한달 전에 스탠포드 비전 랩의 안드레이 카패시(Andrej Karpathy)가 블로그에 강화학습에 대한 글인 ‘Deep Reinforcement Learning: Pong from Pixels‘를 올렸었습니다. 조금 늦었지만 블로그의 글을 따라가 보려고 합니다. 안드레이는 스탠포드 뿐만이 아니라 구글과 OpenAI에서도 여러 프로젝트에 참여했고 강화학습과 관련된 여러 도서를 읽고 관련 강의도 들었다고 합니다. 강화학습을 쉽게 소개하기 위해 글을 썼다고 하는데 말처럼 쉽지는 않은 것 같습니다.


OpenAI 짐(Gym)은 강화학습 알고리즘을 훈련시키고 평가할 수 있는 프레임워크입니다. 짐에 포함된 퐁(Pong) 게임은 아타리(Atari) 2600에 포함된 간단한 컴퓨터 게임의 시뮬레이션 버전입니다. 두사람이 오른쪽과 왼쪽에 있는 자기 막대를 움직여 공을 받아 넘겨야 하고 상대방이 놓쳐서 화면 옆으로 사라지면 점수를 1점 얻게 됩니다(이를 편의상 한 판이라고 부르겠습니다). 이렇게 점수를 획득하여 가장 먼저 21점을 얻는 쪽이 이기는 게임입니다. 짐에서는 화면의 왼쪽 편이 하드 코딩되어 있는 컴퓨터 에이전트이고 오른쪽 편이 강화학습을 통해 우리가 학습시켜야할 에이전트입니다.
짐 라이브러리에서는 공이 위치가 이동되었을 때를 한 스텝(step)이라고 표현합니다. 게임 화면에서 공이 이동할 때 마다 스크린샷을 찍는다고 생각하면 비슷합니다. 매 스텝마다 짐은 우리에게 리워드(reward)를 줍니다. 이겼을 때는 1, 졌을 때는 -1, 이도저도 아닌 공이 게임 판 위를 여전히 돌아다니고 있는 중간에는 0을 리턴합니다. 우리는 매 스텝마다 막대의 위치를 위로 올릴 것인지(UP), 아래로 내릴 것인지(DOWN)를 결정하여 짐 라이브러리에 전달합니다. 게임을 이길 수 있도록 막대의 위치를 제어하는 것이 우리가 풀어야 할 숙제입니다.
우리가 이겼다는 것은 컴퓨터 에이전트가 볼을 받아내지 못해서 왼쪽편 화면 너머로 사라졌다는 것을 말합니다. 보통 한 판을 이기려면 수십에서 많게는 백번이 넘는 스텝이 발생할 수 있습니다. 어쨋든 다행이 우리 에이전트가 이겨서 리워드 1점을 받았다면 이 점수를 어떤 스텝의 막대위치나 그 결정에 반영해야 할까요? 리워드 1점을 받기 전까지의 수십번의 스텝은 모두 리워드 0을 받게 됩니다. 이 중에 어떤 스텝에게 보상을 주어야 조금 더 게임을 이길 수 있는 방향으로 발전하게 될까요?
매 스텝마다 어떤 방향(UP, DOWN)으로 막대를 움직여야 할지 정답을 알고 있다고 가정하면 지도학습(supervised learning) 방식을 사용할 수 있습니다. 아래 그림처럼 퐁 게임의 이미지를 뉴럴 네트워크에 전달하여 UP과 DOWN의 확률을 계산한 후 우리가 알고 있는 정답(레이블)이 UP이라면 UP의 확률을 높이기 위해 UP에 그래디언트 1.0을 부여하여 백프로파게이션 알고리즘으로 뉴럴 네트워크를 학습시킬 수 있습니다.

출처: 안드레이 카패시 블로그
여기에서 확률을 0.3, 0.7 처럼 사용하지 않고 자연로그를 취한 값을 사용했습니다.


