이 글에서 사용한 코드는 깃허브에서 확인할 수 있습니다.

본격 머신러닝 입문서 <[개정판] 파이썬 라이브러리를 활용한 머신러닝> 출간.
이 책은 사이킷런(Scikit-Learn) 라이브러리에 있는 지도학습, 비지도학습, 모델 평가, 특성공학, 파이프라인, 그리드서치 등 머신러닝 프로젝트에 필요한 모든 단계를 다루고 있습니다. 또한 파이썬을 사용한 영문, 한글 텍스트 처리 방법도 포함되어 있습니다! 🙂
온/오프라인 서점에서 판매 중입니다. [YES24] [교보문고] [리디북스] [한빛미디어]
테스트 데이터
앞에서 사이킷런의 당뇨병 데이터의 체질량 지수 데이터를 가지고 경사하강법(Gradient Descent) 최적화 알고리즘을 사용하여 선형 회귀 모델을 만들었습니다. 이제 우리는 새로운 환자의 체질량 지수만 알면 1년뒤 얼마나 병이 악화될 지 최선의 예측을 할 수 있습니다. 맞죠? 아닌가요?

우리가 훈련 데이터를 이용해서 머신러닝 모델을 만드는 것은 새로운 데이터에 대한 예측을 하기 위해서입니다. 모델이 그럴싸하게 보이더라도 새로운 데이터에 대한 예측을 잘 못한다면 별 소용이 없겠죠? 그러면 새 데이터를 이용해서 이 모델이 예측을 잘 하는지 확인해 봐야 겠네요. 그런데 새로운 데이터는 어디에 있을까요? 새로운 당뇨병 환자의 증세를 측정하기 위해 1년을 다시 기다려야 할까요? 아닙니다. 우리는 이미 데이터를 가지고 있거든요!
다시말해 우리가 가지고 있는 442개의 훈련 데이터를 조금 떼어내어 평가의 목적으로 사용할 수 있습니다. 보통 이런 데이터를 테스트 데이터라고 합니다. 새로운 데이터로서의 역할을 담당하게 되는 거죠.
그럼 앞서 만든 모델을 만들 때 전체 데이터를 사용하지 않고 일부를 덜어내도록 하겠습니다. 보통은 20% 정도를 덜어냅니다만 우리는 데이터가 작으므로 10% 정도만 덜어내겠습니다. 훈련 데이터가 특정한 순서대로 나열되어 있을 수 있다면 덜어낼 때 무작위로 뽑아 내는 것이 안전할 것입니다. 사이킷런은 테스트 데이터를 편리하게 추출해낼 수 있는 함수를 제공해 주고 있습니다.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(diabetes.data[:,2], diabetes.target, test_size=0.1, random_state=10)
train_test_split 함수에 입력과 출력값을 전달하고 테스트 데이터의 퍼센트를 소수값으로 전달하면 훈련 데이터와 테스트 데이터로 나뉘어진 입력, 출력값을 되돌려 줍니다. 종종 입력 데이터는 2차원 배열로 나타나므로 대문자 X 로 표현하고 있습니다. 리턴된 넘파이 배열의 크기를 살펴보면 훈련 데이터는 397개, 테스트 데이터는 45개로 대략 10% 정도 기준으로 나뉘어진 것을 확인할 수 있습니다.
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(397,) (45,) (397,) (45,)
이제 훈련 데이터로만 모델을 만들고 테스트 데이터로는 만들어진 모델을 평가해 보겠습니다. forpass 함수로 계산을 하고 에러를 backprop 으로 전달하여 파라메타를 업데이트 하는 과정을 편리하게 하기 위해 SingleNeuron 클래스에 fit 메소드를 추가하겠습니다. 이 메소드는 이전에 우리가 했던 것과 동일한 방식으로 입출력 값과 반복 횟수를 넘겨 받아 for 루프를 반복합니다.
def fit(self, X, y, n_iter=10):
"""정방향 계산을 하고 역방향으로 에러를 전파시키면서 모델을 최적화시킵니다."""
for i in range(n_iter):
y_hat = self.forpass(X)
error = y - y_hat
self.backprop(error)
self.update_grad()
이제 훈련 데이터 X_train 과 y_train 을 사용해서 모델을 학습시켜 보겠습니다. forpass 메소드와 backprop, update_grad 메소드를 fit 메소드 안에 감추니 학습 시키는 코드가 훨씬 깔끔해 졌습니다.
n1.set_params(5, 1)
n1.fit(X_train, y_train, 30000)
print('Final W', n1._w)
print('Final b', n1._b)
Final W 946.291309007 Final b 151.784075857
평가를 하는 방법은 여러가지가 있는데 여기서는 가장 간단한 평균제곱에러(Mean Square Error)를 사용하겠습니다. 평균제곱에러는 오차를 제곱하여 데이터 갯수로 나눈 것이죠. 선형 회귀 분석의 비용함수와 매우 비슷합니다. 사실 회귀 분석의 비용함수는 평균제곱에러를 사용한 것인데 미분의 편의상 2로 나눈 것 뿐이었죠.

