이 글에서 사용한 코드는 깃허브에서 확인할 수 있습니다.

본격 머신러닝 입문서 <[개정판] 파이썬 라이브러리를 활용한 머신러닝> 출간.
이 책은 사이킷런(Scikit-Learn) 라이브러리에 있는 지도학습, 비지도학습, 모델 평가, 특성공학, 파이프라인, 그리드서치 등 머신러닝 프로젝트에 필요한 모든 단계를 다루고 있습니다. 또한 파이썬을 사용한 영문, 한글 텍스트 처리 방법도 포함되어 있습니다! 🙂
온/오프라인 서점에서 판매 중입니다. [YES24] [교보문고] [리디북스] [한빛미디어]
머신러닝이란
기계학습 혹은 머신러닝(Machine Learning)은 컴퓨터가 사전에 미리 프로그램되어 있지 않고 데이터로 부터 패턴을 학습하여 새로운 데이터에 대해 적절한 작업을 수행하는 일련의 알고리즘이나 처리 과정을 말합니다. 데이터를 통해 지식을 얻는 부분은 데이터 마이닝과 비슷하지만 데이터 마이닝은 주로 사람에게 어떤 지식(information or insight)를 제공하는 반면 머신러닝은 학습된 알고리즘으로 새로운 데이터를 처리하는 데 촛점이 맞춰져 있습니다. 이 때문에 머신러닝으로 만들어진 결과에 대해 그 이유를 적절히 설명하지 못할 수도 있습니다.
머신러닝은 사실 여러 분야와 밀접한 관련이 있습니다. 대표적인 분야는 컴퓨터 과학(Computer Science), 통계(Statistics), 데이터 마이닝(Data Mining) 등입니다. 그중에서도 가장 높은 연관성은 컴퓨터 과학 분야일 것입니다. 하지만 회귀 분석 등 여러 알고리즘들이 통계학의 오래된 역사에 많이 의존하고 있습니다. 특별히 통계학 입장에서 바라볼 때 통계적 머신러닝(Statistical Learning)이라고 부르기도 합니다. 통계학이나 컴퓨터 과학보다 데이터 마이닝은 머신러닝과 좀 더 느슨한 관계를 가지고 있다고 보여집니다. 하지만 연관 분석(Association Ruls), 추천 등을 머신러닝의 한 분야로 포함시키는 사례가 종종 있습니다. 최근의 머신러닝 붐에 영향을 받은 것도 있겠지만 명확히 각 분야를 구별하기엔 어려운 점이 많습니다. 정도의 차이는 있겠지만 대체적으로 컴퓨터 과학 쪽의 머신러닝이 비교적 실용적인 접근이 많으며 통계학 쪽의 머신러닝은 이론적이고 확률 기반의 접근이 많습니다. 책을 보거나 강좌를 들을 때 참고하면 좋을 것 같습니다.

그림 1. 머신러닝 관련 분야
머신러닝을 포괄하고 있는 상위 개념은 인공지능(AI) 입니다. 인공지능은 머신러닝이외에도 언어학, 뇌의학, 검색, 로봇틱스 등 다양한 분야가 포함된 커다란 집합체입니다. 지금의 인공지능은 특정 작업에 맞추어 발전되고 있어서 사람이 수행하는 일반적인 지능(General Purpose Intelligence)을 따라 잡으려면 아직 많은 연구가 필요합니다. 그리고 매스미디어에서 많이 듣는 딥러닝(Deep Learning)은 뉴럴 네트워크(Neural Network, 인공신경망) 알고리즘을 이용한 머신러닝의 한 분야로 볼 수 있습니다. 따라서 인공지능 안에 머신러닝이 있고 머신러닝 안에 딥러닝이 있는 거죠.

