
★★★★★ 검증된 내용, 훌륭한 번역자, 그리고 좋은 편집(hawkm*** 님)
★★★★ 개정판은 인기없는 책은 나올 이유가 없다(ghcjs*** 님)
♥♥♥♥ 올 컬러로 깔끔한 해설(bi**cle2 님)
송진영 님이 블로그에 올리신 이 책의 서평도 참고하세요!
‘[개정판] 파이썬 라이브러리를 활용한 머신러닝’은 scikit-learn의 코어 개발자이자 배포 관리자인 안드레아스 뮐러Andreas Mueller와 매쉬어블의 데이터 과학자인 세라 가이도Sarah Guido가 쓴 ‘Introduction to Machine Learning with Python‘ 번역서입니다.
사이킷런의 최신 버전에 맞추어 저자들이 새롭게 릴리스한 4판을 기준으로 개정판이 출간되었습니다. 주요한 변경 사항은 다음과 같습니다.
- OneHotEncoder와 ColumnTransformer, make_column_transformer
- KBinsDiscretizer
- cross_validate
- Pipeline 캐싱
- 그외 사이킷런 0.19, 0.20에서 추가, 변경된 내용 반영
- (한국어판 부록) 배깅, 엑스트라 트리, 에이다부스트
- (한국어판 부록) QuantileTransformer와 PowerTransformer
- (한국어판 부록) 반복 교차 검증
특별히 개정판에서는 그래프를 손쉽게 구분할 수 있도록 풀 컬러 인쇄를 하였습니다! 흔쾌히 컬러 인쇄를 결정해 주신 한빛미디어 출판사에 감사드립니다.
- 온라인/오프라인 서점에서 판매중입니다. [YES24], [교보문고], [한빛미디어]
- 480 페이지, 종이책:
32,000원—>28,800원, 전자책 25,600원 - 이 책에 실린 코드는 깃허브에서 주피터 노트북으로 볼 수 있습니다. [github], [nbviewer]
- 이 책의 코드는 scikit-learn 0.20.2, 0.21.1, 0.22, 0.23.1, 0.24, 1.0 버전에서 테스트 되었습니다.
- 저자 안드레아스 뮐러와의 인터뷰는 한빛미디어 홈페이지에서 볼 수 있습니다.
- 1판의 1장과 2장을 ‘파이썬 머신러닝‘ 페이지에서 읽을 수 있습니다.
- 교보문고 Dev READIT 2018에 선택되어 이 책에 대한 칼럼을 썼습니다.
이 페이지에서 책의 에러타와 scikit-learn 버전 변경에 따른 바뀐 점들을 계속 업데이트 하겠습니다.
이 책에 대해 궁금한 점이나 오류가 있으면 이 페이지 맨 아래 ‘Your Inputs’에 자유롭게 글을 써 주세요. 또 제 이메일을 통해서 알려 주셔도 되고 구글 그룹스 파이썬 머신러닝 Q&A에 글을 올려 주셔도 좋습니다.
적바림(미처 책에 넣지 못한 내용을 추가하고 있습니다)
- 자주하는 질문
- SVM의 목적함수를 풀기 위해 어떤 알고리즘을 사용하나요?
- 그래디언트부스팅의 predict_proba() 메서드에서 어떻게 확률을 계산하나요?
- 결정 트리에서 특성 중요도(feature_importances_)는 어떻게 계산하나요?
- mglearn 라이브러리를 어떻게 설치하나요?
- 우분투 리눅스에서 konlpy 설치하기
- mglearn을 임포트할 때
cannot import name 'imread' 에러가 납니다.
- p116에 언급된 랜덤 포레스트에서 어떤 데이터 포인트가 부트스트랩 샘플에 포함되지 않을 확률
- p152에 언급된 네스테로프 모멘텀에 대한 자세한 설명
- p443에 언급된 넷플릭스 데이터셋의 다운로드 링크
- p286에 언급된 F-값의 유도식
- MLPClassifier을 사용한 다중 레이블 분류
감사합니다! 🙂
Outputs (aka. errata)
- ~29: 2쇄에 반영되었습니다.
- ~31: 3쇄에 반영되었습니다.
- ~43: 4쇄에 반영되었습니다.
- ~82: 5쇄에 반영되었습니다.
- ~87: 6쇄에 반영되었습니다.
