklearn.ensemble import GradientBoostingClassifier
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=0)
gbrt = GradientBoostingClassifier(random_state=0)
gbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))
Out[73]:
훈련 세트 정확도: 1.000 테스트 세트 정확도: 0.958
훈련 세트의 정확도가 100%이므로 과대적합된 것 같습니다. 과대적합을 막기 위해서 트리의 최대 깊이를 줄여 사전 가지치기를 강하게 하거나 학습률을 낮출 수 있습니다.
In[74]
gbrt = GradientBoostingClassifier(random_state=0, max_depth=1)
gbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))
Out[74]:
훈련 세트 정확도: 0.991 테스트 세트 정확도: 0.972
In[75]:
gbrt = GradientBoostingClassifier(random_state=0, learning_rate=0.01)
gbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))
Out[75]:
훈련 세트 정확도: 0.988 훈련 세트 정확도: 0.965
이상의 두 방식은 모델의 복잡도를 감소시키므로 예상대로 훈련 세트의 정확도가 낮아졌습니다. 이 예에서 학습률을 낮추는 것은 테스트 세트의 성능을 조금밖에 개선하지 못했지만, 트리의 최대 깊이를 낮추는 것은 모델 성능 향상에 크게 기여했습니다.
다른 결정 트리 기반의 모델처럼 특성의 중요도를 시각화하면 모델을 더 잘 이해할 수 있습니다(그림 2-25). 트리를 100개나 사용했으므로 깊이가 1이더라도 모든 트리를 분석하기는 쉽지 않습니다.
In[76]:
gbrt = GradientBoostingClassifier(random_state=0, max_depth=1) gbrt.fit(X_train, y_train) plot_feature_importances_cancer(gbrt)

그림 2-35 유방암 데이터로 만든 그래디언트 부스팅 분류기의 특성 중요도
그래디언트 부스팅 트리의 특성 중요도 그래프가 랜덤 포레스트의 특성 중요도와 비슷합니다. 다만 그래디언트 부스팅은 일부 특성을 완전히 무시하고 있습니다.
비슷한 종류의 데이터에서 그래디언트 부스팅과 랜덤 포레스트 둘 다 잘 작동합니다만, 보통 더 안정적인 랜덤 포레스트를 먼저 적용하곤 합니다. 랜덤 포레스트가 잘 작동하더라도 예측 시간이 중요하거나 머신러닝 모델에서 마지막 성능까지 쥐어짜야 할 때 그래디언트 부스팅을 사용하면 도움이 됩니다.
대규모 머신러닝 문제에 그래디언트 부스팅을 적용하려면 xgboost 패키지 7 와 파이썬 인터페이스를 검토해보는 것이 좋습니다. 이 글을 쓰는 시점에는 여러 가지 데이터셋에서 scikit-learn의 그래디언트 부스팅 구현보다 빨랐습니다(그리고 튜닝하기도 쉽습니다).
장단점과 매개변수
그래디언트 부스팅 결정 트리는 지도 학습에서 가장 강력하고 널리 사용하는 모델 중 하나입니다. 가장 큰 단점은 매개변수를 잘 조정해야 한다는 것과 훈련 시간이 길다는 것입니다. 다른 트리 기반 모델처럼 특성의 스케일을 조정하지 않아도 되고 이진 특성이나 연속적인 특성에서도 잘 동작합니다. 그리고 트리 기반 모델의 특성상 희소한 고차원 데이터에는 잘 작동하지 않습니다.
그래디언트 부스팅 트리 모델의 중요 매개변수는 트리의 개수를 지정하는 n_estimators와 이전 트리의 오차를 보정하는 정도를 조절하는 learning_rate입니다. 이 두 매개변수는 매우 깊게 연관되며 learning_rate를 낮추면 비슷한 복잡도의 모델을 만들기 위해서 더 많은 트리를 추가해야 합니다. n_estimators가 클수록 좋은 랜덤 포레스트와는 달리 그래디언트 부스팅에서 n_estimators를 크게 하면 모델이 복잡해지고 과대적합될 가능성이 높아집니다. 일반적인 관례는 가용한 시간과 메모리 한도에서 n_estimators를 맞추고 나서 적절한 learning_rate를 찾는 것입니다.
중요한 또 다른 매개변수는 각 트리의 복잡도를 낮추는 max_depth(또는 max_leaf_nodes)입니다. 통상 그래디언트 부스팅 모델에서는 max_depth를 매우 작게 설정하며 트리의 깊이가 5보다 깊어지지 않게 합니다.
–
–
- 옮긴이_ 예를 들어, 100개의 샘플 중 어떤 샘플 하나가 선택되지 않을 확률은 99100입니다. 뽑은 샘플을 제외하지 않고 100번 반복할 때 한 번도 선택되지 않을 확률은 (99100)100=0.366입니다.
- 옮긴이_ n_jobs의 기본값은 1입니다.
- 옮긴이_ 결정 트리와 마찬가지로 max_leaf_nodes, min_samples_leaf, min_samples_split 매개변수도 제공합니다.
- 옮긴이_ max_features의 기본값은 ‘auto’이며 RandomForestClassifier에서는 sqrt(n_features)를, RandomForestRegressor에서는 n_features를 의미합니다.