그림 2. 인공지능과 머신러닝, 딥러닝. 출처: kdnuggets.com
인공지능과 머신러닝 그리고 딥러닝이 활성화된 시기도 조금씩 다릅니다. 오히려 인공지능이 너무 빠르게 관심을 받다가 열기가 식어버려서 나중에 머신러닝과 딥러닝으로 모습을 바꾸어 나타난 것으로 보이기도 합니다. 대체적으로 처음 인공지능이 대두된 것은 1950년대이고 머신러닝은 그보다 훨씬 뒤인 1980년대입니다. 딥러닝은 2010년에나 와서 각광을 받기 시작했습니다. 우리에게도 2000년대 부터 기계학습과 뉴럴 네트워크(인공 신경망)에 대해 접할 기회가 있었지만 지금처럼 널리 알려진 것은 불과 몇년 안된 것 같습니다.
그림 3. 인공지능, 머신러닝, 딥러닝의 시기. 출처: Nvidia Blog
우리에게 필요한 도구들
시작하기 전에 더 설명할 것이 있습니다. 서론이 길지만 조금 참아주세요. 아마 짐작할 수 있겠지만 여기에서 사용할 프로그램 언어는 파이썬(Python)이고 필요한 라이브러리는 넘파이(numpy), 사이킷런(scikit-learn), 맷플롯립(matplotlib) 등입니다. 물론 파이썬말고도 자바 등의 다른 언어로 머신러닝 모델을 만들 수 있습니다. 하지만 몇가지 관점에서 많은 사람들이 주로 파이썬을 선택하고 있습니다.
먼저 파이썬은 범용 언어로서 수치 연산 전용 패키지인 매트랩(matlab)이나 매트랩의 오픈소스 클론인 옥타브(octave) 또는 R 과 달리 머신러닝 연구와 제품 개발에 두루 사용되기에 좋습니다. 또 파이썬은 머신러닝 모델을 만드는 것 이외에 데이터를 미리 가공한다거나 모델을 테스트를 하거나 온라인으로 서비스를 제공하는 등의 작업들을 하는데 필요한 풍부한 도구를 제공합니다. 매트랩이나 옥타브로는 이런 작업을 하기가 쉽지 않습니다. 최근에 각광을 받고 있는 R도 이런 측면에서 많이 자유롭지는 않습니다.
물론 옥타브나 R로 머신러닝 모델을 만들고 만들어진 모델의 설정값(즉 파라메타들)을 이용하여 다른 언어에서 모델을 운영하도록 할 수 있습니다. 하지만 모든 알고리즘이 이런 방식으로 가능하다고 단정하기는 어렵고 머신러닝 라이브러리마다 미묘한 구현의 차이가 있을 수 있으며 언어간에는 실수(부동소숫점) 연산의 정말도 차이 등이 결과에 영향을 미칠 수 있습니다. 그래서 한 언어로 일관성있는 머신러닝 작업과정(pipeline)을 만드는 것이 선호되는 것 같습니다. 한편으로는 다양한 머신러닝 모델을 테스트해 보고 실험을 할 때에 옥타브나 R 같은 패키지가 여전히 널리 사용되고 있습니다.
자바나 C 또는 최근에 나온 수치 분석 전문 언어인 줄리아(julia) 등의 머신러닝 시스템 생태계를 자세히 알지는 못하지만 아마도 이 중에서는 유명한 딥러닝4j(deeplearning4j)나 웨카(Weka)가 있는 자바가 가장 활성화 되어 있는 것 같습니다. 이와 비교하면 파이썬에서는 수치,과학 연산 패키지인 싸이파이(scipy), 머신러닝 라이브러리인 사이킷런(scikit-learn), 다차원 배열 처리를 위한 넘파이(numpy) 등이 거의 파이썬의 공식 라이브러리인양 대접을 받습니다. 파이썬을 사용한 머신러닝 책 중에서 넘파이, 사이킷런을 사용하지 않은 경우를 보지 못했거든요. 일반적으로 다양성이 존중되는 소프트웨어의 생태계에서 이런 현상은 조금 의외입니다. 이제 사이킷런은 파이썬의 대표인 정도를 넘어서 대학의 머신러닝 수업, 각종 온라인 튜토리얼, 기업의 머신러닝 제품등에 정말 많이 사용되고 있습니다.
이런 파이썬의 인기에 힘입어 최근의 딥러닝 라이브러리들도 파이썬 인터페이스를 전면에 내세우고 있습니다. 씨아노(Theano)와 텐서플로우(TensorFlow)가 바로 그들입니다. 특히 텐서플로우는 오픈소스 딥러닝 라이브러리 중에 가장 인기가 높습니다. 최근에는 마이크로소프트가 내놓은 딥러닝 라이브러인 CNTK 의 최신 버전에서도 파이썬 인터페이스를 지원하기 시작했습니다. 이렇게 파이썬 인터페이스를 가장 우선하여 채용하는 이유는 파이썬에 이미 익숙한 많은 연구자들이나 기술자들을 무시할 수 없기 때문이겠죠.
혹 파이썬을 아직 모른다고 해도 너무 큰 걱정은 마세요. 파이썬은 비교적 배우기 쉬운 언어입니다. 서점에 가서 맘에 드는 책을 한권 정도 골라 읽어도 좋고 온라인에 있는 훌륭한 두개의 한글 교재(Think Python, A Byte of Python)을 보아도 됩니다. 정말 금방 배울 수 있습니다. 다만 이 글은 파이썬에 관한 튜토리얼은 아닙니다. 그래서 이미 파이썬을 어느정도 알고 있다고 가정하고 진행하겠습니다.
마지막으로 파이썬 설치 방법에 대해서 언급하려고 합니다. 리눅스나 맥은 기본적으로 운영체제에 파이썬이 설치되어 있습니다. 윈도우에서도 파이썬 공식 홈페이지에서 인스톨러를 다운 받아 파이썬을 설치할 수 있습니다. 하지만 기본으로 설치된 파이썬이나 공식 홈페이지에서 다운 받은 파이썬에는 우리가 사용하려는 머신러닝 라이브러리가 들어 있지 않습니다. 사이파이(scipy)나 사이킷런(scikit-learn) 라이브러리들은 많은 부분이 C 언어로 만들어져 있습니다(파이썬은 C 언어와 궁합이 잘 맞는 편이죠). 그래서 이런 라이브러리들을 설치하려면 컴퓨터에 C 컴파일러가 있어야 합니다. 리눅스라면 조금 낫겠지만 윈도우나 맥 사용자라면 굳이 모험을 권하고 싶지 않네요.
이런 수치, 과학 패키지들을 각 운영체제에 맞게 미리 컴파일해서 제공해 주는 서드파티(third party) 인스톨러가 있습니다. 대표적으로 아나콘다(Anaconda)와 캐노피(Canopy), 액티브파이썬(ActivePython)이 있습니다. 파이썬 라이브러리들이 버전 업데이트가 되면 며칠이 지나기 전에 컴파일된 패키지가 제공되므로 리눅스 사용자도 이런 인스톨러를 마다할 이유가 없습니다. 이 중에서도 어느 인스톨러를 사용해도 큰 지장은 없지만 많은 사람들이 선호하고 있는 아나콘다를 추천해 드립니다. 이 글에서는 아나콘다를 사용하여 예제를 진행하도록 하겠습니다.
아나콘다를 설치하고 IPython 쉘을 시작했다면 넘파이와 맷플롯립을 한번에 임포트할 수 있는 pylab 명령을 사용할 수 있습니다(이글에서 특별한 언급이 없으면 소스 코드는 모두 ipython 에서 실행하는 것이고 달러 $ 기호로 시작하는 것은 운영체제 커맨드 라인에서 실행하는 명령입니다).
$ ipython %pylab
pylab 명령을 실행하면 자동으로 넘파이는 np 란 이름으로 임포트하고 맷플롯립은 plt 란 이름으로 임포트해 줍니다.
만약 리눅스에서 아나콘다를 사용한다면 CPU 버전의 텐서플로우를 conda 명령으로 설치할 수 있습니다. 현재 conda 명령으로 설치할 수 있는 텐서플로우 버전은 0.10.0RC 입니다.
$ conda install tensorflow ...
머신러닝 알고리즘 분류
머신러닝과 관련된 책이나 자료를 보면 알고리즘의 종류를 분류하는 것 부터 시작하곤 합니다. 여기서도 한번 그렇게 해 보겠습니다. 하지만 분류 방식이 한가지만 있는 것은 아닙니다. 가장 널리 알려진 그리고 고전적인 분류 방식은 학습의 방식을 이용한 것입니다. 정답을 알고 있는 샘플 데이터-머신러닝에서는 보통 학습 데이터 혹은 훈련 데이터(training data)라고 부릅니다-를 이용하여 머신러닝 모델을 학습시키는 방식을 지도학습(supervised learning)이라고 하고 샘플 데이터가 있지만 데이터에 대해 정답을 가지고 있지 못한 경우에 하는 방식을 비지도학습(unsupervised learning)이라고 합니다. 이 두가지를 감독학습, 비감독학습 이라고도 부르기도 하는데 뭐라 부르던 중요한 것은 아닙니다.
미리 준비된 샘플 데이터를 이용하여 모델을 만들어서 새로운 데이터가 주어졌을 때 예상치를 맞추거나 종류를 판별하는 등의 작업이 주로 지도학습입니다. 예를 들면 주식 시장의 주가를 예측한다거나 스팸 이메일을 분류하는 등의 일입니다. 비지도학습은 정답을 모르는 샘플 데이터를 유사한 것들끼리 모으는 군집(clustering)화가 대표적인 예입니다. 지도학습이나 비지도학습외에 강화학습(reinforcement learning)도 머신러닝의 한 종류로 구별되어 불리곤 합니다. 강화학습은 알고리즘이 수행한 결과에 따라 수행 방식을 조절해 가는 것으로 언뜻 보면 지도학습과 유사한 면이 있습니다. 하지만 강화학습이 받은 결과는 지도학습에서 말하는 준비된 정답이 아니고 알고리즘이 잘 수행했는지를 피드백 받는 것입니다. 강화학습은 일반적인 머신러닝 책이나 강의에 포함되어 있지 않고 별도의 책이나 커리큘럼을 가지고 있는 것이 보통입니다. 이 글에서는 강화학습에 대해서는 더 깊이 들어가지 않도록 하겠습니다.
이런 분류 방식에는 딥러닝이 들어가지는 않습니다. 앞서도 언급했지만 딥러닝은 주로 뉴럴 네트워크 알고리즘을 사용하는 머신러닝의 한 부류를 일컫는 말입니다. 뉴럴 네트워크를 사용하여 지도학습, 비지도학습, 강화학습 모두 가능합니다. 즉 학습 방법에 대한 분류는 알고리즘으로 구분하는 것과는 조금 다른 거죠. 그리고 뉴럴 네트워크를 인공 신경망으로 종종 번역하여 부릅니다. 하지만 대부분의 기술자들이 그냥 뉴럴 네트워크라고 부르기도 하고 뉴럴 네트워크의 다양한 변종을 굳이 모두 번역하려면 어색하므로 우리도 그냥 뉴럴 네트워크라고 부르겠습니다.
파이썬(Python)의 유명한 머신러닝 라이브러리 사이킷런(scikit-learn)의 알고리즘 치트시트(cheat-sheet)를 보면 머신러닝 알고리즘을 나누는 큰 분류를 엿볼 수 있습니다. 여기에서는 회귀 분석(Regression), 분류(Classification), 군집(Clustering), 차원감소(Dimensionality Reduction)으로 크게 구분하고 있습니다. 사이킷런에서는 뉴럴 네트워크가 최근 0.18.0 버전에 본격적으로 추가되기 시작했는데 이 치트 시트에는 미처 포함되지 못한 것 같습니다.

