 이 글은 스페인 카탈루냐 공과대학의 Jordi Torres 교수가 텐서플로우를 소개하는 책 ‘First Contack with TensorFlow‘을 번역한 것입니다. 이 글은 원 도서의 라이센스(CC BY-NC-SA 3.0)와 동일한 라이센스를 따릅니다.
이 글은 스페인 카탈루냐 공과대학의 Jordi Torres 교수가 텐서플로우를 소개하는 책 ‘First Contack with TensorFlow‘을 번역한 것입니다. 이 글은 원 도서의 라이센스(CC BY-NC-SA 3.0)와 동일한 라이센스를 따릅니다.
2015년 11월에 처음 나온 텐서플로우 패키지는 GPU를 이용하여 서버 안에서 동시에 모델을 훈련시키는 것이 가능했습니다. 2016년 2월 업데이트에서 분산, 병렬 처리 기능이 추가 되었습니다.(역주: 정식 릴리즈는 4월 0.8 버전입니다)
이 장에서는 GPU를 사용하는 방법에 대해 소개합니다. GPU 디바이스가 어떻게 작동하는지 조금 더 알고 싶은 독자들을 위해 마지막 센션에 참고 링크를 넣도록 하겠습니다. 입문서인 이 책에서는 분산 버전에 대해 깊게 설명하지 않겠습니다만 관심있는 독자들은 마지막 섹션의 참고자료를 확인해 보십시요.
GPU 실행환경
GPU를 지원하는 텐서플로우 패키지를 사용하려면 CudaToolkit 7.0과 CUDNN 6.5 v2 가 필요합니다. 프로그램 설치를 위해 cuda 설치 페이지에서 최신 정보와 자세한 설명을 확인하십시요.
텐서플로우에서 디바이스를 사용하는 방법은 아래와 같습니다.
- “/cpu:0” : 서버의 CPU를 지정함
- “/gpu:0” : 서버의 첫번째 GPU를 지정함
- “/gpu:1” : 서버의 두번째 GPU를 지정함. 유사한 방식으로 계속 지정.
연산이나 텐서가 어떤 디바이스에 할당되었는지 알고 싶다면 세션을 생성할 때 log.device.placement를 true로 지정해 주면 됩니다. 아래 예를 참고해 주세요.
import tensorflow as tf a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') c = tf.matmul(a, b) sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) print sess.run(c)
독자들이 이 코드를 각자 컴퓨터에서 실행해 보면 아래와 유사한 출력이 보일 겁니다.
... Device mapping: /job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: Tesla K40c, pci bus id: 0000:08:00.0 ... b: /job:localhost/replica:0/task:0/gpu:0 a: /job:localhost/replica:0/task:0/gpu:0 MatMul: /job:localhost/replica:0/task:0/gpu:0 … [[ 22.28.] [ 49.64.]] …
또 출력 결과로 부터 어떤 부분이 실행되는지 알 수 있습니다.
만약 특정한 디바이스에서 지정된 연산이 실행되도록 하고 싶다면 시스템이 자동으로 디바이스를 선택하지 않게 하고 tf.device 변수를 사용하여 디바이스 컨텍스트(역주: 파이썬의 컨텍스트 매니저)를 만들 수 있습니다. 그러면 이 컨텍스트 안에서 수행되는 모든 연산은 같은 디바이스에서 수행됩니다.
만약 시스템에 GPU가 하나 이상이라면 작은 인덱스 번호를 갖는 GPU가 디폴트로 선택됩니다. 서로 다른 GPU에서 연산을 실행시키려면 GPU를 명시적으로 지정해야 합니다. 예를 들면 GPU #2에서 위 코드를 실행시키려면 아래와 같이 tf.device(‘/gpu:2’) 로 하면 됩니다.
import tensorflow as tf
with tf.device('/gpu:2'):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print sess.run(c)
GPU 병렬처리
하나 이상의 GPU를 가지고 있다면 당연하게 문제를 해결하기 위해 모든 GPU를 병렬로 사용하고 싶을 것입니다. 이렇게 여러개의 GPU에 일을 시키도록 모델을 구성할 수 있습니다. 다음 예제를 보십시요.
import tensorflow as tf
c = []
for d in ['/gpu:2', '/gpu:3']:
with tf.device(d):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3])
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2])
c.append(tf.matmul(a, b))
with tf.device('/cpu:0'):
sum = tf.add_n(c)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print sess.run(sum)
이 코드는 이전 것과 동일하지만 2개의 GPU에 tf.device 를 사용해 곱셈을 각각 할당하고(간단한 예로 만들려고 두 GPU는 같은 계산을 합니다) 나중에 CPU가 합산을 하도록 했습니다. log_device_placement 를 true 로 지정하여 어떻게 연산이 우리 디바이스(역주: 바르셀로나 수퍼컴퓨팅 센터의 디바이스)에 분산되는지 확인할 수 있습니다.