우리가 직접 계산할 수도 있고 사이킷런에서 제공하는 함수를 사용할 수도 있습니다. 직접 계산하려면 넘파이의 합을 계산하는 sum 과 제곱을 계산하는 square 를 사용하면 편리합니다.
y_hat = n1.forpass(X_test) print(np.sum(np.square(y_test - y_hat))/len(X_test))
3330.44578806
사이킷런에서는 metrics 패키지에서 여러가지 평가 함수를 제공하고 있습니다. 평균제곱에러를 계산하는 함수는 mean_squared_error 입니다.
from sklearn import metrics print(metrics.mean_squared_error(y_test, y_hat))
3330.44578806
정확히 동일한 값이 나오네요. 한가지 주의할 사항은 테스트 데이터를 한번 덜어내면 이 데이터는 모델을 평가할 때만 사용해야 합니다. 그렇지 않고 모델을 학습시키거나 개선시킬 때 활용하면 나중에 모델을 평가할 때 공정한 평가가 되지 못하겠죠. 많은 머신러닝 기술자들이 이런 점을 강조하고 있습니다.
이번에는 훈련과 테스트로 나눈 데이터를 가지고 사이킷런에서 제공하는 SGDRegressor 를 사용하여 훈련시켜 보겠습니다. 이전 장에서 우리가 했던 것과 동일합니다.
from sklearn import linear_model
sgd_regr = linear_model.SGDRegressor(n_iter=30000, penalty='none')
sgd_regr.fit(X_train.reshape(-1, 1), y_train)
print('Coefficients: ', sgd_regr.coef_, sgd_regr.intercept_)
Coefficients: [ 945.03256517] [ 151.76813145]
사이킷런에서 모델을 만든 후에 새로운 데이터의 예측 값을 구할 때 사용하는 함수는 predict 입니다. 우리가 만든 SingleNeuron 에서는 forpass 함수가 학습과 예측에서 모두 사용되었는데 사이킷런에서는 이 두가지 기능이 구분되어 있습니다. 사이킷런의 모든 알고리즘 클래스가 fit, predict 메소드를 가지고 있어서 우리가 일관성있게 코드를 만들 수 있게 도와줍니다.
y_hat = sgd_regr.predict(X_test.reshape(-1, 1)) print(metrics.mean_squared_error(y_test, y_hat))
3330.67031684
이 섹션에서 우리가 가지고 있는 데이터를 훈련 데이터와 테스트 데이터로 나누어 학습과 평가에 각각 활용했습니다. 만약 손쉽게 테스트 데이터를 구할 수 있는 환경이라면 굳이 가지고 있는 훈련용 데이터를 쪼개어 테스트 데이터로 사용할 필요가 없습니다.
학습 속도
앞서 우리가 모델을 만들 때 임의로 정한 값이 있는데요. 경사하강법을 따라 오차함수를 조심스럽게 이동하기 위해 오차에 0.1을 곱했습니다. 이 값을 학습 속도(Learning Rate)라고 부릅니다. 학습 속도가 크면 성큼 성큼 걸어 내려가는 것이고 작으면 조금씩 이동하는 것이죠.
학습 속도와 같이 임의의 값을 부여해야하는 파라메타를 하이퍼파라메타(Hyperparameter, 초파라메타)라고 부릅니다. 하이퍼파라메타는 데이터를 통해 학습될 수 없는 파라메타로 뉴럴 네트워크의 레이어수나 뉴런의 갯수 등이 대표적입니다. 하이퍼파라메타를 많이 정해야 하는 알고리즘 보다는 그렇지 않은 알고리즘이 사용하기 좋겠죠. 이와는 반대로 데이터를 통해 학습되는 파라메타, 즉 가중치 w 나 바이어스 b 등을 모델 파라메타라고 부릅니다.
학습 속도는 보통 0.0001 ~ 10 사이에서 지정합니다. 어떻게 모델에 가장 적합한 학습 속도를 찾을 수 있을까요? 학습 속도에 따라 비용 함수의 값이 어떻게 감소되는지를 그래프로 그려보면 쉽게 찾을 수 있습니다. 이를 위해 앞에서 만든 fit 메소드를 조금 수정하여 학습 속도와 평균제곱에러를 계산할 수 있도록 파라메타를 추가하겠습니다.
def backprop(self, err, lr=0.1):
"""에러를 입력받아 가중치와 바이어스의 변화율을 곱하고 평균을 낸 후 감쇠된 변경량을 저장합니다."""
m = len(self._x)
self._w_grad = lr * np.sum(err * self._x) / m
self._b_grad = lr * np.sum(err * 1) / m
def fit(self, X, y, n_iter=10, lr=0.1, cost_check=False):
"""정방향 계산을 하고 역방향으로 에러를 전파시키면서 모델을 최적화시킵니다."""
cost = []
for i in range(n_iter):
y_hat = self.forpass(X)
error = y - y_hat
self.backprop(error, lr)
self.update_grad()
if cost_check:
cost.append(np.sum(np.square(y - y_hat))/len(y))
return cost
fit 메소드의 마지막 파라메타에 True 를 입력하면 매 반복마다 평균제곱에러를 계산하여 리스트에 누적하여 함수 호출자에게 리턴해 줍니다. 리턴된 비용 값을 costs 의 배열의 요소로 저장합니다. 즉 costs 는 리스트 안의 리스트 구조가 됩니다. 아래 코드는 학습 속도 1.999, 1.0, 0.1 세가지를 이용해서 모델을 학습시켜 본 것입니다. 그래프를 확대해서 보기 위해 편의상 2000번만 반복했으며 세로축의 값은 3500~7000 사이로 제한했습니다.
costs = []
learning_rate = [1.999, 1.0, 0.1]
for lr in learning_rate:
n1.set_params(5, 1)
costs.append([])
costs[-1] = n1.fit(X_train, y_train, 2000, lr, True)
for i, color in enumerate(['red', 'blue', 'black']):
plt.plot(list(range(2000)), costs[i], color=color)
plt.ylim(3500, 7000)
plt.show()
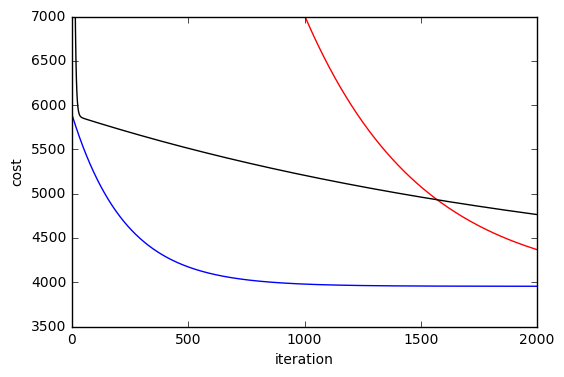
그림 1. 학습 속도에 따른 비용 감소 그래프
학습 속도가 0.1일 때에는(검은색) 초기에 비용 함수 값이 급격히 줄어들다가 선형적으로 조금씩 감소하는 것을 볼 수 있습니다. 이런 형태는 학습 속도가 느릴 때 나타나는 전형적인 예입니다. 학습 속도를 1.0으로 한 것(파란색)은 감소 형태가 지수함수 형태를 띄면서 안정적으로 최저값에 수렴하는 모습을 보여 줍니다. 학습 속도가 1.999인 경우(빨간색)에는 제대로 수렴하지 못하고 있습니다. 학습 속도가 이 보다 더 커지면 비용함수 값이 폭주하면서 아주 높은 값으로 수렴하는 전형적인 모습을 나타냅니다. 이 그래프에서 볼 수 있듯이 우리가 선택한 학습 속도 0.1은 너무 낮은 값이었습니다. 1.0 근처의 값이 보다 효과적으로 최적의 값에 빠르게 도달하고 있습니다.
뉴럴 네트워크 처럼 복잡한 모델의 비용함수는 학습의 반복(epoch)마다 나타나는 비용함수의 측정 값이 선형 모델 처럼 부드럽게 나타나지 않고 매우 요동을 치면서 수렴하게 됩니다. 보통 아래 그림처럼 말이죠.

그림 2. 뉴럴 네트워크의 비용 감소 그래프. 출처: 스탠포트 CS231n 강의 노트
우리가 위에서 그린 그래프는 학습 횟수에 따라 훈련 데이터의 비용 함수의 값이 어떻게 줄어드는 지를 나타내고 있는데요. 하지만 사실 테스트 테이터의 비용 함수 값이 얼마인 지가 더 관심사 아닐까요? 그럼 학습 속도에 따른 테스트 데이터에 대한 비용 함수 값이 어떻게 다른지 살펴 보겠습니다.
learning_rate = [1.2, 1.0, 0.8]
for lr in learning_rate:
n1.set_params(5, 1)
n1.fit(X_train, y_train, 2000, lr)
y_hat = n1.forpass(X_test)
print(metrics.mean_squared_error(y_test, y_hat))
3330.8154743 3331.74740789 3335.16964255
큰 차이는 없지만 학습 속도가 1.2일 때 조금 나은 것 같네요. 그런데 이렇게 테스트 데이터를 사용하여 하이퍼파라메타를 결정해서는 안됩니다. 그럼 최종적으로 테스트 데이터를 이용해 평가를 할 때 왜곡될 수 있기 때문입니다. 그럼 어떻게 해야할까요? 훈련 데이터를 다시 더 쪼갤 수 밖에 없겠네요.
검증(validation) 데이터
보통 크로스 밸리데이션(Cross-Validation)이라고 불리우는 이 방법은 훈련 데이터를 K 개로 나누고 그 중에 한 묶음을 검증 데이터로 사용하고 나머지 묶음을 훈련 데이터로 사용합니다. 그 다음에는 검증 데이터로 사용할 묶음을 바꾼 다음 다시 똑같이 학습 시킵니다. 이렇게 하면 총 K 번 시도하게 되고 모델의 에러 값은 K 로 평균내어 사용합니다. 특별히 그런 의미에서 K-폴드 크로스 밸리데이션(K-fold Cross-Validation)이라고 부르기도 합니다. 아래는 머신러닝 경연 사이트인 캐글(Kaggle)의 블로그에서 발췌한 그림으로 크로스 밸리데이션을 잘 설명하고 있습니다.