그림 4. 사이킷런 치트시트. 출처: scikit-learn.org
이 시트를 만든 사람은 사이킷런의 코어 개발자이고 뉴욕 대학교의 리서치 엔지니어인 안드리아스 뮐러(Andreas C. Müller)입니다. 이 치트 시트는 데이터의 종류와 크기에 따라 어떤 알고리즘을 선택해야하는 지 가이드를 해주고 있습니다. 하지만 반드시 이 치트 시트를 따라야 한다고 하기보다는 알고리즘을 선택하는데 도움을 줄 수 있는 여러가지 중 한가지 참고 사항으로 여기면 좋을 것 같습니다.
이 글은 머신러닝을 처음 만나는 독자를 대상으로 쓰여졌으므로 이 치트 시트에 있는 알고리즘 중 가장 쉬운 간단한 선형 회귀 분석(Linear Regression)의 예를 이용하여 몇가지 머신러닝의 주제를 다루어 보도록 하겠습니다. 그리고 다음에는 뉴럴 네트워크를 사용하여 손글씨 숫자를 분류(Classification)하는 예제를 풀어 보도록 하겠습니다.
회귀 분석은 오래전 통계학자들에 의해 개발되고 발전되어 온 알고리즘입니다. 한 백년 전 즈음에 프란시스 갈톤(Francis Galton)이라는 통계학자가 아버지와 자식들의 키의 관계를 조사하다가 아버지의 키가 큰데 자식들의 키는 아버지보다 작아지는 경향이 있다는 것을 발견했습니다. 그래서 자식들의 키가 평균으로 회귀(regression)한다고 표현했고 이로 부터 회귀 분석이라는 용어가 쓰이게 되었다고 합니다. 네 물론 회귀라는 단어가 실제 이 알고리즘을 잘 설명할 수 없다는 걸 압니다. 하지만 너무 오랫동안 굳어져 내려와서 어쩔 도리가 없네요.
사실 회귀 분석은 연속된 수치 값을 예측하는 데 사용되는 알고리즘입니다. 예를 들면 주변국가의 온도를 이용해서 우리나라의 내일 온도를 예측해 볼 수도 있습니다(실제로는 이렇게 예측할리가 만무하겠지만요). 여기서 온도라는 값은 32.3°C, 29.8°C 와 같이 헤아릴 수 없큼 많은 무한한 수들이 가능합니다. 그러다 보니 예측 값이 32.3°C 이던지 32.4°C 이던지 작은 값의 차이는 큰 문제가 되지 않는 것이 보통입니다.
선형 회귀 분석은 선형 함수(linear function)을 이용하여 회귀 분석을 수행하는 것을 말합니다. 선형 함수는 입력과 출력의 관계가 직선적(linear)인 우리가 중학교 때 배운 1차 함수입니다. 예를 들면 기울기가 2 이고 절편이 3 인 1 차 함수는 
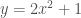