... Device mapping: /job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: Tesla K40c /job:localhost/replica:0/task:0/gpu:1 -> device: 1, name: Tesla K40c /job:localhost/replica:0/task:0/gpu:2 -> device: 2, name: Tesla K40c /job:localhost/replica:0/task:0/gpu:3 -> device: 3, name: Tesla K40c ... ... Const_3: /job:localhost/replica:0/task:0/gpu:3 I tensorflow/core/common_runtime/simple_placer.cc:289] Const_3: /job:localhost/replica:0/task:0/gpu:3 Const_2: /job:localhost/replica:0/task:0/gpu:3 I tensorflow/core/common_runtime/simple_placer.cc:289] Const_2: /job:localhost/replica:0/task:0/gpu:3 MatMul_1: /job:localhost/replica:0/task:0/gpu:3 I tensorflow/core/common_runtime/simple_placer.cc:289] MatMul_1: /job:localhost/replica:0/task:0/gpu:3 Const_1: /job:localhost/replica:0/task:0/gpu:2 I tensorflow/core/common_runtime/simple_placer.cc:289] Const_1: /job:localhost/replica:0/task:0/gpu:2 Const: /job:localhost/replica:0/task:0/gpu:2 I tensorflow/core/common_runtime/simple_placer.cc:289] Const: /job:localhost/replica:0/task:0/gpu:2 MatMul: /job:localhost/replica:0/task:0/gpu:2 I tensorflow/core/common_runtime/simple_placer.cc:289] MatMul: /job:localhost/replica:0/task:0/gpu:2 AddN: /job:localhost/replica:0/task:0/cpu:0 I tensorflow/core/common_runtime/simple_placer.cc:289] AddN: /job:localhost/replica:0/task:0/cpu:0 [[44.56.] [98.128.]] ...
GPU 코드 예제
이 장을 총 정리하기 위해 DamienAymeric이 깃허브에 올린 코드를 기반으로 예제를 만들었습니다. 이 코드는 n=10 인 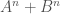
먼저 필요한 라이브러리를 로드합니다.
import numpy as np import tensorflow as tf import datetime
numpy 패키지를 사용해 임의의 값으로 두개의 행렬을 만듭니다.
A = np.random.rand(1e4, 1e4).astype('float32')
B = np.random.rand(1e4, 1e4).astype('float32')
n = 10
그런 다음 결과를 저장할 리스트 두개를 만듭니다.
c1 = [] c2 = []
다음엔 아래와 같이 matpow() 함수를 정의합니다.
def matpow(M, n): if n < 1: #Abstract cases where n < 1 return M else: return tf.matmul(M, matpow(M, n-1))
이전에 했던 것 처럼 하나의 GPU에서 코드를 실행하려면 아래와 같이 GPU를 지정합니다.
with tf.device('/gpu:0'):
a = tf.constant(A)
b = tf.constant(B)
c1.append(matpow(a, n))
c1.append(matpow(b, n))
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
t1_1 = datetime.datetime.now()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess:
sess.run(sum)
t2_1 = datetime.datetime.now()
2개의 GPU를 사용하는 경우 코드는 아래와 같습니다.
with tf.device('/gpu:0'):
#compute A^n and store result in c2
a = tf.constant(A)
c2.append(matpow(a, n))
with tf.device('/gpu:1'):
#compute B^n and store result in c2
b = tf.constant(B)
c2.append(matpow(b, n))
with tf.device('/cpu:0'):
sum = tf.add_n(c2) #Addition of all elements in c2, i.e. A^n + B^n
t1_2 = datetime.datetime.now()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess:
# Runs the op.
sess.run(sum)
t2_2 = datetime.datetime.now()
마지막으로 연산에 걸린 시간을 출력합니다.
print "Single GPU computation time: " + str(t2_1-t1_1) print "Multi GPU computation time: " + str(t2_2-t1_2)
분산 버전 텐서플로우
이장의 서두에 이야기한 것처럼 2016년 2월 구글은 프로세스간 통신을 위한 고성능 오픈소스 RPC 프레임워크인 gRPC를 사용한(텐서플로우 서빙도 같은 프로토콜을 씁니다) 텐서플로우의 분산버전을 릴리즈하였습니다.
이 패키지는 아직까지 소스로만 제공되기 때문에 이를 사용하기 위해서는 바이너리를 빌드해야만 합니다.(역주: 4월에 정식 릴리즈가 되어 바이너리로 제공이 됩니다) 이 책은 입문서라 분산버전에 대해서는 설명하지 않습니다. 하지만 이에 대해 알고 싶은 독자는 텐서플로우의 분산버전을 위한 공식 페이지를 참고하면 좋습니다.
이전 장에서와 같이 여기에서 사용된 코드는 이 책의 깃허브에서 확인할 수 있습니다. GPU를 사용하여 어떻게 속도를 높일 수 있는지 이해하는데 이 장의 내용이 충분했기를 바랍니다.

마지막에 연산에 걸린 시간 print 아웃풋은 어떻게 되나요? 얼마나 빨라졌는지 예시를 보고 싶은데 가장 중요한 부분이 빠진 느낌이네요!
좋아요좋아요
https://github.com/jorditorresBCN/LibroTensorFlow/blob/master/multiGPU.py 원서 코드의 주석을 참고하세요. 🙂
좋아요좋아요