- (p104) 그림 2-24와 2-25가 잘못 되었습니다. 다음 그림으로 바꾸어야 합니다.(현*웅 님)
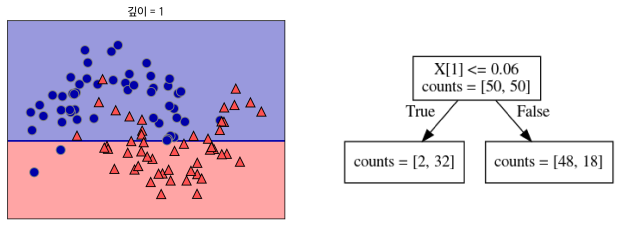
그림 2-24
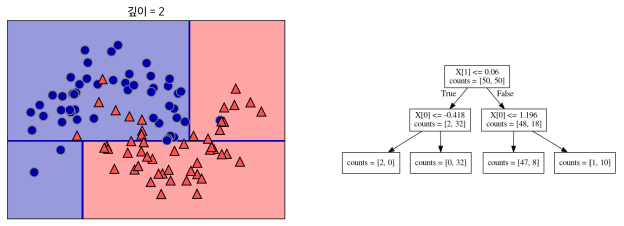
그림 2-25
- (p124) 아래에서 두 번째 줄의 주석 번호를 48에서 51로 바꿉니다.(현*웅 님)
- (p36) Note 박스의 첫 번째 줄 끝에서 ‘네 라이브러리’를 ‘다섯 라이브러리’로 정정합니다.(현*웅 님)
- (p156) 마지막 줄 끝의 주석 번호를 64에서 68로 바꿉니다.(현*웅 님)
- (p161) NOTE 박스 끝의 주석 번호를 78에서 79로 바꿉니다.(현*웅 님)
- (p345) CAUTION 박스 끝의 주석 번호를 11에서 12로 바꿉니다.(현*웅 님)
- (p375) 마지막 줄의 주석 번호를 33에서 34로 바꿉니다.(현*웅 님)
- (p425) 페이지 중간에 있는 주석 번호를 12에서 14로 바꿉니다.(현*웅 님)
- (p447) 마지막 줄에 “컴퓨터에 장착된 CPU 코어를 최대한 활용하기 위해 n_jobs=-1로 지정했습니다”를 “Mecab은 Pickle 오류가 발생하기 때문에 n_jobs=1로 지정했습니다”로 정정합니다.(현*웅 님)
- (p108) 주석 40에서 “graphviz 모듈은 pip install graphviz 명령으로”를 “graphviz 모듈은 conda install graphviz 또는 pip install graphviz 명령으로”로 수정합니다.(현*웅 님)
- (p281) Out [12]의 출력을 다음과 같이 변경합니다.
[[1. 0. 0. 0. 1. 0.] [0. 1. 0. 0. 0. 1.] [0. 0. 1. 0. 1. 0.] [0. 1. 0. 1. 0. 0.]]
- (p71) 주석 6번의
공식에서 두 번째 항의 분자가
이 아니고
입니다.(서* 님)
- (p86) 주석 20번의 두 번째 줄에서 “로직스틱 회귀”를 “로지스틱”로 정정합니다.(서* 님)
- (p103~104) 103 페이지 마지막 문단과 104 페이지 첫 문단에서 0.0596을 0.06으로 정정합니다.(서* 님)
- (p157) In[104]의 두 번째 print 함수에서 “훈련 세트 정확도”를 “테스트 세트 정확도”로 정정합니다.(서* 님)
- (p291) 첫 번째 줄에서 “학습된 기울기는 음수이고”를 “학습된 기울기는 양수이고”로 정정합니다.(서* 님)
- (p295) 마지막 줄에서 “아무런 변환도 거치치 않은”을 “아무런 변환도 거치지 않은”으로 정정합니다.(서* 님)
- (p303) 주석 24번에서 “정보 누설에 대한 자세한 내용은 376쪽”을 “정보 누설에 대한 자세한 내용은 398쪽”으로 정정합니다.(서* 님)
- (p123) Out[75]의 두 번째 줄에서 “훈련 세트 정확도”를 “테스트 세트 정확도”로 정정합니다.