당뇨병 데이터
머신러닝을 공부하려면 연습할 샘플 데이터가 있어야 합니다. 자신의 업무에서 발생한 데이터를 이용해서 샘플 데이터를 만들어도 되지만 보통은 인터넷에 공개되어 널리 사용되는 데이터셋을 사용하곤 합니다. 대부분의 머신러닝 책들도 잘 알려진 몇몇 데이터셋를 활용하여 예제를 만들고는 합니다. 이런 방식이 손쉽기도 하지만 새로운 모델을 만들어서 다른 사람의 결과와 비교할 때 데이터셋이 같다면 직접 비교가 가능하기 때문이기도 합니다. 가장 유명한 머신러닝 데이터 저장소는 얼바인 캘리포니아 주립대(UC Irvine) 머신러닝 저장소입니다. 이 저장소에는 지금도 새로운 데이터가 계속 추가되고 있습니다. 얼바인 저장소 이외에도 구글 같은 회사들도 딥러닝 연구에 필요한 양질의 데이터를 많이 공개하고 있습니다.
우리는 데이터 저장소에서 데이터를 다운로드 받지 않고 사이킷런을 이용하여 샘플 데이터를 바로 로드하도록 하겠습니다. 사이킷런은 라이브러리 안에 잘 알려진 몇개의 데이터셋을 기본으로 내장하고 있거든요. 그래서 연습할 때 얼바인 저장소에 가지 않고서도 바로 꺼내 쓸 수가 있습니다. 아래 코드가 당뇨병 데이터셋을 넘파이 변수로 읽어 들이는 명령입니다.
from sklearn import datasets diabetes = datasets.load_diabetes() print(diabetes.data.shape, diabetes.target.shape)
(442, 10) (442, )
sklearn.datasets 에서 받은 데이터는 data 와 target 속성을 가지고 있습니다. diabetes.data 는 모델을 훈련할 때 쓰이는 데이터입니다. 그래서 흔히 훈련(training) 데이터 또는 학습 데이터라고 부릅니다. diabetes.target 과 diabetes.data 모두 넘파이 배열입니다. shape 속성은 넘파이에서 제공하는 것으로 배열의 차원(크기)를 알려 줍니다. diabetes.data 의 크기는 442×10 으로 442개의 행(row)과 10개의 열(column)로 이루어져 있습니다. 즉 2차원 배열이죠. diabetes.target 은 훈련 데이터인 diabetes.data 를 사용해 맞출 정답 데이터를 가지고 있습니다. diabetes.data 의 갯수가 442개 이므로 diabetes.target 의 갯수도 442개여야 겠죠? 즉 diabetes.target 은 442개 요소를 가진 1차원 배열입니다.
이 데이터는 당뇨병 환자를 1년간 추적해서 나이, 성별, 혈액성분에 따라 얼마나 병이 악화되었는지를 추적한 것입니다. 이 데이터에서 병이 얼마나 진척되었는지를 나타내는 지표인 diabetes.target 이 우리가 예측할 값입니다. diabetes.target 에 들어있는 값을 살짝 보겠습니다. 파이썬에서 배열의 일부를 끊어서 볼때는 슬라이스 연산자 : 를 사용하면 편리합니다. 아래는 맨 처음부터 10개 까지의 배열 요소만 프린트하는 코드입니다.
print(diabetes.target[:10])
[ 151. 75. 141. 206. 135. 97. 138. 63. 110. 310.]
다음은 diabetes.data 넘파이 배열의 안의 내용을 5개만 살펴 보겠습니다.
print(diabetes.data[:5])
[[ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613] [-0.00188202 -0.04464164 -0.05147406 -0.02632783 -0.00844872 -0.01916334 0.07441156 -0.03949338 -0.06832974 -0.09220405] [ 0.08529891 0.05068012 0.04445121 -0.00567061 -0.04559945 -0.03419447 -0.03235593 -0.00259226 0.00286377 -0.02593034] [-0.08906294 -0.04464164 -0.01159501 -0.03665645 0.01219057 0.02499059 -0.03603757 0.03430886 0.02269202 -0.00936191] [ 0.00538306 -0.04464164 -0.03638469 0.02187235 0.00393485 0.01559614 0.00814208 -0.00259226 -0.03199144 -0.04664087]]
배열 안의 배열, 즉 2차원 배열로 되어 있는 것을 확인할 수 있으며 첫번째 배열 요소는 10개의 실수로 이루어져 있습니다. 행렬로 비유하면 이 10개의 실수가 하나의 행(row)을 이루고 있습니다. 그리고 각 10개의 요소가 열(column)을 대표합니다. 각 열은 나이(age), 성별(sex), 체질량(bmi), 혈압(bp) 그리고 혈액 검사 내용 s1~s6 을 나타냅니다. 그런데 성별 값이 좀 이상하게 들어가 있죠? 원래 성별 값은 1(여), 2(남) 이렇게 들어가 있는데 이 값을 평균이 0이(zero mean) 되도록 바꾸고 l2 정규화를 한 것입니다. 좀 복잡한데 중요한 건 0.05068012가 남자이고 -0.04464164가 여자라는 것입니다. 즉 당연하게도 성별은 두 종류의 숫자만 나타나겠죠. 다른 데이터의 경우도 모두 마찬가지로 정규화한 것입니다. s1에서 s6까지의 혈액 데이터가 의학적으로 어떤 의미인지를 아는 게 우리의 관심사는 아니고 여기서 사용할 것도 아니므로 자세한 내용을 확인하진 않겠습니다.
우리가 예측할 값과 예측을 위해 사용되는 값을 부르는 방법도 여러가지 입니다. 전자를 종속변수, 응답변수, 출력값(output) 이라고 부르고 후자를 독립변수, 예측변수, 특성(feature), 입력값(input) 등으로 부릅니다. 종속변수나 독립변수 같은 용어는 약간은 수학적이고 통계학적인 어휘입니다. 요즘엔 머신러닝 기술자들이나 딥러닝 연구자들이 출력값, 입력값 혹은 특성이란 용어를 많이 사용합니다. 보통 머신러닝 책들이 회귀분석을 설명할 때 입력값, 출력값이란 용어는 잘 쓰지 않지만 여기서는 간단하게 입력값, 출력값 이라고 부르려고 합니다.
10개의 컬럼 중 3번째인 체질량 지수와 출력값을 각각 x, y 로 하는 2차원 평면에 데이터를 점으로 나타내 보도록 하겠습니다. 이런 그래프를 산점도(Scatter Plot)라고 부릅니다. 그냥 평면에 점 찍은거죠.
plt.scatter(diabetes.data[:,2], diabetes.target)
plt.xlabel('x')
plt.ylabel('y')

그림 5. 체질량 산점도 그래프
그래프에서 볼 수 있듯이 체질량 지수(x)가 클수록 병이 악화될 가능성(y)이 높네요. 당연하겠죠? 이 두개의 변수의 관계를 하나의 직선으로 표현한다면 어느 부분에 그리면 좋을까요?



