MIT 존 구탁(John Guttag) 교수의 “Introduction to Computation and Programming Using Python 3rd Edition” 책 번역을 드디어 완료했습니다. 이 책은 단순히 파이썬 문법만 다루지 않고 계산적 사고를 돕기 위해 파이썬으로 여러가지 흥미로운 알고리즘을 구현해 보고 머신러닝을 포함해 파이썬 과학 생태계의 여러 측면을 배울 수 있습니다. 다음은 각 장의 내용을 요약한 것입니다.
1장은 계산적 사고와 두 종류의 지식에 대해 설명하는 것으로 시작됩니다. 프로그램 고정식 컴퓨터와 프로그램 내장식 컴퓨터의 차이점을 언급하면서 간단한 프로그래밍 발전 역사를 엿봅니다. 끝으로 프로그래밍 언어의 기본 구조, 문법, 정적 시맨틱, 시맨틱에 대해 설명하면서 어떻게 좋은 프로그램을 만들 수 있는지, 다른 언어와 파이썬 간의 차이점은 무엇인지를 소개하는 것으로 마칩니다.
2장은 파이썬의 기본 요소를 소개합니다. 먼저 간단한 파이썬의 특징과 역사를 살펴보고 아나콘다와 스파이더 IDE를 설치하는 방법을 설명합니다. 그다음 파이썬의 객체와 기본 스칼라 타입에 대해 알아 보고 몇 가지 예를 셸 프롬프트로 실행해 봅니다. 이어서 변수에 대해 설명하고 변수에 객체를 재할당할 때 생기는 미묘한 문제를 설명합니다. 그다음 if 문을 사용한 분기 프로그래밍을 설명합니다. 이와 함께 파이썬 코드를 여러 줄로 나누어 작성하는 방법도 소개합니다. 다음으로 문자열과 인덱싱, 슬라이싱, f-문자열을 설명합니다. 파이썬에서 사용자에게 입력을 받는 방법을 설명하면서 유니코드 인코딩에 대한 소개도 하고 있습니다. 그다음은 반복문입니다. while 문과 for 루프를 사용해 반복이 필요한 문제를 처리하는 방법을 소개합니다. 자연스럽게 range 함수도 소개합니다. 마지막으로 2~1000 사이의 소수의 합을 출력하는 퀴즈로 마무리합니다.
3장은 2장에서 배운 if, for, while 문을 사용해 간단한 프로그램을 작성하는 방법을 배웁니다. 먼저 완전 열거(exhaustive enumeration) 방식으로 제곱근을 구합니다. 이 방식의 단점을 생각해 본 다음 이분 검색(bisection search)으로 제곱근의 근삿값을 찾는 프로그램을 작성합니다. 부동소수점 숫자가 컴퓨터에서 어떻게 표현되는지 알아 보고 float 타입의 변수를 비교 연산자에 사용했을 때 발생할 수 있는 문제를 생각해 봅니다. 이 과정에서 비트, 이진수, 유효 숫자, 정밀도 등에 대해 알게 됩니다. 마지막으로 보편적인 근사 알고리즘인 뉴턴 방법을 사용해 다항식의 근을 찾는 코드를 작성합니다.
4장은 코드의 재사용성을 높이기 위해 함수의 필요성을 언급하고 함수를 정의하고 사용하는 방법을 소개합니다. 3장에서 만들었던 제곱근을 구하는 코드를 함수로 다시 구현해 봅니다. 그다음 위치 인수와 키워드 인수, 가변 길이 인수에 대해 소개합니다. 종종 혼동이 되는 변수의 유효범위에 대해 자세히 설명합니다. 이를 위해 스택 프레임을 설명하고 예를 들어 스택의 생성 소멸 과정을 자세히 안내합니다. 그다음 함수의 사양(specification)에 대해 소개합니다. 특히 추상화를 대해 재미있는 비유로 설명합니다. 지금까지 만든 함수에 독스트링으로 사양을 작성해 봅니다. 그다음 하나의 함수를 여러 개로 쪼개어 보고 함수를 인수나 반환값으로 사용하는 방법을 배웁니다. 이 과정에서 람다 함수를 소개합니다. 마지막으로 객체의 메서드에 간단히 소개하고 마칩니다.