- (p328) 주석 3번에서 “cross_val_predct(logreg, iris.data, iris.target, cv=5)”를 “cross_val_predict(logreg, iris.data, iris.target, cv=5)”로 정정합니다.(서* 님)
- (p344) 페이지 중간에 “In[22] 코드의 결과와 대등합니다”를 “In[24] 코드의 결과와 대등합니다”로 정정합니다.(서* 님)
- (p368) 맨 위 세 번째 줄에서 “
-점수가 0.14이지만, … ‘9아님’ 클래스는 각각 0.90과 0.99라서”를 “
- (p371) 첫 번째 문단 마지막에 제시된 “https://goo.gl/RaDS8Z“를 “https://bit.ly/2IfMILV“로 바꿉니다.(서* 님)
- (p387) In[75]와 In[76] 코드에서 “roc_auc_score(y_test, grid.decision_function(X_test))”를 “average_precision_score(y_test, grid.decision_function(X_test))”로 정정합니다. In[76] 코드에서 GridSearchCV의 scoring 매개변수 값을 “roc_auc”에서 “average_precision“으로 정정합니다. 또한 Out[76]에서 “테스트 세트 AUC: 1.000“을 “테스트 세트 평균 정밀도: 0.996“으로, “테스트 세트 정확도: 1.000“을 “테스트 세트 정확도: 0.890“으로 정정합니다.(서* 님)
- (p397, p399) 397페이지 첫 번째 문단과 399페이지 주석 7번에서 “검증 폴더“를 “검증 폴드“로 정정합니다.(서* 님)
- (p427) 주석 15번에서 “Out[22]의 출력 결과가”를 “Out[23]의 출력 결과가”로 정정합니다.(서* 님)
- (p444) 첫 번째 문단 마지막 부분에서 “keep_default_na=True로 지정하여”를 “keep_default_na=False로 지정하여”로 정정합니다.(서* 님)
- (p441) In[45] 코드를 다음과 같이 수정합니다.
# 요구사항: spacy에서 표제어 추출 기능과 CountVectorizer의 토큰 분할기를 사용합니다. # spacy의 언어 모델을 로드합니다 en_nlp = spacy.load('en', disable=['parser', 'ner']) # spacy 문서 처리 파이프라인을 사용해 자작 토큰 분할기를 만듭니다 # (우리만의 토큰 분할기를 사용합니다) def custom_tokenizer(document): doc_spacy = en_nlp(document) return [token.lemma_ for token in doc_spacy] # 자작 토큰 분할기를 사용해 CountVectorizer 객체를 만듭니다 lemma_vect = CountVectorizer(tokenizer=custom_tokenizer, min_df=5) - (p366, 367, 369, 370, 384) 사이킷런 0.21 버전에서 classification_report 함수의 labels 매개변수가 지정되지 않거나 labels 매개변수로 전달된 클래스 레이블이 타깃값에 모두 포함되어 있다면 micro avg 대신에 같은 의미인 accuracy가 출력됩니다. 따라서 classification_report 함수 출력에서 “micro avg aa, bb, cc, dd“를 “accuracy cc, dd“로 바꾸어 주세요.
- (p30)
scipy.misc.imread함수가 scipy 1.3.0 버전에서 삭제되었습니다. 대신imageio.imread함수를 사용하기 위해imageio를 설치해야 합니다.pip명령 맨 뒤에imageio를 추가해 주세요.$ pip install numpy scipy matplotlib ipython scikit-learn pandas pillow imageio - (p92) 사이킷런 0.22버전부터
LogisticRegression클래스의solver의 기본값이lbfgs로 바뀌었습니다. 이 알고리즘은 L1 규제를 지원하지 않기 때문에LogisticRegression클래스에 L1 규제를 적용하려면 다른solver를 지정해야 합니다. 따라서 In[47] 코드에서LogisticRegression클래스 매개변수에solver='liblinear'를 추가합니다. - 모델을 훈련할 때 반복 횟수를 늘리라는 경고가 출력되는 것을 막기 위해
max_iter매개변수 값을 늘립니다.- p87의 In[41], p137의 In[80]:
LinearSVC에max_iter=5000매개변수 추가 - p135의 In[78]:
LinearSVC에max_iter=5000, tol=1e-3매개변수 추가 - p89의 In[43], p90의 In[44]와 In[45], p306의 In[51], p308의 In[55], p310의 In[57], p424의 In[18], p426의 In[22], p428의 In[25], p430의 In[29], p436의 In[39], p442의 In[47]:
LogisticRegression에max_iter=5000매개변수 추가 - p92의 In[47], p278의 In[8], p284의 In[17], p325의 In[5], p336의 In[2], p360의 In[46], p404의 In[23], p424의 In[17]:
LogisticRegression에max_iter=1000매개변수 추가 - p151의 In[95], p152의 In[97], p153의 In[98]:
MLPClassifier에max_iter=1000매개변수 추가 - p215의 In[38], p218의 In[42], p234의 In[59]:
NMF에max_iter=1000, tol=1e-2매개변수 추가
- p87의 In[41], p137의 In[80]:
- 사이키런 0.21 버전에서 사분위수보다 샘플 개수가 작을 때 적절히 처리하지 못하는 버그가 수정되었습니다. 샘플 개수가 1,000개보다 작을 때 경고 메시지를 출력하지 않기 위해
QuantileTransformer클래스에n_quantiles매개변수를 지정합니다.- p183의 In[4], p185의 In[9], p186의 In[10]:
QuantileTransformer에n_quantiles=50매개변수 추가 - p185의 In[8]:
QuantileTransformer에n_quantiles=5매개변수 추가
- p183의 In[4], p185의 In[9], p186의 In[10]:
- (p360) 사이킷런 0.24 버전에서
DummyClassifier의strategy매개변수 기본값이stratified에서prior로 변경된다는 경고를 피하기 위해strategy='stratified'매개변수를 추가합니다. - (p388)
metrics.scorer모듈이 사이킷런 0.24 버전에서 삭제됩니다. 맨 위 첫 줄의 “metrics.scorer모듈의 SCORERS 딕셔너리를 봐도 됩니다” 문장과 In[77], Out[77]을 삭제합니다. - (p41) In[15] 바로 위 문장 끝에 다음 주석을 추가합니다. “옮긴이_ 사이킷런 0.23 버전부터
dataset모듈의 함수에서as_frame=True와 같이 지정하면 데이터프레임으로 반환됩니다.” - (p108) 41번 주석을 다음과 같이 변경합니다.
옮긴이_ graphviz 모듈은conda install graphviz또는pip install graphviz명령으로 설치할 수 있습니다. 주피터 노트북이 아닐 경우graphviz.Source의 결과를 변수로 저장하여 pdf, png 등의 파일로 저장할 수 있습니다.dot=graphviz.Source(dot_graph) dot.format='png' dot.render(filename='tree.png')
사이킷런 0.21 버전에서 추가된 plot_tree() 함수를 사용하면 .dot 파일을 만들지 않고 바로 트리를 그릴 수 있습니다. 이 함수는
export_graphviz()함수에서 사용한class_names,feature_names,impurity,filled매개변수를 모두 지원합니다. - (p125) 주석 52번을 다음과 같이 변경합니다. “옮긴이_ xgboost(https://xgboost.readthedocs.io/)는 대용량 분산 처리를 위한 그레이디언트 부스팅 오픈 소스 라이브러리로 C++, 파이썬, R, 자바 등 여러 인터페이스를 지원합니다. 히스토그램 기반 부스팅 알고리즘을 사용하는 또 다른 인기 라이브러리는 마이크로소프트에서 만든 LightGBM(https://lightgbm.readthedocs.io/)입니다. 사이킷런 0.21 버전에서도 이와 비슷한
HistGradientBoostingClassifier와HistGradientBoostingRegressor클래스가 추가되었습니다.” - (p193) Out[13] 바로 아래 첫 번째 문장 끝에 다음 주석을 추가합니다. “옮긴이_ 중요한 전처리 작업 중 하나는 누락된 값의 처리입니다. 사이킷런에서는 특성의 평균이나 최빈값으로 대체하는
SimpleImputer클래스(0.20 버전에서 추가)와 최근접 이웃 방식으로 대체하는KNNImputer클래스(0.22 버전에서 추가) 등을 제공합니다.” - (p372) 첫 번째 문장 끝에 다음 주석을 추가합니다.
옮긴이_ 사이킷런 0.22 버전에서 정밀도-재현율 곡선을 그려주는 함수가 추가되었습니다. 예를 들어 다음 코드는 In [61]에 있는 svc 추정기를 사용해 [그림 5-13]과 유사한 그래프를 그립니다.from sklearn.metrics import plot_precision_recall_curve plot_precision_recall_curve(svc, X_test, y_test) plt.show()
- (p377) 첫 번째 문장 끝에 다음 주석을 추가합니다.
옮긴이_ 사이킷런 0.22 버전에서 ROC 곡선을 그려주는 함수가 추가되었습니다. 예를 들면 다음과 같이 사용합니다.from sklearn.metrics import plot_roc_curve plot_roc_curve(svc, X_test, y_test) plt.show()
- (p382) In[70] 바로 위 문장 끝에 다음 주석을 추가합니다.
옮긴이_ 사이킷런 0.22 버전에서 오차 행렬을 그래프로 그려주는 함수가 추가되었습니다. 예를 들면 다음과 같이 사용합니다.from sklearn.metrics import plot_confusion_matrix plot_confusion_matrix(lr, X_test, y_test) plt.show()
- (p401) 11번 주석 끝에 다음 내용을 추가합니다.