너무 위로 치우쳐도 안되고 너무 아래도 아닌 점들이 많이 찍혀 있는 중간 어디쯤을 지나는 직선일 것입니다. 우리가 이 산점도를 잘 대변할 수 있는 직선을 긋는다면 그 직선의 방정식이 이 그림에 대한 선형 회귀 모델이 됩니다. 그리고 누군가 당뇨병이 걸린 사람의 체질량 지수를 알려주면 그 사람이 1년뒤에 어느정도 병이 악화될 지 묻는 질문에 대답을 해줄 수 있을 것입니다. 모델의 직선 방정식에 체질량 지수를 넣어서 답을 구하면 되는 거죠.
여기서 용어를 하나더 정리하고 넘어 가겠습니다. 선형 회귀 모델의 방정식을 표현하는 데 여러가지 방식을 사용하고 있습니다. 보통은 학교에서 배웠던 기울기나 절편이란 말은 잘 안쓰죠.
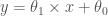
이렇게 세타(theta) 기호를 사용하여 나타내기도 합니다. 이 경우 절편은 0 첨자를 붙이는 게 보통입니다. 세타 대신에 가중치(weight)를 의미하는 


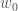

자 그럼 이제 어떻게
참고자료:
- http://scikit-learn.org/stable/modules/preprocessing.html
- Bradley Efron, Trevor Hastie, Iain Johnstone and Robert Tibshirani, Least Angle Regression, 2002
- http://www4.stat.ncsu.edu/~boos/var.select/diabetes.html
하나의 뉴런
우리가 위에서 정의한 식 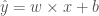

그림 6. 하나의 뉴런
실제 뉴런과 그리 비슷하지는 않지만 양해해 주세요. 이 뉴런의 출력은 

diabetes.target 의 값을 수식에 표시할 때 

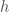
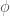
이 뉴런의 계산식을 파이썬 클래스를 만들어 표현해 보겠습니다. 입력값이 왼쪽에서 들어와 오른쪽 출력으로 나가는 방향을 정방향(forward pass)이라고 하겠습니다. 정방향 계산은 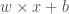
set_params 함수와 정방향 계산을 하는 함수 forpass 를 아래와 같이 만들 수 있습니다.
class SingleNeuron(object):
def __init__(self):
self._w = 0 # 가중치 w
self._b = 0 # 바이어스 b
self._x = 0 # 입력값 x
def set_params(self, w, b):
"""가중치와 바이어스를 저장합니다."""
self._w = w
self._b = b
def forpass(self, x):
"""정방향 수식 w * x + b 를 계산하고 결과를 리턴합니다."""
self._x = x
_y_hat = self._w * self._x + self._b
return _y_hat
이 클래스를 이용해 하나의 가상의 뉴런을 만들고 w, b, x 에 아무 값이나 넣어서 정방향 계산을 해 보겠습니다.
n1 = SingleNeuron() n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅 print(n1.forpass(3)) # x 에 3 을 입력
16
set_params 함수는 뉴런의 가중치 w 와 바이어스 b 를 셋팅하는 함수이고 forpass 는 입력값 x 를 받아 출력 _y_hat 을 계산합니다. 이 뉴런으로 당뇨병 데이터에서 체질량과 병의 증세 간의 관계를 잘 나타내기 위해서 w 와 b 를 적절하게 변경해야 할 것입니다. 반대로 생각하면 w 와 b 를 변경했을 때 입력과 출력의 관계가 어떻게 달라지는 가를 살펴 볼 필요가 있습니다.
예를 들어 입력값이 1일 때 타겟값(w 와 b 를 변경해야 합니다. 반대로 정방향 계산이 110이 나왔다면 타겟값 100 보다 크므로 w 와 b 가 출력값을 줄일 수 있는 방향으로 바뀌어져야 합니다.
w 와 b 를 어떻게 바꿀 때 출력이 증가하는지 감소하는지를 아는 방법은 사실 매우 간단합니다. w 나 b 를 조금 변경시켜서 출력의 변화를 살펴보면 되거든요.
n1.set_params(6, 1) # w, b 를 6, 1 로 셋팅 print(n1.forpass(3)) # x 에 3 을 입력
19
w 를 1 만큼 증가시키니 출력이 16 에서 19 로 늘어 났습니다. 이 뉴런이 계산하는 정방향의 공식은 x 가 양수일 때 w 가 증가하면 출력이 늘어납니다. 반대로 x 가 음수일 때는 w 가 증가하면 오히려 출력이 줄어들죠(더 큰 음수가 되므로). 즉 x 의 값의 범위에 따라 w 가 미치는 영향도 조금 달라지게 되는 셈입니다. 이해를 돕기 위해 

그림 7. (w, x)가 (5, 3)인 점과 (5, -3)인 곳에서 
우리가 학교에서 1차 방정식의 기울기를 배울 때 이와 비슷하게 입력값에 대한 출력값의 변화율을 사용해 계산하는 법을 배웠습니다.

이 값은 x 의 값과 일치 하네요. 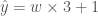
w 와

그림 8.
이번에는 반대로 w 를 고정하고 x 를 변경시켜 보겠습니다.
n1.set_params(5, 1) # w, b 를 5, 1 로 셋팅 print(n1.forpass(4)) # x 에 4 을 입력
21
w 는 5로 그대로 둔채 x 를 3에서 4로 증가하였더니 출력이 16에서 21로 증가하였습니다. 이번에는 x 에 대한

이 값은 w 와 같네요! 앞의 경우와 반대로 x 에 대한 함수라고 생각하면 이 함수의 기울기는 당연히 w 가 됩니다. 즉 우리는 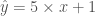

그림 9.
그림 9 에서도 볼 수 있듯이 (w, x)가 (5, 3)인 곳에서는 w 를 고정하고 x 를 움직일 때 b 를 움직여 볼까요?
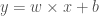
w 와 x 가 고정되어 있을 때 b 를 크게하면 출력값 b 를 감소시키면
n1.set_params(5, 2) # w, b 를 5, 2 로 셋팅 print(n1.forpass(3)) # x 에 3 을 입력
17
n1.set_params(5, 0) # w, b 를 5, 0 으로 셋팅 print(n1.forpass(3)) # x 에 4 을 입력
15
b 에 대한 b 가 늘어나거나 줄어든 만큼

우리가 훈련 데이터를 이용해 정방향 계산을 한 후 원하는 w 와 b 를 조정하려면 위와 같이 w 와 b 에 대한 b 에 대한 x 에 영향을 안 받고 일정하므로 굳이 계산할 필요는 없죠). 우리가 보는 이 방정식은 매우 간단하여 이런 방식을 사용해도 상관없겠지만 아주 복잡한, 예를 들면 완전한 뉴럴 네트워크 같은, 머신러닝 모델의 경우에는 매우 비효율적인 방법입니다. 다행히도 이보다 나은 방법이 있습니다.
경사하강법(Gradient Descent)
앞서서 변화율을 계산할 때 입력값 w 를 5 에서 6 으로 1 만큼 증가시키고 출력값이 변하는지를 살펴 봤습니다. 수학에서 변화율을 계산할 땐 이 증가치가 매우 작은 극한 값으로 가야한다고 정의하고 있는데요. 우리가 보고 있는 1차 방정식에서는 증가치의 크기에 관계없이 일정한 변화율을 가지지만 곡선 그래프를 그리는 함수에서는 큰 폭으로 변화를 주면 그 지점의 기울기를 올바르게 표현하지 못하게 됩니다. 이를 비유하는 좋은 예로 우리가 눈을 감고 매우 굴곡진 구릉을 걸어 올라가고 있다고 생각하면 조금씩 발을 내디뎌야지 제대로 높은 곳을 나아갈 수 있을 것입니다. 큰 걸음으로 껑충 뛰었다가는 웅덩이에 빠질 수도 있겠죠.
그런데 w 의 변화량을 극한으로 보내서 출력의 변화율을 구하는 것은 미분의 정의입니다. 즉 우리가 수학에서 배웠던 미분공식을 이용하면 매번 w 값을 변경하고
미분에 대해서 알고 계신 분들은 이미 눈치채셨겠지만 w 에 대한 미분은 
b 에 대해 미분을 하면 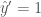
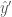