이렇게 한 이유는 뒤에 나올 강화학습 알고리즘을 미분하면 로그함수가 나오기 때문에 아예 로그 확률을 최적화하는 것이 수학적으로도 깔끔하고 계산도 편하기 때문입니다. 로그함수는 기울기 값이 변하지 않기 때문에(좀 더 정확하게 말하면 로그함수는 단조함수, 즉 항상 증가하거나 감소만 하기 때문입니다. 지적해주신 이창환님 감사드립니다.) 일반 확률 함수를 최적화 하는 것과 로그 확률 함수을 최적화하는 것에 차이가 없습니다. 우리가 백프로파게이션으로 학습시킬 그래디언트를 구하기 위해 주어진 이미지 x 에 대한 UP 로그 확률 함수의 편미분 방정식을 쓴다면 아래와 같습니다.
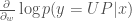
예를 들어 어떤 입력 이미지에 대해 UP 확률을 높이기 위해 백프로파게이션 알고리즘으로 뉴럴 네트워크의 그래디언트를 계산하였습니다. 이 중 하나의 그래디언트 값이 -2.1 이라고 한다면 임의의 학습 속도(learning rate) 0.001 을 반영하여 이 엣지의 가중치의 값에 -2.1 x 0.001 만큼 더합니다. 음수가 더해지므로 가중치 값은 더 작아지게 될 것입니다. 이런식으로 뉴럴 네트워크의 가중치가 업데이트 되면 다음번에 유사한 이미지가 입력되었을 때 UP을 선택할 확률이 높아지게 될 것입니다.
그런데 우리는 퐁 게임에서 매 스텝의 결정에 대한 정답, 즉 옳은 레이블을 알고 있지 못합니다. 어떤 결정을 하더라도 그 판에서 승리할 수 있을지 없을지는 한참 뒤에나 알게 됩니다. 앞의 예에서 UP의 확률이 0.3(로그확률 -1.2)이고 DOWN의 확률이 0.7(로그확률 -0.36)이 나왔습니다. 이 때 확률에 비례하여 랜덤하게 UP, DOWN을 뽑았더니 DOWN이 선택되었다고 합시다. 우리가 정답을 알고 있는 지도학습이라면 DOWN에 그래디언트 1.0을 부여해서 백프로파게이션을 실행할 수 있을 겁니다. 하지만 지금으로서는 DOWN이 좋은 것인지 아닌지를 알 수가 없습니다. 이럴 경우엔 어떻게 할까요? 바로 폴러시 그래디언트를 사용합니다.
안드레이는 이 글에서 사용할 강화학습 알고리즘으로 딥 큐 러닝(Deep Q Learning)을 사용하지 않고 폴러시 그래디언트(Policy Gradient)를 채택했습니다. 딥 큐 러닝이 널리 알려지긴 했지만 알파고도 그렇고 최근에는 많은 사람들이 폴러시 그래디언트 방식을 좋아한다고 합니다. 저는 이 주장을 뒷받침하거나 혹은 반대할 만한 지식을 가지고 있지 않습니다. 다만 안드레이의 경력을 미루어보아 그의 견해를 받아들일 뿐입니다.
폴러시 그래디언트의 방식은 다음과 같습니다. 위 경우 DOWN을 선택하고 나서 바로 백프로파게이션을 하지 않고 상황을 잠시 두고 봅니다. 결국 게임에서 졌다면 리워드로 -1을 받게 되어 DOWN은 옳은 선택이 아니었습니다. DOWN에 그래디언트 -1을 부여해서 이 결정을 감쇠시킬 수 있도록 백프로파게이션을 합니다. 즉 포워드 패스에서 얻은 확률을 기반으로 UP, DOWN을 랜덤하게 선택하고 이런 액션(UP or DOWN)들이 쌓여서 결국 게임을 이기게 만들었다면 그 액션들을 강화시키도록 백프로파게이션 하고 게임을 지게 만들었다면 그 액션들을 감쇠시키도록 백프로파게이션 하는 것입니다.