사이킷런 0.23 버전에서는 추정기 객체를 주피터 노트북에서 시각화해주는 기능이 추가되었습니다. 특히 이 기능은 파이프라인 구조를 잘 요약해주기 때문에 유용합니다. 예를 들어 다음 코드는 [그림 6-3]의 pipe 객체의 구조를 출력합니다.from sklearn import set_config set_config(display='diagram') pipe
- (4쇄 p108) 주석 41에서
dot=graphviz.Source(dot_graph); dot.format='png'; dot.render(filename='tree.png').라인을 삭제합니다. - (p346) 주석 14번에 “Out[32]에서는”을 “Out[34]에서는”으로 정정합니다.(정*균 님)
- (p378) 코드 블럭 아래에서 3번째 줄에
tpr[close_default_rf]를tpr_rf[close_default_rf]로 정정합니다.(정*균 님) - (p29) Enthought Canopy 항목을 다음으로 교체합니다.
ActivePython (https://www.activestate.com/products/python/)
또 다른 범용 파이썬 배포판입니다. NumPy, SciPy, matplotlib, pandas, Jupyter, scikit-learn을 포함하고 있습니다. 무료로 사용할 수 있는 Community Edition과 기업을 위한 유료 버전도 있습니다. ActivePython은 파이썬 2.7, 3.5, 3.6을 지원하며 macOS, 윈도우, 리눅스에서 사용할 수 있습니다. - (p34) 위에서 3번째 줄 “%matplotlib inline을 사용합니다” 뒤에 주석을 추가합니다. <주석>옮긴이_ IPython kernel 4.4.0부터는 %matplotlib inline 매직 명령을 사용하지 않더라도 맷플롯립 1.5 이상에서는 주피터 노트북에 바로 이미지가 출력됩니다.</주석>
- (p36) <노트>의 마지막 줄 “만약 이런 매직 커맨드를 사용하지 않는다면 이미지를 그리기 위해 plt.show 명령을 사용해야 합니다”를 “또는 IPython kernel 4.4.0과 맷플롯립 1.5 버전 이상을 사용한다고 가정합니다.”로 수정합니다.
- (p37) 1.6절 바로 위 문장 끝에서 “파이썬 3.7로 업그레이드하세요”를 “파이썬 3.7 이상으로 업그레이드하세요”로 수정합니다.
- (p38) 주석에 포함된 블로그 링크 goo.gl/FYjbK3 을 bit.ly/2K73mA4 로 수정합니다.
- (p65) In [14] 코드 블럭 위 문장 끝 “이웃의 수를 3으로 지정합니다”에 주석을 추가합니다. <주석>옮긴이_
KNeighborsClassifier클래스의n_neighbors매개변수 기본값은 5입니다.</주석> - (p87) 22번 주석에서 “LogisticRegression의 solver 매개변수를 지정하지 않으면 scikit-learn 0.22 버전부터 기본값 이 liblinear에서 lbfgs로 변경된다는 경고 메세지가 출력됩니다.”를 삭제합니다. 23번 주석에서 “liblinear를 사용하는 LogisticRegression 과 LinearSVC는”를 “LogisticRegression 과 LinearSVC는”로 수정합니다.
- (p94) 28번 주석에서 마지막 문장 “multi_class 매개변수를 지정하지 않으면 0.22 버전부터 기본값이 ovr에서 auto로 변경된다는 경고가 출력됩니다“를 “0.22 버전부터는 multi_class의 기본값이 ‘ovr’에서 ‘auto’로 바뀌었습니다“로 수정합니다.
- (p106) 페이지 중간에서 “scikit-learn은 사전 가지치기만 지원합니다” 끝에 주석을 추가합니다. <주석>옮긴이_ 사이킷런 0.22 버전에서 비용 복잡도 기반의 사후 가지치기를 위한 ccp_alpha 매개변수가 추가되었습니다.</주석>
- (p113) In [67] 코드 블럭에서
X_train = data_train.date[:, np.newaxis]를X_train = data_train.date.to_numpy()[:, np.newaxis]로 수정하고X_all = ram_prices.date[:, np.newaxis]를X_all = ram_prices.date.to_numpy()[:, np.newaxis]로 수정합니다. - (p115) 42번 주석 끝에서 “0.25 버전에서는 삭제됩니다”를 “1.0 버전에서는 삭제됩니다”로 수정합니다.