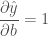

w 에 대한 x 에 대해 미분을 한다면 어떻게 될까요?
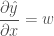
입니다. 이 결과는 앞의 변화율을 계산한 것과 정확히 일치하네요.
이제 우리 뉴런의 가중치를 어떤 방향으로 수정해야 원하는 출력값을 만들 수 있는지 알았습니다. 만약 우리가 계산한 출력이 90이고 훈련 데이터의 값이 100이라면 -10만큼 오차가 있습니다. w 에 대한 변화율은 x 이므로 모자란 값 10을 이 변화율에 곱해서 w 값을 더 크게하면 될 것 같습니다. 그리고 b 에 대한 변화율은 1이므로 오차값을 그대로 b 에 더하면 될 것 같습니다. 그런데 훈련 데이터는 한개가 아니고 442개 이므로 모든 오차를 더해 평균을 내어 사용하도록 하겠습니다.
이건 다른 비유로 이해하자면 오차만큼 뉴런에 반작용 힘을 가하는 것으로 설명할 수 있습니다. 오차가 양수이면 뉴런의 출력이 오버된 것이므로 줄이도록 압력을 행사하고 오차가 음수이면 뉴런의 출력이 미진한 것이므로 출력을 높이도록 뉴런에 압력을 가하는 모습이 됩니다.
하지만 위에서 말한 구릉을 더듬어 가는 비유처럼 복잡한 모델에서는 너무 급격한 변화를 주기보다는 보수적으로 조금씩 변경해 나가는 것이 바람직합니다. 그래서 이 오차값에 0.1 정도를 곱해서 w 와 b 를 천천히 바꾸어 나가도록 하겠습니다. 이를 위해서 두개의 함수를 SingleNeuron 클래스에 추가하였습니다.
def backprop(self, err):
"""에러를 입력받아 가중치와 바이어스의 변화율을 곱하고 평균을 낸 후 감쇠된 변경량을 저장합니다."""
m = len(self._x)
self._w_grad = 0.1 * np.sum(err * self._x) / m
self._b_grad = 0.1 * np.sum(err * 1) / m
def update_grad(self):
"""계산된 파라메타의 변경량을 업데이트하여 새로운 파라메타를 셋팅합니다."""
self.set_params(self._w + self._w_grad, self._b + self._b_grad)
backprop 함수는 에러를 입력 받아 가중치와 바이어스를 변경해야할 양을 계산하고 있습니다. 먼저 가중치의 변화량을 계산하기 위해 에러에 w 에 대한 변화율 x 를 곱해서 더하고 전체 데이터 갯수로 나누어 평균을 구한 후에 속도 조절을 위해 0.1 을 곱하고 있습니다. 그리고 바이어스의 변화량은 b 의 변화율이 1 이므로 에러에 1 을 곱한후 평균을 내고 0.1 을 곱했습니다. 그리고 update_grad 함수는 가중치와 바이어스를 업데이트 하는 함수입니다. 이 함수는 backprop 에서 구한 파라메타의 변경량을 set_params 함수를 통해 새로운 파라메타로 다시 셋팅합니다.
여기서 한가지 주의할 점은 오차 변수 err 에는 모든 훈련 데이터의 오차가 다 들어 있다는 것입니다. 위 코드는 넘파이 배열의 기능을 활용하고 있어 for 루프를 사용하지 않아도 배열의 모든 요소에 곱셈과 덧셈이 자동으로 적용됩니다. 조금씩 w 와 b 를 변경하고 있으므로 여러번 반복해서 같은 함수를 실행해야 합니다.
n1.set_params(5, 1)
for i in range(30000):
y_hat = n1.forpass(diabetes.data[:, 2])
error = diabetes.target - y_hat
n1.backprop(error)
n1.update_grad()
print('Final W', n1._w)
print('Final b', n1._b)
Final W 948.370777729 Final b 152.133484163
3만번 실행했더니 w 는 713.9, b 는 152.1 을 구했네요. 그럼 우리가 찾은 직선을 산점도 위에 그려 보겠습니다.

그림 10. 산점도 위에 그린 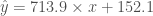
어떤가요? 그럴싸한 직선이 아닌가요? 이것이 바로 경사하강법입니다!
조금 더 기술적으로 설명해 보겠습니다. 머신러닝 모델을 만들때 우리는 오차를 정의하고 이 오차를 줄이는 방향으로 모델의 파라메타(w 와 b)를 조정합니다. 오차를 정의하는 함수를 비용 함수(Cost Function)라고 부릅니다. 혹은 손실 함수(Loss Function), 목적 함수(Objective Function) 또는 오차 함수(Error Function)으로 부르기도 합니다. 많은 사람들이 이들 용어를 특별히 구분하지 않고 같은 의미로 사용하고 있습니다. 오차 함수란 용어가 직관적으로 이해되기는 하지만 많은 머신 러닝 강의나 책들이 비용 함수나 손실 함수란 용어를 선호하고 있습니다.
이론적인 선형 회귀 분석의 비용 함수(J)는 평균제곱오차(Mean Square Error) 방정식과 유사하게 아래와 같이 정의합니다.