그림 3. 크로스 밸리데이션. 출처: Kaggle 블로그
사실 캐글은 테스트 데이터를 경연자에게 제공하지 않습니다. 오로지 훈련 데이터만 주어지기 때문에 만들어진 모델의 성능을 평가하고 또 가장 좋은 모델을 고르려면 훈련 데이터를 쪼개어 사용해야만 합니다. 이 그림에서는 테스트 데이터가 검증 데이터를 의미합니다.
보통 우리는 훈련 데이터에서 일부를 테스트 데이터로 덜어 냈기 때문에 다시 검증 데이터를 덜어낼 경우 테스트 데이터와 혼돈하지 않도록 주의해야 합니다. 보통 많이 사용하는 규칙은 테스트 데이터 20%, 검증 데이터 20%, 훈련 데이터 60% 입니다.
우리의 예에서는 선형 회귀 분석으로 한정하고 있지만 이차 방정식 이상으로 표현되는 여러개의 비선형 모델을 두고 비교하기 위해서 또 여러 가지 하이퍼 파라메타를 튜닝하기 위해 크로스 밸리데이션 기법을 사용합니다. 모델과 파라메타가 정해졌다면 최종적으로 훈련 데이터와 검증 데이터를 합쳐서 훈련을 시킵니다. 이렇게 하는 이유는 가능한 가장 많은 데이터를 사용해서 가중치 w 와 바이어스 b 를 최적화하려는 것입니다. 하지만 대규모 뉴럴 네트워크와 같이 연산에 시간이 많이 걸리거나 훈련 데이터의 양이 매우 많은 경우 마지막 과정을 생략하기도 합니다.
사이킷런에서는 크로스 밸리데이션을 위한 여러가지 함수를 제공하고 있습니다. 우리는 가장 간단한 KFold 함수를 사용하여 다섯개의 묶음으로 나누어 보겠습니다. 그리고 나서 다섯번을 반복 하면서 에러 값을 누적하여 평균내겠습니다. KFold 함수에서 데이터를 무작위로 묶기위해 shuffle 옵션을 활성화 했고 예제의 일관성을 위해 random_state 파라메타를 지정했습니다.
from sklearn.model_selection import KFold kf = KFold(n_splits=5, shuffle=True, random_state=10)
그런 다음 위의 예와 거의 동일하게 학습을 시켰습니다. 다만 각 폴드(fold) 마다 에러를 누적하여 마지막에 평균 값을 프린트합니다.
learning_rate = [1.2, 1.0, 0.8]
for lr in learning_rate:
validation_errors = 0
for train, validation in kf.split(X_train):
n1.fit(X_train[train], y_train[train], 2000, lr)
y_hat = n1.forpass(X_train[validation])
validation_errors += metrics.mean_squared_error(y_train[validation], y_hat)
print(validation_errors/5)
4006.76774948 4006.43602691 4005.6619766
위 코드에서 안쪽의 for 루프에서 kf.split 에서 리턴되는 train, validation 변수는 실제 데이터를 담고 있지 않고 나뉘어진 묶음의 인덱스를 가지고 있습니다. 그래서 선택된 묶음을 fit 메소드에 넘기려면 X_train[train], y_train[train] 과 같이 배열의 인덱스로 활용해야 합니다. 마찬가지로 mean_squared_error 함수를 위해서도 X_train[validation], y_train[validation] 으로 검증 데이터를 위한 인덱스가 사용되었습니다.
크로스 밸리데이션의 결과를 보니 학습 속도를 조금씩 바꾸어도 큰 차이가 없네요. 사실 이 예제는 효과적으로 크로스 밸리데이션을 설명할 수 있는 예제는 아닌 것 같습니다. 다만 의도한 것은 크로스 밸리데이션을 어떻게 만들었는지를 보여주는 것이었다고 이해해 주세요.
정형화(Regularization)
일반적으로 어떤 데이터에 최적화된 머신러닝 모델은 하나 이상일 수 있습니다. 즉 다른 가중치를 가진 모델이더라도 비용 함수의 값이 거의 같을 수 있는 거죠. 이런 경우 가능하면 가중치 값이 작은 모델을 선호합니다. 왜냐하면 가중치가 높을 경우 의외의 데이터에 민감해질 수 있기 때문입니다. 예를 들어 한 특성이 비정상적으로 큰 데이터가 입력되었다면 모델의 추론 결과는 그 특성에 큰 영향을 받게 되고 다른 특성은 무시될 것입니다. 따라서 가능한 최소의 가중치를 운영하는 것이 안정적인 추론을 하게됩니다.
가중치 파라메타를 최소화하다 보면 너무 작아 아예 그 역할을 못하게 될 수도 있습니다. 즉, 가중치 파라메타를 아주 작게 해도 비용 함수에 차이가 없다면 아예 그 특성을 제외시키는 특성 선택(feature selection)의 도구로도 활용할 수 있습니다.
이런 목적을 위해 가중치 파라메타를 가능한 작게하려는 추가적인 항을 비용 함수에 추가합니다. 이런 작업을 정형화라고 부릅니다. 사실 대부분의 책에서는 Regularization 을 정규화라고 부르지만 여기서는 데이터 정규화(Normalization)과 구분하기 위해서 정형화라고 하겠습니다. 같은 내용을 다르게 부르는 것 뿐이니 혼돈하지 마세요.
정형화에는 L1 정형화와 L2 정형화가 있습니다. 둘다 비용함수에 가중치 파라메타의 합을 더하는 형태입니다. L1 정형화는 각 가중치 파라메타의 절대 값을 더합니다. 이때 적절한 정형화 가중치 파라메타 람다(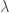
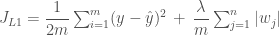
L1 정형화에 추가되는 항을 L1 페널티(penalty)라고 부르기도 하고 이런 방식의 선형회귀 분석을 라쏘(LASSO) 방식이라고 부르기도 합니다. 수식은 우리가 앞서 보았던 비용 함수에 가중치 파라메터의 절대 값을 모두 합한 것을 추가한 것입니다. 우리의 예에서 가중치 파라메타는 하나 뿐이므로 n = 1 입니다.
이런 페널티 항은 비용 함수의 그래프에서 가중치의 절대값이 커짐에 따라 비례해서 그래프가 들려 올려진다고 볼 수 있습니다. 그래서 비용 함수의 값이 같은 최저점이더라도 보다 0에 가까운 가중치 쪽으로 굴러 떨어질 가능성이 높죠. 그런데 경사하강법을 적용하기 위해 가중치 w 에 대하여 비용 함수를 미분하면 L1 페널티에서 남는 항은 람다 밖에 없게 됩니다. 그래서 효과가 그리 크지 않기에 보다 효과가 높은 L2 페널티를 많이 사용합니다. L2 정형화의 비용 함수는 아래와 같습니다.
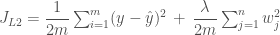
L2 페널티 항을 2로 나눈 것은 역시 미분한 후에 수식을 간단하게 만들려는 목적입니다. 우리 예에서 가중치 w 에 대해 이 비용 함수를 미분해 보겠습니다.
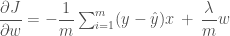
그리고 경사하강법을 적용하기 위해 미분 값의 음수를 취하면 각 항의 부호가 바뀝니다.