출처: 안드레이 카패시 블로그
사실 이러한 방식은 올바른 리워드를 충분히 얻을 수 있는 상황이어야 가능합니다. 그리고 리워드를 얻기위해 여러번의 시도를 하는 것이 우리 주변에 나쁜 영향을 미치지 않는 경우 이런 학습방법을 사용할 수 있을 것 같습니다. 구체적으로 예를 들면 100번의 게임에서 각 게임의 스텝은 200번이라고 가정하면 총 20,000번의 UP 혹은 DOWN 결정이 있습니다. 이 중에 12번으 이기고 88번은 졌다고 하면 12×200 = 2400 개의 결정은 양수값으로 백프로파게이션 하고 나머지 88×200 = 17600은 음수값을 사용하여 해당 결정이 감쇠되는 방향으로 가중치가 업데이트 되도록 백프로파게이션 합니다.
조금 더 이론적으로 살펴 보면 우리가 주어진 이미지에 대해 선택한 액션(
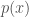
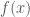
![J(\theta) = E_x[f(x)] = \sum_{x} p(x)f(x)](https://s0.wp.com/latex.php?latex=J%28%5Ctheta%29+%3D+E_x%5Bf%28x%29%5D+%3D+%5Csum_%7Bx%7D+p%28x%29f%28x%29&bg=ffffff&fg=444444&s=0&c=20201002)

![\frac{\partial}{\partial_\theta} E_x[f(x)] = \frac{\partial}{\partial_\theta} \sum_x p(x)f(x) = \sum_x \frac{\partial}{\partial_\theta} p(x)f(x)](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial_%5Ctheta%7D+E_x%5Bf%28x%29%5D+%3D+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial_%5Ctheta%7D+%5Csum_x+p%28x%29f%28x%29+%3D+%5Csum_x+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial_%5Ctheta%7D+p%28x%29f%28x%29&bg=ffffff&fg=444444&s=0&c=20201002)

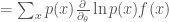

![= E_x[f(x) \frac{\partial}{\partial_\theta} \ln p(x)]](https://s0.wp.com/latex.php?latex=%3D+E_x%5Bf%28x%29%C2%A0%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial_%5Ctheta%7D+%5Cln+p%28x%29%5D&bg=ffffff&fg=444444&s=0&c=20201002)
이 식은 우리가 어떻게 액션을 최적화해 가야할 지를 보여주고 있습니다. 스코어 함수 

출처: 안드레이 카패시 블로그
이제 코드를 따라가 보겠습니다. 아래 코드는 원 코드를 이해하기 쉬운 순서대로 재배치한 것 입니다. 모델을 학습시키기 위해서는 원래 안드레이의 코드를 이용해야 합니다. 제가 학습시킨 버전은 깃허브에서 확인할 수 있습니다. 짐의 설치에 대해서는 이전 포스팅 ‘OpenAI Gym 맥북 설치‘을 참고해 주세요.
퐁 게임의 화면은 210×160 사이즈입니다(아래 왼쪽 그림). 위 퐁 게임화면에서 볼 수 있듯이 게임영역이 아닌 위,아래 부분을 제거하여 160×160 으로 만듭니다(아래 가운데 그림). 그런 후에 픽셀을 하나씩 건너 뛰어 다운 샘플링된 80×80 이미지를 만듭니다(아래 오른쪽 그림). 컬러 채널은 큰 의미가 없으므로 모두 흑백 처리하고 막대와 볼만 구별되게 합니다.