- (p116) 44번 주석 “옮긴이_ n_estimators 매개변수의 기본값은 10입니다. n_estimators 매개변수를 지정하지 않으면 scikit-learn 0.22 버전부터 기 본값이 100으로 바뀐다는 경고가 출력됩니다”를 “scikit-learn 0.22 버전부터 n_estimators의 기본값이 10에서 100으로 바뀌었습니다.”로 수정합니다.
- (p142) Out [84] 에서 “훈련 세트 정확도: 1.00“을 “훈련 세트 정확도: 0.90“으로 수정하고 “테스트 세트 정확도: 0.63“을 “테스트 세트 정확도: 0.94“로 수정합니다. 그 아래 문장에서 “훈련 세트에는 완벽한 점수를 냈지만 테스트 세트에는 63% 정확도라서 이 모델은 상당히 과대적합되었습니다”를 “훈련 세트에는 90% 정확도를 냈지만 테스트 세트에는 94% 정확도라서 이 모델은 상당히 과소적합되었습니다”로 수정합니다.
- (p144) Out [88]에서 “훈련 세트 정확도: 0.948 테스트 세트 정확도: 0.951“를 “훈련 세트 정확도: 0.984 테스트 세트 정확도: 0.972“로 수정합니다. 그 아래 문단에서 “훈련 세트와 테스트 세트의 정확도가 100%에서는 조금 멀어졌지만 매우 비슷해서 확실히 과소적합된 상태입니다“를 “훈련 세트와 테스트 세트의 정확도가 모두 상승하여 과소적합이 많이 해소되었습니다“로 수정합니다. In [89] 코드 블럭에서
svc = SVC(C=1000)을svc = SVC(C=20)으로 수정합니다. - (p145) Out [89]에서 “테스트 세트 정확도: 0.972“를 “테스트 세트 정확도: 0.979“로 수정합니다. 그 아래 문장에서 “C 값을 증가시켰더니 모델의 성능이 97.2%로 향상되었습니다”를 “C 값을 증가시켰더니 모델의 성능이 97.9%로 향상되었습니다”로 수정합니다.
- (p152) In [96] 코드에서
mlp = MLPClassifier(solver='lbfgs', random_state=0, hidden_layer_size=[10, 10])를mlp = MLPClassifier(solver='lbfgs', random_state=0, hidden_layer_size=[10, 10], max_iter=1000)로 수정합니다. - (p159) 75번 주석에서 “『핸즈온 머신러닝』 (한빛미디어, 2018)”을 “『핸즈온 머신러닝 2판』 (한빛미디어, 2020)”로 수정합니다.
- (p170) In [122] 코드에서
logreg=LogisticRegression()을logreg=LogisticRegression(max_iter=1000)로 수정합니다. - (p191) In [11] 코드에서
svm = SVC(C=100)을svm = SVC(gamma='auto')로 수정합니다. - (p213) 주석 25번을 “NMF에서 초기화 방식을 지정하는 init 매개변수의 기본값은 None으로 n_components가 샘플이나 특성 개수보다 작으면 ‘nndsvd’를 사용하고 그렇지 않으면 ‘random’을 사용합니다. ‘nndsvd’는 특잇값 분해로 얻은 U와 V 행렬의 절댓값에 S 행렬의 제곱근을 곱해 W와 H 행렬을 만듭니다. 그다음 W와 H 행렬에서 1e-6 보다 작은 값은 0으로 만듭니다. ‘nndsvda’는 0을 입력 행렬의 평균값으로 바꿉니다. scikit-learn 1.1 버전부터는 ‘nndsvd’에서 ‘nndsvda’로 기본값이 바뀝니다. ‘random’은 데이터 평균을 성분의 개수로 나눈 후 제곱근을 구하고, 그런 다음 정규분포의 난수를 발생시켜 앞에서 구한 제곱근을 곱하여 H와 W 행렬을 만듭니다. 이는 데이터 평균값을 각 성분과 두 개의 행렬에 나누어 놓는 효과를 냅니다.”로 바꿉니다.
- (p214) In [37] 코드에서
mglearn.plots.plot_nmf_faces(X_train, X_test, image_shape)을mglearn.plots.plot_nmf_faces(X_train, X_test[:3], image_shape)로 수정합니다. - (p215) In [38] 코드에서
nmf = NMF(n_components=15, random_state=0, max_iter=1000, tol=1e-2)를nmf = NMF(n_components=15, init='nndsvd', random_state=0, max_iter=1000, tol=1e-2)로 수정합니다. - (p218) In [42] 코드에서 nmf = NMF(n_components=3, random_state=42, max_iter=1000, tol=1e-2)를 nmf = NMF(n_components=3, init=’nndsvd’, random_state=42, max_iter=1000, tol=1e-2)로 수정합니다.