이 수식은 가중치가 양수일 때는 L2 페널티가 음수가 되고 반대로 가중치가 음수일 때는 L2 페널티가 양수가 되어 가중치를 0의 방향으로 잡아 당기는 역할을 합니다. 즉 가중치의 절대값을 가능한 작게 만드려고 하는 것이죠. 이런 L2 정형화를 릿지(Ridge) 회귀 분석이라고도 합니다.
우리가 코드에 적용할 부분은 사실 간단합니다. 람다 값을 입력 받아 가중치를 곱하고 훈련 데이터 갯수로 나누기만 하면 되거든요.
def update_grad(self, l2=0):
"""계산된 파라메타의 변경량을 업데이트하여 새로운 파라메타를 셋팅합니다."""
self.set_params(self._w + self._w_grad - l2 * self._w, self._b + self._b_grad)
def fit(self, X, y, n_iter=10, lr=0.1, cost_check=False, l2=0):
"""정방향 계산을 하고 역방향으로 에러를 전파시키면서 모델을 최적화시킵니다."""
cost = []
for i in range(n_iter):
y_hat = self.forpass(X)
error = y - y_hat
self.backprop(error, lr)
self.update_grad(l2/len(y))
if cost_check:
cost.append(np.sum(np.square(y - y_hat))/len(y))
return cost
그럼 L2 페널티를 사용하여 선형 회귀 모델을 만들어 보겠습니다. 예제를 간단히하기 위해 크로스 밸리데이션은 생략합니다.
for l2 in [0, 0.1]:
n1.set_params(5, 1)
n1.fit(X_train, y_train, 2000, 1.0, l2=l2)
print('Final W', n1._w)
print('Final b', n1._b)
y_hat = n1.forpass(X_test)
print(metrics.mean_squared_error(y_test, y_hat))
Final W 935.654492908 Final b 151.779158984 3331.74740789 Final W 842.993426674 Final b 151.736424518 3371.75796633
람다가 0.1 인 L2 페널티를 사용하면 에러는 다소 상승하지만 파라메타 w 값이 935 에서 842 로 100 가까이 줄어들었습니다. 그러므로 우리는 정형화를 사용한 두번째 모델이 입력 값에 대해 보다 안정적이라고 말할 수 있습니다.
두개의 뉴런
뉴런을 하나만 쓰지말고 두개를 활용해 보면 어떨까요? 그럼 더 나은 결과를 내지 않을까요?
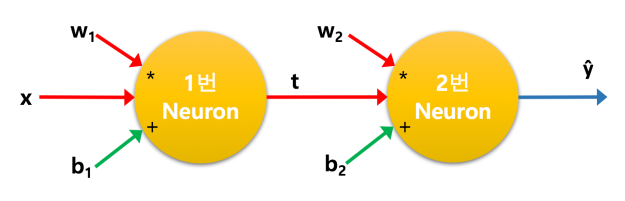
그림 4. 두개의 뉴런
1 번 뉴런에서 2 번 뉴런으로 전달되는 값을 t 라고 하면 1 번 뉴런의 식은

이고 2 번 뉴런의 식은
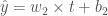
가 됩니다.
우리가 경사하강법을 사용해서 w 와 b 를 수정해 나가기 위해 비용 함수를 w 와 b 에 대해서 미분했었습니다.
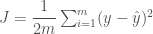
여기서도 마찬가지로 2 번 뉴런의 
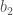
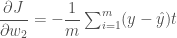
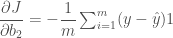
그런데 이번에는 그래디언트를 2 번 뉴런에서 1 번 뉴런으로 보내기 위해서 t 에 대해 미분하는 것이 필요합니다. 사실 그래디언트는 뉴런으로 들어오는 어떤 입력 요소로도 전달시킬 수 있습니다. 다만 뉴런이 하나일 경우 입력 값 x 는 훈련 데이터 자체이므로 그래디언트를 업데이트할 필요가 없었습니다. 그러나 이 경우 1 번 뉴런의 가중치를 변경시켜야 하므로 2 번 뉴런에서 1 번 뉴런으로 전달되는 그래디언트를 구할 필요가 있습니다. 그럼 2 번 뉴런의 비용 함수를 t 에 대해 미분해 보겠습니다.
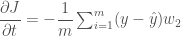
t 로의 방향 즉 2 번 뉴런에서 1 번 뉴런으로 향하는 그래디언트는 
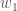


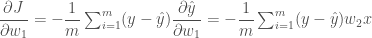
그런데 이 결과는 
x 를 곱한 것이네요. 그리고 x 는 1번 뉴런 식을
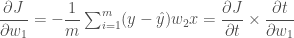
결국 이 모양은 아래와 같은 형태를 띱니다.

그림 5. 두개의 뉴런에 그래디언트가 전달되는 그림
이것이 뉴럴 네트워크에서 뉴런에 그래디언트를 업데이트 하기 위해서 앞쪽의 미분 값과 자신의 미분 값을 곱하여 나간다는 역전파(backpropagation) 알고리즘입니다. 사실 알고 보면 너무나 당연한 결과입니다. 왜냐하면 우리가 미분의 연쇄 법칙(Chain Rule)을 알고 있다면 2번 뉴런은 1번 뉴런과의 합성 함수로 나타낼 수 있어서 1번 뉴런의 그래디언트를 구하기 위한 미분은 두 함수의 미분 값을 곱하면 되기 때문입니다.

이 과정을 더 복잡한 수식으로 증명하기도 하지만 이 정도만 해도 꽤 장황하네요. 다른 말로 표현하면 역전파 알고리즘은 정답과 예측의 차이(
그러면 선형 계산을 하는 이런 뉴런을 여러개 놓는다고 성능이 더 좋아질까요? 아닙니다. 위에서 본 두개의 뉴런을 나타내는 식은 사실 하나의 식으로 나타낸 것과 동일합니다.