- 옮긴이_ scikit-learn에서 제공하는 GradientBoostingClassifier와 GradientBoostingRegressor 모두 회귀 트리인 DecisionTreeRegressor를 사용하여 그래디언트 부스팅 알고리즘을 구현하고 있습니다.
- 옮긴이_ 그래디언트 부스팅은 이전에 만든 트리의 예측과 타깃값 사이의 오차를 줄이는 방향으로 새로운 트리를 추가하는 알고리즘입니다. 이를 위해 손실 함수를 정의하고 경사 하강법(gradient descent)을 사용하여 다음에 추가될 트리가 예측해야 할 값을 보정해나갑니다.
- 옮긴이_ xgboost(https://xgboost.readthedocs.io/)는 대용량 분산 처리를 위한 그래디언트 부스팅 오픈 소스 라이브러리로 C++, 파이썬, R, 자바 등 여러 인터페이스를 지원합니다. 최근에는 GPU를 활용하는 플러그인도 추가되었습니다.
–
2.3.5 결정 트리 | 목차 | 2.3.7 커널 서포트 벡터 머신
–

In[72]의 plot_feature_importances_cancer(forest)는 어떤걸 import 해야하나요?
예제를 쥬피터노트북이 아닌 vs code로 하면서 파일 하나씩 처가면서 따라하다 보니
요놈이 어디서 나온놈인지 모르겠네요.
좋아요좋아요
안녕하세요. 그래프를 그리는 코드들은 책 본문에 나와 있지 않고 저자가 따로 모듈을 만들어 제공하고 있습니다. https://github.com/rickiepark/introduction_to_ml_with_python 에서 mglearn 디렉토리를 현재 디렉토리 아래로 복사해서 import mglearn 으로 사용하세요.
좋아요좋아요
안녕하세요. 유익한 글 잘 보았습니다.
다만 제 데이터에서 시각화를 하는 와중에
Number of features of the model must match the input. Model n_features is 500 and input n_features is 2
이런 에러 메시지가 떠서 training, test set을 동일 비율로 나누라, stratify하라는 해결책 등을 보아 따라해도 에러가 해결되지 않습니다.ㅠ
500개의 column과 285개의 observation이 있는 dataset입니다..
좋아요좋아요
안녕하세요. 에러 메시지를 그대로 해석하면 모델은 500개의 특성을 기대하는데 2개의 특성을 가진 데이터를 입력했다는 의미입니다. 사용하는 입력 데이터의 차원을 중간 중간 출력해서 확인해 보세요. 감사합니다.
좋아요좋아요
사용하는 입력데이터의 차원을 어떻게 확인하는지 알 수 있을까요…?
좋아요좋아요
입력 데이터의 차원은 보통 데이터의 특성 개수를 말합니다.
좋아요좋아요
그림 2-33과 같은 그림을 얻고싶어
In[70]까지의 코드와
rf = mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
display(rf)
를 입력하고 실행을 눌렀습니다.
실행은 되나 그림은 어떻게 얻어야하나 모르겠네요…
제 환경은 파이썬3.5, conda3입니다.
좋아요좋아요
아 plt.show()를 이용해서 그림을 얻었습니다. 다만 한글은 네모로 나오네요… 이것을 해결하는 방법이 있을까요?
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title(“트리 {}”.format(i))
mglearn.plots.plot_tree_partition(X, y, tree, ax=ax)
mglearn.plots.plot_2d_separator(forest, X, fill=True, ax=axes[-1, -1], alpha=.4)
axes[-1, -1].set_title(“랜덤 포레스트”)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
from IPython.display import display
rf = mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
display(rf)
plt.show(rf)
좋아요좋아요
https://github.com/rickiepark/introduction_to_ml_with_python/blob/master/preamble.py 파일을 참고하세요. 감사합니다.
좋아요좋아요
안녕하세요, 좋은 포스팅 읽게 해주셔서 감사합니다.
다름이 아니고, 서론에 트리를 만드는 방법을 설명하시면서 분할 테스트에서 특성을 무작위로 선택하는 방법이라 하셨는데, 이게 무슨 말인지 이해가 잘 되지 않아 여쭤보고 싶습니다.
또한 이에 해당하는 적절한 예시가 있으면 설명해주심 감사하겠습니다!!
좋아요좋아요
안녕하세요. 분할에 사용할 대상 특성을 랜덤하게 선택한다는 뜻입니다. 바로 그 아래 설명이 자세히 나와 있습니다. 🙂
좋아요좋아요
안녕하세요. 책 잘 보고 있습니다. 혹시 랜덤 포레스트의 첫 번째 예시에서 트리 5개+랜덤 포레스트가 아닌 랜덤 포레스트의 그래프만을 볼 수 있는 방법이 있나요?
트리 개수를 다르게 해서 결과를 비교해보고 싶습니다.
좋아요좋아요
안녕하세요. 트리의 결정 경계를 그리는 것은 2차원 평면의 모든 점에 대해 예측을 만든 후 contour 함수를 사용합니다. plot_2d_separator 함수의 소스 코드를 참고하세요 https://github.com/rickiepark/introduction_to_ml_with_python/blob/master/mglearn/plot_2d_separator.py#L96
좋아요좋아요