선형 회귀
회귀는 연속적인 타깃을 예측하는 알고리즘입니다. 그 중에 선형 회귀Linear Regression가 가장 기본입니다. 선형 회귀는 훈련 데이터에 가장 잘 들어 맞는 선형 방정식

를 찾는 문제입니다. 여기에서 
편의상 
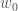

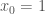


와 같이 간단히 쓸 수 있습니다. 훈련 샘플이 하나가 아니라 여러개이므로 벡터 

얼마나 잘 들어 맞는지를 측정 방법으로는 평균 제곱 오차Mean Square Error, MSE를 사용합니다.

이런 측정 함수를 비용 함수cost function이라고 부릅니다. 선형 회귀의 비용 함수인 평균 제곱 오차를 최소화하는 선형 방정식의
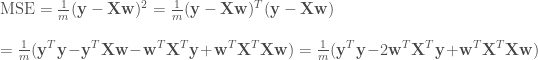


이 도함수가 0이 되는

샘플 데이터
사이킷런에 포함된 샘플 데이터 중 캘리포니아 주택 가격 데이터셋을 사용하겠습니다.
import sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housingfetch_california_housing()함수를 호출하여 사이킷런의 Bunch 클래스 객체를 얻습니다. 캘리포니아 주택가격 데이터셋은 전체 샘플 개수가 20,640개이고 8개의 특성을 가집니다.
housing = fetch_california_housing()
print(housing.data.shape, housing.target.shape)(20640, 8) (20640,)
train_test_split() 함수를 사용해서 75%는 훈련 세트로 25%는 테스트 세트로 분리합니다. 편의상 그래프로 나타내기 편하도록 하나의 특성만 사용하겠습니다. 사이킷런의 모델은 훈련 데이터가 2차원 배열일 것으로 예상합니다. 따라서 housing.data 에서 하나의 특성만 선택하더라도 2차원 배열이 되도록 넘파이 슬라이싱을 사용했습니다. 여기서는 첫 번째 특성만 사용합니다.
X_train, X_test, y_train, y_test = train_test_split(housing.data[:, 0:1],
housing.target, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)(15480, 1) (5160, 1) (15480,) (5160,)계속 읽기