직관으로 느낄 수 있듯이 1 차 방정식을 여러개 감싼다고 달라지지 않습니다. 그래서 우리는 좀 더 복잡한 문제를 풀기 위해 뉴럴 네트워크에 비선형적인 효과를 가미해 주는 것이 필요합니다. 즉 뉴런에서 나오는 결과를 조금 비선형적으로 비틀어주면 되는 거죠. 흔히 이런 함수를 활성화 함수(Activation Funtion)라고 부릅니다.
대표적인 활성화 함수로는 시그모이드(Sigmoid), 렐루(ReLU), 하이퍼볼릭탄젠트(tanh), 소프트맥스(softmax) 함수등이 있습니다. 이런 함수들의 자세한 내용은 뒤에 다시 설명하겠습니다.
유방암 데이터
이제까지는 수치 값을 예측하는 회귀 분석을 예제로 삼아 봤는데요. 머신러닝의 주요한 또 하나의 예인 분류(Classification)를 사용해 보도록 하겠습니다. 분류는 결과가 숫자가 아니고 참, 거짓 같은 두가지 혹은 여러가지 종류로 구분하는 문제입니다. 이런 출력 값의 여러 종류를 지칭할 때 레이블(label) 혹은 클래스(class)라고 부릅니다. 그래서 여기서는 수치 출력 값을 가진 당뇨병 데이터를 사용할 수 없고 사이킷런에서 제공하는 다른 데이터인 유방암 데이터를 사용하겠습니다.
사이킷런에 포함된 유방암 데이터는 위스콘신(Wisconsin) 대학에서 나온 데이터로 569개의 데이터가 있고 30개의 특성(feature)이 있습니다. 데이터를 로드하고 각 특성의 이름과 구조를 살펴 보겠습니다.
from sklearn import datasets cancer = datasets.load_breast_cancer() print(cancer.data.shape) print(cancer.feature_names) print(cancer.target_names)
(569, 30) ['mean radius' 'mean texture' 'mean perimeter' 'mean area' 'mean smoothness' 'mean compactness' 'mean concavity' 'mean concave points' 'mean symmetry' 'mean fractal dimension' 'radius error' 'texture error' 'perimeter error' 'area error' 'smoothness error' 'compactness error' 'concavity error' 'concave points error' 'symmetry error' 'fractal dimension error' 'worst radius' 'worst texture' 'worst perimeter' 'worst area' 'worst smoothness' 'worst compactness' 'worst concavity' 'worst concave points' 'worst symmetry' 'worst fractal dimension'] ['malignant' 'benign']
30개의 특성은 세포특징을 10가지로 측정하고 각각의 평균과 편차, 최대 이상치를 기록한 것입니다. 출력은 암에 대해 악성인지(0)와 양성인지(1)로 구분하고 있습니다. 양성의 의미는 세포에 이상이 없다는 의미입니다. 우리는 cancer 데이터의 8번째 즉 ‘mean concave points’ 만을 사용하여 악성과 양성을 구분해 보려고 합니다. ‘mean concave points’는 세포에 움푹 패인 곳의 횟수를 평균낸 것입니다. 먼저 이 특성 데이터를 잠시 살펴 보죠.
cancer.data[100:110, 7]
array([ 0.04489, 0. , 0.0177 , 0.03029, 0.01201, 0.09601,
0.03485, 0.01921, 0.1823 , 0.01899])
입력 데이터의 100번째 부터 10개 데이터에 대해 8번째 컬럼을 보기위해 인덱스 7을 지정하였습니다. 이에 상응하는 출력 값도 살펴 보겠습니다.
cancer.target[100:110]
array([0, 1, 1, 1, 1, 0, 1, 1, 0, 1])
입력과 출력을 하나씩 대조해 보면 ‘mean concave points’ 수치가 높은 경우에 악성(0)인 것을 알 수 있습니다. 출력이 연속된 숫자가 아닐 경우 입력과 출력 관계를 나타내기에 좋은 그래프 중 하나는 박스플롯(boxplot) 입니다. 맷플롯립의 박스플롯을 사용하여 ‘mean concave points’ 와 출력 간의 관계를 그려 보겠습니다.
plt.boxplot([cancer.data[cancer.target==0, 7], cancer.data[cancer.target==1, 7]]) plt.xticks([1, 2], [0, 1]) plt.show()

그림 6. mean concave points 의 박스플롯 그래프
10 개의 데이터로 어림짐작 했던 것과 같이 ‘mean concave points’ 의 값이 높을 수록 악성 종양(0)일 가능성이 높은 것 같습니다. 이렇게 시각적으로도 출력에 따라 입력 값의 차이가 뚜렷하니 ‘mean concave points’는 이 모델에 사용하기 좋은 특성인 것 같습니다. 우리는 예제를 단순화 하기 위해 계속 한가지 특성만을 사용하고 있습니다. 그러나 실제로는 가능한 좋은 특성을 모두 골라서 모두 사용하는 것이 좋겠죠. 특성을 추출하는 것(feature selection)도 짧은 주제는 아니므로 시간이 될 때 다시 정리해 보도록 하겠습니다. 어쨋든 여기서는 ‘mean concave points’를 사용해 분류 모델을 만들어 보겠습니다.
로지스틱 회귀 분석(Logistic Regression)
대표적인 분류 알고리즘은 서포트 벡터 머신(Support Vector Machine, SVM)이나 KNN(K Nearest Neighbor) 알고리즘 등이 있습니다. 우리가 사용할 알고리즘은 회귀 분석을 응용한 로지스틱 회귀 분석(Logistic Regression)입니다. 로지스틱 회귀 분석을 사용하는 이유는 선형 회귀 분석에서 부터 뉴럴 네트워크까지 일관성있게 이야기를 풀어가기 위해서이기도 하지만 여전히 널리쓰이는 알고리즘 중 하나이기 때문입니다.
여기서 사용할 뉴런의 구조는 선형 회귀 분석과 다를 게 없습니다. 다만 출력 값에 조금 변화를 주려고 합니다. 이 뉴런의 출력 값은 연속된 숫자입니다. 하지만 우리가 원하는 것은 악성(0)이냐 아니냐(1)하는 구분된 결과입니다. 즉 0 아니면 1 이 필요한 거죠.
통계학에서 성공 확율이 실패 확률 보다 얼마나 큰지를 나타내는 오즈비율(Odds ratio)라는 값이 있습니다. 성공할 확률 p 를 0 에서 부터 1 사이의 값으로 나타내면 실패할 확률은 1 - p 로 쓸 수 있습니다.

이 식의 그래프는 아래와 같습니다. 출력 값의 확률이 0 에서 부터 1까지 변화할 때 오즈비율의 값은 천천히 증가하다가 1에 가까울수록 급격히 증가하게 됩니다. 이 그래프는 대각선 방향으로 대칭을 이룹니다.
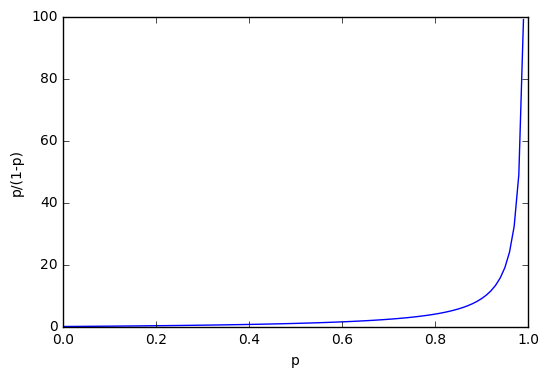
그림 7. 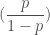
이 함수에 로그를 취한 것을 로짓(logit) 함수라고 합니다. 로짓함수는 p 가 0.5 일 때 0이 되고 p 가 1 일 때 무한히 큰 양수, p 가 0 일 때 무한히 큰 음수가 되는 특징을 가지게 됩니다.