5장은 튜플, 리스트, 레인지, 딕셔너리를 소개합니다. 튜플과 문자열의 비슷한 점과 다른 점을 소개하고 함수 반환 값에 많이 사용하는 복수 할당을 알아 봅니다. 레인지와 반복 가능한 객체에 대해 알아 보고 range 함수를 for 문에 적용해 봅니다. 그다음은 부수 효과로 골치 아플 수 있지만 유용한 객체인 리스트입니다. 이 절에서 리스트 안의 객체와 변수 사이의 바인딩에 대해 조금 더 자세히 알아 봅니다. 이 과정에서 id 함수와 is 연산자를 배웁니다. 또한 매개변수 디폴트 값에 빈 리스트를 넣었을 때 발생할 수 있는 놀라운 일도 살펴 봅니다. 리스트를 복제하기 위해 슬라이싱하는 방법과 copy 모듈을 사용하는 방법을 배웁니다. copy.deepcopy가 생각만큼 deep하지 않다는 사실도 알 수 있습니다. 그다음 파이썬 프로그래머들이 즐겨 사용하는 리스트 내포를 소개합니다. 하지만 두 개 이상 중첩하면 골치 아픕니다. 마지막으로 리스트를 사용해 고차 함수(high-order function)을 구현해보고 내장 고차 함수인 map의 사용법을 배웁니다. 5장은 여기서 끝나지 않고 집합(set)에 대해 소개하고 딕셔너리로 넘어갑니다. 딕셔너리에서 자주 사용되는 메서드를 소개하고 딕셔너리 내포도 다룹니다. 마지막으로 딕셔너리를 사용해 책 암호(book cipher)를 구현하는 간단한 예제로 마무리합니다!
6장은 재귀와 전역변수를 다룹니다. 먼저 재귀 예제의 헬로 월드인 팩토리얼을 반복문을 사용해 만든 것과 재귀를 사용해 만든 것을 비교하여 봅니다. 그다음 피보나치 수열을 재귀를 사용해 만들어 봅니다(사실 피보나치 수열은 피보나치가 만든 것이 아니군요!). 재귀를 사용하지 않고 더 효율적으로 피보나치 수열을 만들 수도 있습니다(이건 번역서 깃허브에 담겨 있습니다). 숫자가 아닌 문제에도 재귀를 사용할 수 있습니다. 예를 들면 팰린드롬(palindrome)이죠. 팰린드롬을 구현하면서 분할 정복에 대해 살짝 소개합니다. 이에 대해서는 12장에서 다시 알아 봅니다. 마지막으로 전역 변수는 일반적으로 사용하지 않도록 권장하지만 꼭 필요한 경우가 있기 때문에 간략히 소개합니다.
계속 읽기


 은 훈련 데이터에 있는 특성의 수입니다.
은 훈련 데이터에 있는 특성의 수입니다. 를
를 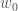 으로 바꾸어 하나의 벡터
으로 바꾸어 하나의 벡터  로 나타내겠습니다.
로 나타내겠습니다. 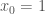 을 추가하여 벡터
을 추가하여 벡터  를 정의합니다. 이제 이 선형 방정식은
를 정의합니다. 이제 이 선형 방정식은
 은 훈련 샘플의 수입니다.
은 훈련 샘플의 수입니다.

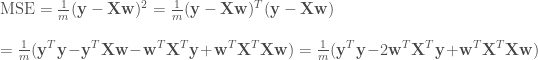
 은 미분 결과에 영향을 미치지 않으므로 제외하고
은 미분 결과에 영향을 미치지 않으므로 제외하고