- (p234) In [50] 코드에서 nmf = NMF(n_components=100, random_state=0, max_iter=1000, tol=1e-2)를 nmf = NMF(n_components=100, init=’nndsvd’, random_state=0, max_iter=1000, tol=1e-2)로 수정합니다.
- (p238) 주석 35 끝에 다음 문장을 추가합니다. “scikit-learn 0.23 버전부터 KMeans 클래스는 OpenMP 기반의 병렬화를 제공합니다. 이 때문에 n_jobs 매개변수를 사용하면 경고가 발생하며 이 매개변수는 1.0 버전에서 삭제될 예정입니다.”
- (p284) 주석 10번에서 다음 문장을 삭제합니다. “0.20.1 버전 이상에서 (열_리스트, 변환기_객체) 로 전달하면 이와 관련된 경고가 발생하며 0.22 버전에서는 (열_리스트, 변환기_객체) 형식이 삭제될 예정입니다.”
- (p309) 주석 31번을 삭제하고 4.7.3절 아래 4번째 줄 “도달할 때까지 하나씩 추가하는 방법입니다.” 끝에 다음 주석을 추가합니다. <주석>옮긴이_ 이를 전진 선택법(foward stepwise selection)과 후진 선택법(backward stepwise selection)이라고도 부릅니다. scikit-learn 0.24 버전에서 추가된 SequentialFeatureSelector 클래스는 scoring 매개변수에 지정된 측정 지표의 교차 검증 점수를 기준으로 특성을 하나씩 추가하거나 제거합니다. scoring 매개변수의 기본값은 회귀일 경우에는
- (p318) 주석 39번에서 다음 문장을 삭제합니다. “0.20 버전부터 정수형 데이터를 변환할 때 이와 관련된 경고가 출력됩니다.”
- (p325) Out [5]의 출력을 “[0.967 1. 0.933 0.967 1. ]”로 바꿉니다. 아래에서 3번째 줄에 “여기에서는 cross_val_score가 3-겹 교차 검증을 수행했기 때문에 3개의 점수가 반환되었습니다. 현재 scikit-learn의 기본값은 3-겹 교차 검증이이지만 scikit-learn 0.22 버전부터는 5-겹 교차 검증으로 바뀔 것입니다”를 “여기에서는 cross_val_score가 5-겹 교차 검증을 수행했기 때문에 5개의 점수가 반환되었습니다. scikit-learn 0.22 버전부터 3-겹 교차 검증에서 5-겹 교차 검증으로 바뀌었습니다“로 수정합니다.
- (p326) In [6] 코드에서 scores = cross_val_score(logreg, iris.data, iris.target, cv=5)를 scores = cross_val_score(logreg, iris.data, iris.target, cv=10)로 수정합니다. Out [6]의 출력을 “교차 검증 점수: [1. 0.933 1. 1. 0.933 0.933 0.933 1. 1. 1. ]”로 바꿉니다. Out [7] 출력 아래 문장에서 “5-겹 교차 검증이 만든 다섯 개의 값을 모두 보면 100%에서 90%까지 폴드에 따라”를 “10-겹 교차 검증이 만든 다섯 개의 값을 모두 보면 100%에서 93%까지 폴드에 따라”로 수정합니다.
- (p346) 주석 14번을 삭제하고 주석 13번 끝에 다음 문장을 추가합니다. “사이킷런 0.24 버전에서는 SH(Successive Halving) 방식의 HalvingGridSearchCV가 추가되었습니다. 이 클래스는 모든 파라미터 조합에 대해 제한된 자원으로 그리드서치를 실행한 다음 가장 좋은 후보를 골라서 더 많은 자원을 투여하는 식으로 반복적으로 탐색을 수행합니다.”
- (p440, p441) In [43], In [45] 코드에서
spacy.load('en'을spacy.load('en_core_web_sm'으로 수정합니다. - (p458) 주석 35에서 “『텐서플로 첫걸음』(한빛미디어, 2016)”를 “『혼자 공부하는 머신러닝+딥러닝』(한빛미디어, 2020)”로 수정합니다.
- (p463) 위에서 2번째 줄에 “goo.gl/fkQWsN”을 “bit.ly/3c7ylYV”로 수정합니다.