그림 8. 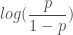
로짓 함수의 출력을 우리 뉴런의 출력이라고 생각하면 매우 큰 양수에서 매우 큰 음수까지 출력 값이 나올 때 확률 p 는 1 에서 0 사이를 움직이게 됩니다. 그리고 출력 값이 0 일때 p 는 0.5 가 됩니다. 0.5 보다 작을 경우 악성(0)으로 판명하고 0.5 보다 클 경우 양성(1)으로 판단하기에 매우 좋은 성질을 가진 셈입니다.
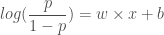
이 식을 뉴런의 출력 값에 따라 확률 p 를 구하기 편하도록 로그 함수를 지수 함수 형태로 바꾸어 보겠습니다.
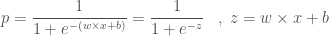
이 식을 유도하는 과정은 굳이 따라하진 않겠습니다. 보기 편하게 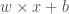

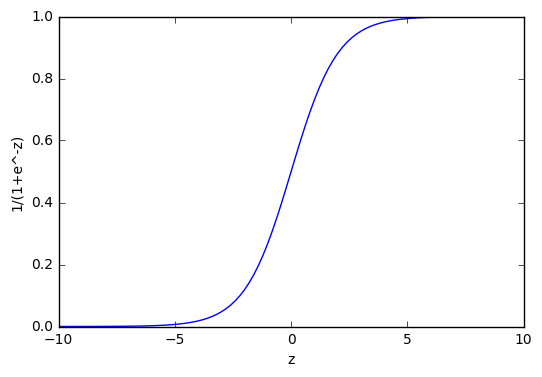
그림 9. 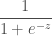
시그모이드 함수를 쓰면 뉴런의 출력 값을 0 ~ 1 사이의 한정된 값으로 압축 수 있습니다. 따라서 뉴런 앞에 시그모이드 함수를 두고 시그모이드를 통과한 값이 0.5 보다 크면 양성(1), 작으면 악성(0)으로 판별하면 됩니다. 이 방식이 바로 로지스틱 회귀 분석입니다. 이름은 회귀 분석이지만 수치 값을 예측하는 것이 아니고 이렇게 참, 거짓을 구분하는 분류 알고리즘입니다.
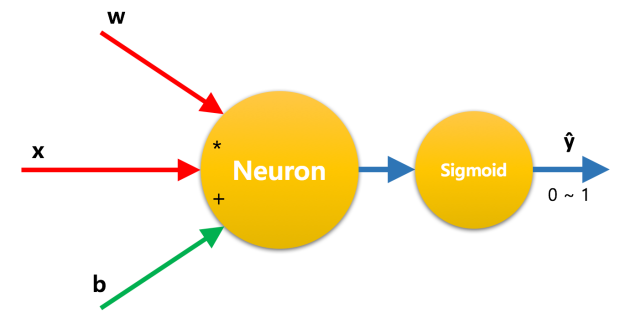
그림 10. 로지스틱 회귀 모델의 뉴런
로지스틱 회귀 분석의 비용 함수는 크로스 엔트로피(Cross Entropy)라는 방법을 사용합니다. 이게 어떤 것인지 자세히 설명할 순 없지만 결론만 요약하면 출력의 종류에 따라 예측한 확률과 진짜 확률을 곱해서 합한 것입니다. 우리의 로지스틱 회귀에서는 훈련 데이터의 타겟 값은 악성(0) 아니면 양성(1) 두가지 입니다. 그리고 모델을 통해 예측한 값은 데이터가 양성(1)일 확률입니다.
모든 데이터에 대해 양성 확률과 악성 확률이 있습니다. 타겟이 양성일 때 양성 확률은 1, 악성 확률은 0 이죠. 반대로 타겟이 악성일 땐 양성 확률이 0 이고 악성 확률은 1 입니다. 너무 당연한 거지만 말이 좀 헷갈릴 때가 있습니다. 이를 이해하기 쉽게 벡터 형태로 표현하면 아래와 같습니다. 이 벡터에서 첫번째 요소가 악성, 두번째 요소가 양성에 해당합니다.
타겟이 양성(y=1)일 때 확률분포 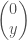
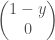
우리가 모델을 만들어 계산한 값은 양성일 가능성을 예측한 확률입니다. 그럼 악성일 확률은 어떻게 구할까요? 악성일 땐 ‘1 – 양성 확율’ 이됩니다.
예측한 확률분포

이제 크로스 엔트로피를 구하려면 예측 확률에 로그를 씌워 두 확률을 곱하면 됩니다. 양성일 때와 악성일 때를 각각 나누어 벡터의 스칼라 곱을하면,