아마 이런 공식을 다른 책에서도 종종 볼텐데요. 너무 걱정할 필요는 없습니다. 이건 어려운 식이 아닙니다. 각 훈련 데이터(m 개)의 오차(
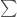
이 비용 함수를 왜 미분할까요? 비용 함수가 최소화 되는 점을 찾으려면 이 함수의 가장 작은 값을 찾아 기울기를 따라 내려가야 하거든요. 즉 경사하강법을 쓰기 위해 미분을 해야하는 것이죠. 이 글에서 가장 어려운 미분이 나옵니다. 혹시 잘 이해가 안되더라도 괜찮습니다. 여기서 직접 미분을 하는 것은 하나의 예를 보이기 위해서일 뿐입니다.
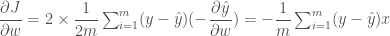
출력 오차에 x 를 곱하고 평균을 낸 후에 부호를 바꾼 것이네요. 우리가 위에서 만든 뉴런의 역할과 동일합니다! b 에 대해서도 미분을 해 보죠.
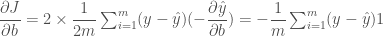
역시 이 결과는 위에서 우리가 만든 코드와 동일합니다. y 가 w 와 b 는 출력값이 증가되는 방향으로 업데이트되어야 하는 것이죠. 다시말하면 경사하강법이란 말에서 짐작할 수 있듯이 우리는 이 비용 함수의 미분값 즉 경사를 따라서 가장 작은 지점을 찾길 원합니다. 따라서 계산된 값의 반대 방향으로 따라 내려가야죠. 즉, 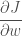
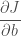
backprop 함수에 적용된 계산입니다.
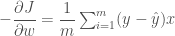

아래 그림으로 보면 이해가 훨씬 쉽습니다. 두개의 파라메타(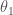
J)가 어떤 3차원 공간에 굴곡진 면으로 나타날 경우 경사하강법은 임의의 위치에서 조금씩 아랫 방향으로 나아가는 방법입니다.

그림 11. 비용 함수 위를 움직이는 경사하강법. 출처: Andrew Ng 코세라 머신러닝 강의
그럼 우리가 구한 식이 뉴런에서 업데이트 되는 모습으로 그림을 그려 보겠습니다. 아래 그림에서는 전체 훈련 데이터에 대해 에러를 합산하고 다시 평균으로 나누는 과정은 생략했습니다. 에타(
w 와 b 를 업데이트 하기위해 전달되는 것을 종종 그래디언트(gradient)가 전달된다고 표현합니다.

그림 12. 에러가 뉴런에 전달되는 그림
사이킷런과 비교
우리가 만든 SingleNeuron 클래스로 구한 결과와 사이킷런 패키지로 만든 선형 회귀 모델을 비교해 보겠습니다. 사이킷런의 선형 모델이 들어 있는 linear_model 패키지를 임포트합니다. 그리고 경사하강법을 사용하는 회귀 분석 클래스인 SGDRegressor 의 인스턴스를 만들고 체질량 지수 데이터를 이용하여 모델을 피팅(fitting) 합니다. 반복은 위에서 했던 것과 같이 3만번을 수행해 보겠습니다.
사이킷런은 머신러닝 모델을 만드는 데 일관된 인터페이스를 따르고 있는데 그 중에 하나가 바로 fit 메소드입니다. 즉, SGDRegressor 클래스 말고 다른 클래스에서도 모델을 학습시키는 메소드는 동일하게 fit 을 사용합니다.
from sklearn import linear_model sgd_regr = linear_model.SGDRegressor(n_iter=30000, penalty='none') sgd_regr.fit(diabetes.data[:, 2].reshape(-1, 1), diabetes.target)
diabetes.data[:, 3] 은 하나의 긴 리스트를 반환합니다. 하지만 fit 메소드는 2차원 배열을 입력으로 기대하기 때문에 요소 하나 하나를 리스트로 바꾸어 차곡차곡 쌓아야 합니다. reshape 메소드가 이런 역할을 해 줍니다. 아래 코드를 보시면 이해가 빠를 것 같네요.
print(diabetes.data[:, 2][:10])
[ 0.06169621 -0.05147406 0.04445121 -0.01159501 -0.03638469 -0.04069594 -0.04716281 -0.00189471 0.06169621 0.03906215]
print(diabetes.data[:, 2]).reshape(-1, 1))
[[ 0.06169621] [-0.05147406] [ 0.04445121] [-0.01159501] [-0.03638469] [-0.04069594] [-0.04716281] [-0.00189471] [ 0.06169621] [ 0.03906215]]
이제 SGDRegressor 클래스로 구한 가중치와 바이어스를 프린트 해 보겠습니다.
print('Coefficients: ', sgd_regr.coef_, sgd_regr.intercept_)
Coefficients: [ 948.18763899] [ 152.1296324]
우리가 구한 값과 매우 비슷하네요! 우리가 선형 회귀 모델을 직접 만들었습니다!
참고자료:
배치, 미니 배치
위에서 체질량 지수를 이용해 선형 회귀 모델을 만들 때 사이킷런 라이브러리의 SGDRegressor 를 사용했습니다. SGD 는 Stochastic Gradient Descent 의 약자로 확률적 경사하강법이라고 부릅니다.
우리가 만든 SingleNeuron 은 훈련 데이터를 사용하여 여러번 반복하여 모델의 파라메타를 조금씩 변경했습니다. 이 때 훈련 데이터 전체를 이용했는데요. 즉 442개 전체 데이터를 이용해서 파라메타의 변경량을 계산했습니다. 이런 방식을 특별히 배치 경사하강법(Batch Gradient Descent)라고 부릅니다. 그런데 데이터의 양이 아주 많으면 이 방식은 훈련하는 동안 연산에 많은 비용이 들게 됩니다.
그래서 훈련 데이터의 일부를 사용하여 파라메타의 변경량을 계산하는 방식이 고안되었습니다. 확률적 경사하강법은 한개의 데이터를 이용해서 파라메타를 업데이트 하는 방법입니다. 훈련 데이터 하나씩만 사용해서 파라메타를 업데이트 하므로 반복이 진행됨에 따라 비용 함수의 감소 곡선이 이전처럼 부드럽지 않고 좀 늘쭉 날쭉 요동이 생기게 됩니다. 이 방식으로 미리 준비된 훈련 데이터가 아니고 새로운 데이터가 발생될 때 마다 학습을 진행시키는 것을 온라인 러닝이라고도 부릅니다.
한개씩 사용하는 것과 전체를 사용하는 것을 절충해서 훈련 데이터를 작은 묶음씩 나누어 훈련을 시키는 것을 미니 배치(mini-batch) 경사하강법이라고 부릅니다. 미니 배치 사이즈는 10 개 혹은 20 개 정도로 만들지만 정해진 룰이 있는 것은 아닙니다. 미니 배치 방식은 연산 비용과 학습 효과를 적절히 안배할 수 있어서 널리 사용되고 있습니다.
우리가 사용한 SGDRegressor 는 확률적 경사하강법을 기본으로 사용하고 있어서 SingleNeuron 에서 사용한 배치 경사하강법의 결과와 조금 다르게 나왔던 것입니다.
최소제곱법(Ordinary Least Square, OLS)
글 서두에서 언급했듯이 최적의 파라메타를 찾는 방법에는 경사하강법외에도 여러가지가 있습니다. 그 중에 가장 고전적이고 또 거의 모든 통계학 책에서 나오는 방법이 최소제곱법을 정규방정식(Normal Equation)으로 푸는 방법입니다. 이 방법을 사용하여 어떻게 공식을 유도하는 지는 여기서 설명하지 않겠습니다. 다만 결과 식만 살짝 보도록 하겠습니다. 아래 식에서 X 는 각 특성을 컬럼으로 하고 각 샘플을 행으로 가지는 전체 데이터를 담고 있는 행렬입니다. 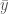