- (p467) 주석 9번에서 “『핸즈온 머신러닝』 (한빛미디어, 2018)”를 “『핸즈온 머신러닝 2판』 (한빛미디어, 2020)”로 수정합니다.
- (p468) 위에서 2번째 줄에 “goo.gl/lQmL1X”을 “bit.ly/3qnikDx”로 수정합니다.
- (p156) (5쇄) 마지막 줄 끝의 주석 번호를 68에서 71로 정정합니다.
- (p161) (5쇄) <노트>의 마지막 줄 끝의 주석 번호를 80에서 82로 정정합니다.
- (p166) 2번째 문단 끝에 주석을 추가합니다. “옮긴이_ 보정 곡선은 사이킷런의 `calibration_curve()` 함수(https://bit.ly/3yoVG25)로 그릴 수 있습니다. 자세한 사용법은 온라인 문서(https://bit.ly/3Am4rvu)를 참고하세요.”
- (p306) In[51] 코드 4번째 줄에서
lr = LogisticRegression(max_iter=1000)을lr=LogisticRegression(max_iter=5000)으로 수정합니다. - (p334) In [19] 코드 7번째 줄에서
groups를groups=groups로 수정합니다. - (p62) 위에서 3번째 줄에 다음처럼 주석을 추가합니다. “보스턴 주택가격 데이터셋<주석>옮긴이_ 보스턴 주택가격 데이터셋의 특성에는 흑인 인구 비율이 들어 있어 요즘 시대에 적절치 않다는 의견이 많았습니다. 사이킷런 1.0 버전에서
load_boston()함수가 deprecated 되었고 1.2 버전에서 삭제될 예정입니다.</주석>을 사용하겠습니다” - (p136, 137) In [79], [80]에서 Axes3D가 자동으로 그림에 추가되는 방식은 matplotlib 3.4 버전에서 deprecated 되었기 때문에 관련 경고를 피하기 위해
ax = Axes3D(figure, elev=-152, azim=-26)을ax = Axes3D(figure, elev=-152, azim=-26, auto_add_to_figure=False); figure.add_axes(ax)로 수정합니다. - (p156) In [102]에서 다음처럼
MLPClassifier객체 생성시max_iter매개변수를 지정합니다.mlp = MLPClassifier(max_iter=1000, random_state=0) - (p205) In [26]의 첫 번째 줄에서
np.bool이 1.20버전부터 deprecated 되었기 때문에 대신bool을 사용합니다.mask = np.zeros(people.target.shape, dtype=bool) - (p223) 4번째 줄에 다음과 같이 주석을 추가합니다. “결과를 비교해 보겠습니다.<주석>옮긴이_ 사이킷런 1.2 버전에서
TSNE클래스의init매개변수의 기본값이'random'에서'pca'로 바뀔 예정입니다.</주석> t-SNE는 새 데이터를..” get_feature_names()메서드를 가진 변환기에get_feature_names_out()메서드가 추가되었고get_feature_names()는 deprecated 되어 1.2 버전에서 삭제될 예정입니다. 따라서 (p281) 마지막 문장과 In [13], (p294) 첫 번째 문장과 In [34], (p297) 마지막 문장과 In[39], (p320) 첫 번째 문장과 In [72], (p423) In [16], (p426) In [21], (p430) In [30], (p434) In [35]와 In [36], (p435) In [38], (p437) In [41], (p450) In [51], (p451) In [55]에서get_feature_names()를get_feature_names_out()으로 수정합니다.- (p366) In [52]에서 0 나눗셈 경고를 피하기 위해 다음처럼
zero_division매개변수를 지정합니다.classification_report(y_test, pred_most_frequent, target_names=["9 아님", "9"], zero_division=0)) - (p443) 아래에서 4번째 줄에 다음처럼 주석을 추가합니다. “설치 페이지(…)를 참고하세요.<주석>옮긴이_ 최신 버전의
tweepy패키지를 설치할 경우konlpy에서StreamListener가 없다는 에러가 발생하므로 3.10버전을 설치해 주세요.pip install tweepy==3.10</주석> KoNLPy는 5개의…” - (p335) 주석 7번 끝에 다음을 추가합니다. “사이킷런 1.0 버전에서 그룹을 유지하면서 클래스 비율에 맞게 분할하는
StratifiedGroupKFold가 추가되었습니다.” - (p293) 주석 15번 끝에 다음 문장을 추가합니다. “사이킷런 1.0 버전부터는
PolynomialFeatures클래스의degree매개변수에 변환할 최소 차수과 최대 차수를 튜플로 전달할 수 있습니다.”