로지스틱 회귀의 비용 함수는 이것에 음수를 취한 값입니다.
![J = - \dfrac{1}{m} \sum_{i=1}^{m}p log(q) = -\dfrac{1}{m} \sum_{i=1}^{m}[ylog(\hat{y}) + (1-y)log(1-\hat{y})]](https://s0.wp.com/latex.php?latex=J+%3D+-+%5Cdfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi%3D1%7D%5E%7Bm%7Dp+log%28q%29+%3D+-%5Cdfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5Bylog%28%5Chat%7By%7D%29+%2B+%281-y%29log%281-%5Chat%7By%7D%29%5D&bg=ffffff&fg=444444&s=0&c=20201002)
이 식은 자세히 보면 원래 크로스 엔트로피 공식에 약간의 트릭을 적용한 것으로도 볼 수 있습니다. 악성(y=0)일 때는 뒷 항만 남아 악성 확률을 누적하고 양성(y=1)일 때는 앞 항만 남게되어 양성 확률을 더하게 됩니다. 사실 이 공식을 외우거나 할 필요는 전혀 없습니다. 하지만 모든 책에서 나오는 공식이라 언급을 안할 수가 없네요. 이제 경사하강법을 적용하려면 이 식을 미분해야 합니다. 하지만 여기서 미분까지 하지는 않겠습니다. 중요한 것은 결과인데요. 미분한 결과를 보시죠.
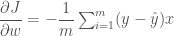
어 이건 앞에서 본 선형 회귀의 미분 결과와 동일하지 않은가요? 네 맞습니다. 동일합니다. 그러면 우리가 사용했던 클래스를 거의 그대로 쓸 수 있겠네요. 다만 시그모이드 함수 정도는 적용해 줄 필요가 있겠습니다. 새로운 클래스의 이름을 LogisticNeuron 으로 하겠습니다.
class LogisticNeuron(object):
···
def forpass(self, x):
"""정방향 수식 w * x + b 를 계산하고 결과를 리턴합니다."""
self._x = x
_y_hat = self._w * self._x + self._b
return self._sigmoid(_y_hat)
···
def fit(self, X, y, n_iter=10, lr=0.1, cost_check=False, l2=0):
"""정방향 계산을 하고 역방향으로 에러를 전파시키면서 모델을 최적화시킵니다."""
cost = []
for i in range(n_iter):
y_hat = self.forpass(X)
error = y - y_hat
self.backprop(error, lr)
self.update_grad(l2/len(y))
if cost_check:
cost.append(np.sum(- y * np.log(y_hat) - (1-y) * np.log(1-y_hat))/len(y))
return cost
def predict(self, X):
y_hat = self.forpass(X)
y_hat[y_hat >= 0.5] = 1
y_hat[y_hat < 0.5] = 0
return y_hat
def _sigmoid(self, y_hat):
return 1 / (1 + np.exp(-y_hat))
SingleNeuron 에 비해 변경한 것은 forpass 함수의 리턴 값에 시그모이드 함수를 적용한 것과 cost 변수에 저장할 비용 계산 식을 바꾸었습니다. 그리고 y_hat 의 확률에 따라 양성(1)인지 악성(0)인지를 판별하는 predict 메소드를 추가하였습니다. 자연 로그 계산을 위해서 넘파이의 np.log 함수를 사용하였고 지수 계산을 위해서 np.exp 함수를 사용했습니다.
먼저 train_test_split 함수를 사용하여 훈련 데이터와 테스트 데이터를 나눕니다.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, \ test_size=0.1, random_state=10)
‘mean concave points’ 컬럼을 사용할 때 주의할 점은 위에서 살짝 보았듯이 정규화 되어 있지 않고 매우 작은 수치들로 편중되어 있습니다. 학습을 효율적으로 하기위해 사이킷런의 scale 함수로 정규화시켜서 사용해야 합니다.
그런 다음 LogisticNeuron 의 인스턴스를 만들고 훈련을 시키는 과정은 이전과 동일합니다. 분류 문제에서 모델을 평가하는 방법 중 하나가 몇개가 맞았는지를 재는 것입니다. 직접 헤아릴 수도 있지만 편리하게 사이킷런의 accuracy_score 를 사용하겠습니다.
from sklearn.preprocessing import scale from sklearn.metrics import accuracy_score n3 = LogisticNeuron() n3.set_params(1, 1) cost = n3.fit(scale(X_train[:,7]), y_train, n_iter=100, cost_check=True) y_hat = n3.predict(scale(X_test[:,7])) print(accuracy_score(y_test, y_hat))
0.947368421053
94.7% 면 꽤 훌륭하네요. fit 메소드에서 계산한 비용 값을 그래프로 그려 보겠습니다.
plt.plot(list(range(100)), np.array(cost)) plt.show()
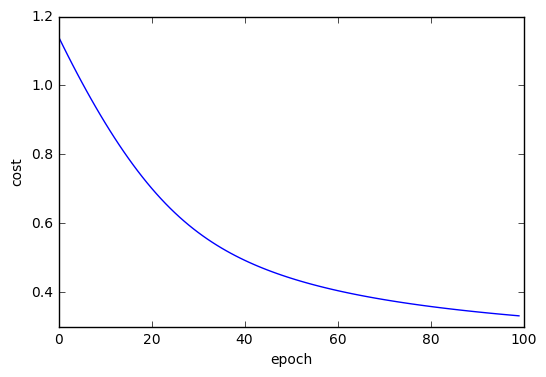
그림 11. 로지스틱 회귀의 비용 함수 감소 그래프
로지스틱 회귀 분석을 경사 하강법으로 학습시켰는데 비용 함수가 잘 감소하고 있는 모습을 확인할 수 있습니다. 머신러닝에서 경사하강법을 사용해 계속 반복할 때 이 반복을 에포크(epoch)라고 부릅니다. 그래서 위 그래프에서 X 축의 이름을 epoch 라고 썼습니다.
사이킷런에서는
사이킷런에도 당연히 로지스틱 회귀 분석을 위한 함수가 있습니다. LogisticRegression 함수가 있지만 여기에서는 경사 하강법을 사용하는 SGDClassifier 를 사용해 보겠습니다. SGDClassifier 의 인스턴스를 생성할 때 반복은 100번으로 하고 L1 이나 L2 정형화는 사용하지 않겠습니다. loss 파라메타는 비용 함수의 종류를 적는 것으로 log 가 로지스틱 회귀를 의미합니다. 모델을 훈련시키고 추론(predict)하여 스코어를 재는 것은 이전과 동일합니다.
사이킷런은 내부적으로 자동으로 입력 데이터를 표준화해주므로 우리가 직접 scale 함수를 사용할 필요가 없습니다. 훈련 데이터와 테스트 데이터에서 7번 인덱스 컬럼(‘mean concave points’)만 추출을 하면 하나의 행에 열 방향으로 죽늘어진 행렬이 나옵니다. 사이킷런에 입력할 때는 입력 데이터가 행 방향으로 세로로 길게 늘어져서 전달되어야 하므로 reshape 명령을 사용하여 열을 1 로 하는 행렬로 변환하여 전달합니다.
from sklearn.linear_model import SGDClassifier lg_regr = SGDClassifier(loss='log', n_iter=100, penalty='none') lg_regr.fit(X_train[:,7].reshape(-1,1), y_train) y_hat = lg_regr.predict(X_test[:,7].reshape(-1,1)) print(accuracy_score(y_test, y_hat))
0.947368421053
이 모델은 단순한 예제라 우리와 스코어 값이 정확히 일치하네요. 하지만 복잡한 문제라면 정형화나 학습속도 등 여러 하이퍼 파라메타에 따라 조금씩 차이가 날 수 있습니다.
다음장에서는
다음장에서는 여기에서 익힌 로직스틱 회귀와 활성화 함수 등을 응용해서 여러개의 뉴런이 쌓여 올려진 뉴럴 네트워크를 구성해 보도록 하겠습니다. 참고를 위해 아래 전체 LogisticNeuron 클래스의 코드를 싣습니다.
import numpy as np
class LogisticNeuron(object):
def __init__(self):
self._w = 0 # 가중치 w
self._b = 0 # 바이어스 b
self._w_grad = 0
self._b_grad = 0
self._x = 0 # 입력값 x
def set_params(self, w, b):
"""가중치와 바이어스를 저장합니다."""
self._w = w
self._b = b
def forpass(self, x):
"""정방향 수식 w * x + b 를 계산하고 결과를 리턴합니다."""
self._x = x
_y_hat = self._w * self._x + self._b
return self._sigmoid(_y_hat)
def backprop(self, err, lr=0.1):
"""에러를 입력받아 가중치와 바이어스의 변화율을 곱하고 평균을 낸 후 감쇠된 변경량을 저장합니다."""
m = len(self._x)
self._w_grad = lr * np.sum(err * self._x) / m
self._b_grad = lr * np.sum(err * 1) / m
def update_grad(self, l2=0):
"""계산된 파라메타의 변경량을 업데이트하여 새로운 파라메타를 셋팅합니다."""
self.set_params(self._w + self._w_grad - l2 * self._w, self._b + self._b_grad)
def fit(self, X, y, n_iter=10, lr=0.1, cost_check=False, l2=0):
"""정방향 계산을 하고 역방향으로 에러를 전파시키면서 모델을 최적화시킵니다."""
cost = []
for i in range(n_iter):
y_hat = self.forpass(X)
error = y - y_hat
self.backprop(error, lr)
self.update_grad(l2/len(y))
if cost_check:
cost.append(np.sum(- y * np.log(y_hat) - (1-y) * np.log(1-y_hat))/len(y))
return cost
def predict(self, X):
y_hat = self.forpass(X)
y_hat[y_hat >= 0.5] = 1
y_hat[y_hat < 0.5] = 0
return y_hat
def _sigmoid(self, y_hat):
return 1 / (1 + np.exp(-y_hat))