짐 라이브러리를 임포트하고 퐁 게임 환경을 만듭니다. 게임은 한 판을 이기면 리워드 1점을 얻게 되고 21점을 먼저 얻으면 종료되는데 이를 한 에피소드라고 부르겠습니다. 아래 reset() 메소드는 새로운 에피소드를 시작하게 하고 첫번째 이미지 컷을 리턴합니다.
import gym
..
env = gym.make("Pong-v0")
observation = env.reset()
게임의 모션을 캡쳐하기 위해 현재 이미지에서 이전 이미지를 뺍니다. 우리가 가지고 있는 이미지는 prepos 함수에서 전처리한 80×80 = 6400 개의 엘리먼트를 가지는 numpy 배열로 볼이나 막대는 1로 값이 채워져 있습니다. 따라서 두 이미지를 빼게 되면 이전 프레임의 위치에 -1 값이 들어가게 됩니다.
cur_x = prepro(observation) x = cur_x - prev_x prev_x = cur_x
여기서 만들 뉴럴 네트워크는 입력 레이어가 6400개이고 히든 레이어가 200개입니다. 초기 가중치는 입력 레이어 갯수의 루트 값으로 나눈 랜덤 값을 부여합니다.(참고)
H = 200 D = 80 * 80 # input dimensionality: 80x80 grid model['W1'] = np.random.randn(H,D) / np.sqrt(D) model['W2'] = np.random.randn(H) / np.sqrt(H)
10번의 에피소드를 진행한 후에 모델 파라메타를 수정하므로 그동안 계산된 그래디언트를 저장해 놓을 버퍼와 RMSProp 캐시를 생성합니다.
grad_buffer = { k : np.zeros_like(v) for k,v in model.iteritems() }
rmsprop_cache = { k : np.zeros_like(v) for k,v in model.iteritems() }
이제 포워드 패스를 통해 UP, DOWN 액션의 확률을 구합니다. 히든 레이어에서 가중치 W1과 입력값 x를 곱한 후 렐루(ReLU) 함수를 통과 시킨 후 출력 레이어로 전달 합니다. 출력 레이어에서는 가중치 W2를 곱하고 시그모이드 함수를 활성화 함수로 사용합니다.
h = np.dot(model['W1'], x) h[h<0] = 0 # ReLU nonlinearity logp = np.dot(model['W2'], h) p = sigmoid(logp)
그리고 백프로파게이션을 위해 입력값과 히든 유닛의 중간값(h)을 모두 저장합니다. 결정될 액션은 랜덤하게 0~1 사이의 값을 뽑아서 시그모이드 함수를 거쳐 구한 확률 보다 작으면 UP(2), 크면 DOWN(3)으로 결정합니다. UP일 경우 1에서 확률값을 빼고 DOWN일 경우 확률의 음수값을 취해 로그 확률의 그래디언트로 정합니다.(참고)
xs.append(x) # observation hs.append(h) # hidden state y = 1 if action == 2 else 0 dlogps.append(y - aprob)
게임을 한 스텝씩 증가시키면서 새로운 이미지와 리워드 그리고 에피소드가 끝났는지를 확인합니다. 받은 리워드는 모두 저장합니다.
observation, reward, done, info = env.step(action) drs.append(reward)
한개의 에피소드가 끝나면(done == True) 백프로파게이션 계산을 위해 저장한 입력값 들을 numpy 배열로 변경하고 디스카운트 리워드를 계산합니다. epx, eph, epdlogp, epr 은 한 에피소드에서 일어난 모든 스텝을 저장하고 있게 됩니다. 각각 epx는 스텝수x6400, eph는 스텝수x200 이고 epdlogp 와 epr 은 스텝수x1 의 행렬입니다. 디스카운트 된 epr 도 동일한 차원을 가집니다.
epx = np.vstack(xs) eph = np.vstack(hs) epdlogp = np.vstack(dlogps) epr = np.vstack(drs) .. discounted_epr = discount_rewards(epr) discounted_epr -= np.mean(discounted_epr) discounted_epr /= np.std(discounted_epr)
앞서 공식에서 유도되었듯이 폴러시 그래디언트의 핵심은 리워드 값과 로그 확률을 곱하는 것 입니다.
epdlogp *= discounted_epr
이제 백프로파게이션을 수행합니다. 히든 유닛의 가중치를 저장하고 있는 eph의 전치행렬(200x스텝수)를 구해 epdlogp를 곱한 후 1차원으로 변경합니다. 결국 dW2는 200개의 엘리먼트를 가진 배열이 됩니다. dW1을 구하기 위해서 epdlogp와 모델 파라메타 W2를 외적하여 스텝수x200 행렬을 만들고 eph가 음수인 위치의 dh 값을 0으로 바꿉니다. 마지막으로 dh의 전치행렬(200x스텝수)과 epx(스텝수x6400)를 곱하여 200×6400의 차원을 가진 dW1을 만듭니다.
dW2 = np.dot(eph.T, epdlogp).ravel() dh = np.outer(epdlogp, model['W2']) dh[eph <= 0] = 0 # backpro prelu dW1 = np.dot(dh.T, epx)
이렇게 계산된 dW1과 dW2를 grad_buffer 변수에 누적하여 저장합니다. 10개의 에피소드가 끝나면 grad_buffer에 누적된 값을 이용하여 rmsprop_cache 값을 계산하고 학습속도를 적용하여 모델 파라메타를 변경합니다.
# k is 'W1', 'W2' g = grad_buffer[k] rmsprop_cache[k] = decay_rate * rmsprop_cache[k] + (1 - decay_rate) * g**2 model[k] += learning_rate * g / (np.sqrt(rmsprop_cache[k]) + 1e-5)
그런 다음 짐 환경을 다시 리셋하고 새로운 에피소드를 시작하여 동일한 과정을 반복합니다. 이 스크립트는 업데이트 된 모델 파라메타를 ‘save.p’ 란 파일에 저장합니다. 스크립트 맨 위의 resume 파라메타를 True 로 바꿔주면 필요에 따라 스크립트를 중지했다가 다시 실행할 수 있습니다. 그리고 render 파라메타를 True 로 바꿔주면 퐁 게임이 시뮬레이션 되는 것을 화면으로 볼 수 있습니다. 하지만 게임 진행 속도는 더디게 됩니다.
resume = True render = False
이와 같이 폴러시 그래디언트는 미분가능하지 않은 그래서 백프로파게이션을 사용할 수 없는 상황에 적용할 수 있는 방법이라고 합니다. 시간이 부족하여 디스카운트 리워드나 이 블로그에서 언급한 관련 자료, 또 사례에 대해 더 깊이 있게 보지는 못했습니다. 아래는 제 노트북에서 학습한 모델의 결과를 캡쳐한 것입니다. 띄엄띄엄 대략 3일정도 학습하니 컴퓨터 에이전트와 대략 비슷하게 게임을 진행하는 것을 볼 수 있었습니다. 코드와 학습된 모델 파라메타는 깃허브에 올려 놓았습니다.
OpenAI 사이트에 가면 퐁 게임을 비롯하여 여러 게임에 대하여 강화학습을 시뮬레이션 한 것을 볼 수 있으며 작성된 코드와 알고리즘에 대한 인사이트를 얻을 수 있습니다.
학습을 위해 알고리즘 코드를 보는 것이 좋다고 해서 쫓아가 보았는데 많이 어려운 것 같습니다. 아마도 텐서플로우를 이용하면 조금 더 좋은 모델을 학습시킬 수 있지 않을까 생각됩니다. 강화학습과 짐에 대한 더 좋은 정보는 모두의연구소의 이웅원님의 자료에서 찾을 수 있을 것 같습니다. 🙂
잘못된 부분이나 부족한 점은 댓글로 보안해 주세요.
(업데이트) 원문을 번역한 퀸메리대학의 최근우님의 블로그를 소개해 드립니다. 함께 보시면 좋을 것 같습니다.