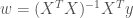
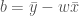
사이킷런에도 정규방정식을 이용하여 계산하는 기능을 제공하고 있습니다.
sgd_regr = linear_model.LinearRegression()
sgd_regr.fit(np.vstack(diabetes.data[:, 2]), diabetes.target)
print('Coefficients: ', sgd_regr.coef_, sgd_regr.intercept_)
Coefficients: [949.43526038] 152.133484163
거의 비슷한 값이지만 조금 다르네요. 사실 선형 회귀 분석에서는 이 방법으로 구한 파라메타가 최적의 파라메타가 맞습니다. 하지만 이 방식에는 단점이 존재합니다. 훈련 데이터가 매우 클 경우 역행렬을 구하는 데 너무 많은 계산 비용이 들게 되고 아주 큰 대량의 데이터의 경우 불가능하기도 합니다. 또 드물게는 역행렬을 구할 수 없는 특이 행렬(Singular Matrix)도 존재합니다. 그래서 이 예제와 같이 간단한 문제의 경우를 제외하고는 대부분 경사하강법이 대표적인 최적화 알고리즘이라고 말할 수 있습니다.
다음장에서는
다음장에서는 모델을 좀 더 견고하게 만들 수 있는 방법과 분류(Classification) 모델에 대해 살펴 보겠습니다. 참고를 위해 아래 전체 SingleNeuron 클래스의 코드를 싣습니다.
import numpy as np
class SingleNeuron(object):
def __init__(self):
self._w = 0 # 가중치 w
self._b = 0 # 바이어스 b
self._w_grad = 0
self._b_grad = 0
self._x = 0 # 입력값 x
def set_params(self, w, b):
"""가중치와 바이어스를 저장합니다."""
self._w = w
self._b = b
def forpass(self, x):
"""정방향 수식 w * x + b 를 계산하고 결과를 리턴합니다."""
self._x = x
_y_hat = self._w * self._x + self._b
return _y_hat
def backprop(self, err):
"""에러를 입력받아 가중치와 바이어스의 변화율을 곱하고 평균을 낸 후 감쇠된 변경량을 저장합니다."""
m = len(self._x)
self._w_grad = 0.1 * np.sum(err * self._x) / m
self._b_grad = 0.1 * np.sum(err * 1) / m
def update_grad(self):
"""계산된 파라메타의 변경량을 업데이트하여 새로운 파라메타를 셋팅합니다."""
self.set_params(self._w + self._w_grad, self._b + self._b_grad)

잘 읽었습니다~ 유용한 정보네요
좋아요Liked by 1명
머신러닝을 시작해보려고 하는데.. 많은 도움이 되었습니다. 인터프리터 언어를 싫어하는(?) 수치해석 분야와는 다르게, 머신러닝에선 인터프리터 언어인 파이썬이 부각되는게 재밌네요. 그만큼 연구가 초기 단계이고.. 아니면 연구자가 할 수 있는 자유도가 한정되어있다는 의미인 것 같기도 하고.. (결국 파이썬 라이브러리들은 c나 포트란의 래퍼니깐..) 아무튼 많은 생각이 듭니다.
좋아요Liked by 2 people
도움이 되셨다니 다행이네요. 저도 열심히 공부하는 중이에요! 🙂
좋아요좋아요
너무 좋은 글이에요!!
교과서처럼 공부하고 있답니다. 감사합니다.
좋아요Liked by 1명
맘에 드신다니 저도 기분이 좋네요! 🙂
좋아요좋아요
좋은 글 감사합니다.
좋아요Liked by 1명
내공이 느껴집니다..
인터넷에서 찾은 산발적인 정보들의 조각을 맞추는데 많은 시간들을 소비하고,심지어 정보를 흘리고 그러고 있는데.. ;;;
개념 정리하는데 많은 도움이 되었고, 이렇게 정리하여 정보 공유해주셔서 감사합니다.
좋아요Liked by 1명
도움이 되셨다니 기쁘네요. 🙂
좋아요좋아요
머신러닝을 시작하기에 좋은 글이네요. 스크롤의 압박과 노력이 있어야겠지만 충분한 가치를 제공할 것 같습니다.
좋아요Liked by 1명
error = diabetes.target – y_hat를 error = y_hat – diabetes.target으로 입력하면 overflow가 발생하네요. 0.1→0.01로 바꾸어도 반복횟수가 커지면 마찬가지입니다. 혹시 초기치 문제로 볼 수 있을까요?
좋아요좋아요
안녕하세요. 이 코드에서는 모델 파라미터에 그래디언트를 그냥 더해 주고 있으므로 diabetes.target – y_hat 이 맞습니다. 깃허브에 있는 코드와 비교해서 다른 점이 있는지 살펴 보시겠어요?(https://github.com/rickiepark/ml-learn/blob/master/notebooks/2.%20single_neuron.ipynb)
좋아요좋아요
error 계산식 부분만 바꾸면 문제가 없는데, ( y_hat – diabetes.target )로 입력한 경우에는 왜 overflow가 생기는지 궁금하네요. (수식상으로는 부호가 문제될 것 같지는 않을 것 같습니다만)
아무튼 아주 잘 보고, 배우고 있습니다. 감사드립니다~~
좋아요좋아요
네, 경사하강법은 비용함수가 가장 최저인 지점을 찾는 과정입니다. 비용함수가 볼록함수라면 최저점으로 향할 수록 미분값이 점점 작아질 것입니다. 경사하강법을 계산할 때 비용함수의 미분값 y – y_hat을 가중치에서 더해 주거나, y_hat – y을 가중치에서 빼 줍니다. 이 글에서는 전자의 경우입니다. 만약 y_hat – y를 가중치에 더해 준다면 비용함수의 낮은 부분으로 향하지 않고 높은 쪽으로 향하기 때문에 가중치가 매우 커지게 됩니다.^^
좋아요좋아요
감사합니다. 정말 많은 도움이 되었습니다!
좋아요Liked by 1명
도움이 되셨다니 다행이에요! 🙂
좋아요좋아요
핑백: [용어 정리] 목적 함수 – Lifetime behind every seconds