L1 정형화 L2 정형화 설명하실때 L1 L2 패널티 부분의 앞에 곱해지는 분수의 값에서 분모가 m이 맞는 것인지요? n 아닌가요?
좋아요좋아요
안녕하세요. l2 페널티는 샘플의 수로 나누는 것이 보통입니다. 만약에 n으로 나누면 배치, 미니배치, 확률적 경사 하강법에 따라서 람다의 크기가 달라져야 하거든요. 확실히 이건 기대하는 바는 아닙니다. ^^
좋아요좋아요
정말 기본적인 질문이지만, 학습 속도에 따른 [1.999, 1.0, 0.1] 그래프 가시화 할 때 왜 마지막 black밖에 안나올까요… for문 지우고 하나씩 써봐도 마지막 black만 나오네요… 하나씩 하거나 figure(i)를 사용하면 따로는 잘나옵니다. 뭐가 문제인지 모르겠네요 ㅠㅠ
글은 언제나 잘 읽고 열심히 배우고 있습니다. 좋은 글 감사드립니다.
좋아요좋아요
아마도 matplotlib 새 버전 때문이지 않을까 생각이 드네요. 제가 시간내서 최신 버전에서 노트북을 다시 돌려 보고 회신 드리겠습니다. ^^
좋아요좋아요
아앗…!! 해결했습니다!!
제 실수였네요! 죄송합니다 ㅠㅠ
lr learning rate를 일정하게 하는 바람에 다 겹쳐서 마지막 블랙만 나오는거였네요 ^^ 답변 감사드립니다!
좋아요Liked by 1명
오 다행이네요. ㅎㅎ 즐거운 주말 되세요.
좋아요좋아요
크로스 밸리데이션에서 첫번째 오차가 이상하게 나오네요… n1.set_params(5, 1)로 진행하고 lr는 (1.2, 1.0, 0.8)로 했는데 2번째 3번째는 맞으나 1번째가 어떻게 수정해도 게시글과 같이는 안나옵니다. 랜덤스테이트도 10으로 맞췄습니다. 혹시 train test split을 안하고 하는건가 해도 안되네요..
뭐 개념이해에 문제는 없지만 궁금해서 질문 올립니다. 아래는 코드와 실행 결과입니다.
4006.57150514
4006.43602691
4005.6619766
CODE ———————————————————————————————
kf = KFold(n_splits=5, shuffle=True, random_state=10)
diabetes = datasets.load_diabetes()
x_train, x_test, y_train, y_test = train_test_split(diabetes.data[:, 2], diabetes.target,
test_size=0.1, random_state=10)
sn = GradientDescent.SingleNeuron()
sn.set_params(5, 1)
learning_rate = [1.2, 1.0, 0.8]
for lr in learning_rate:
validation_errors = 0
for train, validation in kf.split(x_train):
sn.fit(x_train[train], y_train[train], 2000, lr)
y_hat = sn.forpass(x_train[validation])
validation_errors += metrics.mean_squared_error(y_train[validation], y_hat)
print(validation_errors/5)
RESULT ————————————————————————————
4006.57150514
4006.43602691
4005.6619766
좋아요좋아요
scikit-learn 0.18.1에서 랜덤 샘플링에 변화가 있었습니다. 그래서 랜덤스테이트의 결과가 조금 달라질 수 있습니다. ^^
좋아요좋아요
감사합니다. 작성자님도 즐거운 주말 되세요!
좋아요좋아요
다시 읽는데 이부분 :
이 함수에 로그를 취한 것을 로짓(logit) 함수라고 합니다. 로짓함수는 p 가 0.5 일 때 0이 되고 p 가 1 일 때 무한히 큰 양수, p 가 -1 일 때 무한히 큰 음수가 되는 특징을 가지게 됩니다.
p 가 0일때 무한히 큰 음수 아닌가요?
좋아요좋아요
이크 맞습니다. 오류를 찾아 주셔서 감사드려요. ^^
좋아요좋아요
안녕하세요 작성자님! 게시글 보며 열심히 배우고 있는 학부생입니다.
질문이 있습니다!
그림1 학습 속도에 따른 비용 감소 그래프를 출력하기 위해 나와있는 소스 그대로 입력하였더니
plt.plot(list(range(2000)), costs[i], color=color) 이 부분에서 자꾸 에러가 나옵니다.
에러 내용은
x and y must have same fists dimenstion, but have shapes (2000,) and (1,) 입니다.
그래프의 차원 문제 즉, plot 함수의 list(range(2000)) 부분에서 오류가 발생하는 것 같은데
확인 가능하시다면 답변 부탁드립니다. 감사합니다~
좋아요좋아요
수정, 에러 내용 부분에서 fists -> first입니다.
좋아요좋아요
혹시 파이썬 버전이 2.7 이신가요?
좋아요좋아요
아니요 파이썬 3.6 버전입니다.
좋아요좋아요
에러를 보니 costs 리스트의 원소가 하나 밖에 없는 것 같습니다. costs 를 프린트해서 확인해 보세요.
좋아요좋아요
costs = []
learning_rate = [1.999, 1.0, 0.1]
for lr in learning_rate:
n1.set_params(5, 1)
costs.append([])
costs[-1] = n1.fit(X_train, y_train, 2000, lr, True)
이 부분에서 반복 변수 lr을 learning_rate로 받는 이유는
각각의 확률에 대해서
fit함수를 통해 2천번의 반복을 시행하겠다는 뜻 아닌가요?
좋아요좋아요
print(costs) 의 결과값으로
28495.957032517155
28495.957032517155
28495.957032517155
동일한 값으로 3개가 찍혀있네요
좋아요좋아요
네 아무래도 반복이 제대로 일어나지 않은 것 같네요. LogisticNeuron 클래스의 코드를 다시 한번 검토해 보시겠어요.(https://github.com/rickiepark/ml-learn/blob/master/notebooks/4.%20breast_cancer.ipynb)
좋아요좋아요
네 알겠습니다. 답변 감사합니다 !
좋아요Liked by 1명
작성자님 게시글과 깃허브의 소스에서 SingleNeuron class 가 상이한 것을 발견했습니다.
아래 소스는 깃허브에 있는 작성자님의 class 소스입니다.
class SingleNeuron(object):
def __init__(self):
self._w = 0 # 가중치 w
self._b = 0 # 바이어스 b
self._w_grad = 0
self._b_grad = 0
self._x = 0 # 입력값 x
def set_params(self, w, b):
“””가중치와 바이어스를 저장합니다.”””
self._w = w
self._b = b
def forpass(self, x):
“””정방향 수식 w * x + b 를 계산하고 결과를 리턴합니다.”””
self._x = x
_y_hat = self._w * self._x + self._b
return _y_hat
def backprop(self, err, lr=0.1):
“””에러를 입력받아 가중치와 바이어스의 변화율을 곱하고 평균을 낸 후 감쇠된 변경량을 저장합니다.”””
m = len(self._x)
self._w_grad = lr * np.sum(err * self._x) / m
self._b_grad = lr * np.sum(err * 1) / m
def update_grad(self, l2=0):
“””계산된 파라메타의 변경량을 업데이트하여 새로운 파라메타를 셋팅합니다.”””
self.set_params(self._w + self._w_grad – l2 * self._w, self._b + self._b_grad)
def fit(self, X, y, n_iter=10, lr=0.1, cost_check=False, l2=0):
“””정방향 계산을 하고 역방향으로 에러를 전파시키면서 모델을 최적화시킵니다.”””
cost = []
for i in range(n_iter):
y_hat = self.forpass(X)
error = y – y_hat
self.backprop(error, lr)
self.update_grad(l2/len(y))
if cost_check:
cost.append(np.sum(np.square(y – y_hat))/len(y))
return cost
좋아요좋아요
죄송하지만 어느 라인이 다른지 말씀해 주실 수 있을까요? ^^
좋아요좋아요
맨 아랫 라인 return cost 부분이 첫번째 설명 부분에서는 for loop 안에 들어가 있어서
처음부터 따라하시는 분들은 cost값이 list가 아닌 1개 값만 리턴됩니다~~
좋아요좋아요
엇 이런 실수가.. ㅠ.ㅠ 오류를 찾아 주셔서 감사드립니다! 즐거운 주말 되세요. : )
좋아요좋아요
오늘도 많이 배우고 갑니다:)
좋아요Liked by 1명