강화학습을 공부하는 중인 학생입니다.
“여기에서 확률을 0.3, 0.7 처럼 사용하지 않고 자연로그를 취한 값을 사용했습니다.” 이후의 내용 서술이 잘 이해가 가지 않아서 원문(http://karpathy.github.io/2016/05/31/rl/)을 참고해 보았습니다.
특히 제가 이상하게 생각한 부분은 “로그함수는 기울기 값이 변하지 않기 때문에 일반 확률 함수를 최적화 하는 것과 로그 확률 함수을 최적화하는 것에 차이가 없습니다” 였습니다. 로그 함수를 미분하면 1/x이고, 이는 결코 상수함수는 아니니까요.
원문을 참고해보니 “this makes math nicer, and is equivalent to optimizing the raw probability because log is monotonic”, 즉 로그함수는 단조 증가함수이기 때문에 0.0~1.0로 표현된 확률을 직접 최적화 하는 것과 같으며, 수학적으로도 간편하다라는 의미였습니다. “기울기 값이 변하지 않기 때문에”를 어떤 의미로 서술한 것인지는 (기울기가 양수가 되었다가 음수가 되었다가 하지 않고, 일정하게 증가하거나 감소하기만 하는) 충분히 알겠지만, 원문을 참고하지 않고서는 정확한 의미를 파악하기 힘들었습니다. ‘증가함수’나 ‘단조 증가함수’로 수정해주시면 다른 분들이 글을 읽을때 도움이 될 것 같습니다.
좋은 글 감사합니다.
좋아요Liked by 1명
네 제가 너무 쉽게 표현하려다 보니 그렇게 된 거 같으네요. 의견 주신대로 보완하도록 하겠습니다. 의견 감사드립니다. ^^
좋아요좋아요