
2024년 첫 도서가 출간되었습니다! <실무로 통하는 ML 문제 해결 with 파이썬>은 2019년에 출간된 <파이썬 라이브러리를 활용한 머신러닝 쿡북>의 2판에 해당됩니다.
2판에서는 딥러닝 라이브러리로 파이토치를 사용하고 많은 내용이 보강되었습니다!
2024년 첫 도서가 출간되었습니다! <실무로 통하는 ML 문제 해결 with 파이썬>은 2019년에 출간된 <파이썬 라이브러리를 활용한 머신러닝 쿡북>의 2판에 해당됩니다.
2판에서는 딥러닝 라이브러리로 파이토치를 사용하고 많은 내용이 보강되었습니다!

전세계에서 가장 많이 팔린 머신러닝 도서인 <핸즈온 머신러닝 3판>이 출간되었습니다! 네 오늘은 <만들면서 배우는 생성 AI>와 함께 하루에 두 권이 출간되는 경험을 하네요! 🙂
핸즈온 머신러닝 1판이 2018년에 처음 나와서 정말 선풍적인 인기를 얻었습니다. 그리고 2020년에 2판, 2023년에 3판이 출간되었습니다. 원서의 인기가 번역서에 잘 이어지지 않는 도서도 꽤 많습니다. 하지만 <핸즈온 머신러닝>은 많은 분들의 도움으로 원서 못지 않은 인기를 얻고 있습니다.
3판은 자연어 처리(트랜스포머 + 허깅 페이스)와 생성 모델을 추가로 다루고 시계열 예제를 실전 데이터를 사용하도록 바꾸었습니다. 또한 사이킷런과 케라스의 최신 변경 사항을 알차게 담고 있습니다. 오렐리앙의 실감나는 설명은 여전하구요! 변경 사항에 대한 자세한 내용은 Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 3rd Edition 번역 완료!를 참고하세요.
3판에서 쪽수가 더 늘어나 천 페이지가 넘게 되었습니다. 독자들이 조금 더 편하게 책을 볼 수 있도록 두 권으로 쉽게 분권할 수 있도록 제본되었습니다. 어느 책상, 어느 책장에서도 가장 유용한 책 중 하나가 되리라 믿습니다!

드디어 아기다리 고기다리던 파이썬과 문제 해결 방법을 함께 배울 수 있는 <코딩 뇌를 깨우는 파이썬>이 출간되었습니다! 🙂
이 책은 아마존 베스트 셀러인 MIT 존 구태그John V. Guttag 교수의 “introduction to computation and programming using python” 3판의 번역서입니다. 파이썬 문법과 활용은 물론 파이썬으로 알고리즘과 최적화 기법을 구현하여 다양한 문제를 풀 수 있는 방법을 소개합니다.
파이썬과 알고리즘, 데이터 분석, 머시러닝까지 맛볼 수 있는 최고의 파이썬 학습 교재입니다. 각 장에 담긴 내용은 번역 후기를 참고하세요! 제가 동영상 강의도 제작하고 있습니다. 책과 함께 보시면 파이썬을 배우는데 큰 도움이 되실거에요. 기대해 주세요!

파이썬을 활용한 초절정 데이터 분석 입문서 <혼자 공부하는 데이터 분석 with 파이썬>이 출간되었습니다!
이 책은 파이썬 데이터 과학 생태계의 핵심 라이브러리인 판다스, 넘파이, 맷플롯립, 사이파이, 사이킷런을 사용하여 데이터 분석에 필요한 기초 지식을 쌓을 수 있도록 돕습니다. 또한 뷰티플수프, 리퀘스트 같은 유용한 다른 패키지도 함께 배울 수 있죠.
데이터 수집, 정제, 분석, 시각화, 검증 그리고 모델링까지 이 분야의 기술이 궁금하다면 바로 이 책으로 시작하세요!
동영상 강의도 함께 들으시면 책을 완독하는데 도움이 되실거에요! 🙂
한빛미디어의 혼공단에 참여해서 같이 공부하시면 더욱 좋습니다! 🙂

유일무이한 자바스크립트 딥러닝 라이브러리인 TensorFlow.js를 다룬 <구글 브레인 팀에게 배운 딥러닝 with TensorFlow.js>가 출간되었습니다.
이 책은 구글 브레인 팀에서 TensorFlow.js를 개발하고 지원하는 에릭 닐슨, 스탠 바일시, 샨칭 차이 그리고 케라스를 만든 프랑소와 숄레가 쓴 책입니다. TensorFlow.js 뿐만 아니라 일반적인 딥러닝에 대해서도 폭 넓은 주제를 담고 있습니다.
심층 신경망, 합성곱 신경망, 자연어 처리, 전이 학습, 시퀀스 모델링, 생성 모델, 강화 학습까지 20여개가 넘는 예제를 통해 딥러닝을 배워 보세요. 이 외에도 과대적합과 과소적합은 물론 일반적인 머신러닝의 워크플로에 대해서도 빠지지 않고 설명합니다.
자바스크립트 월드와 딥러닝 던전을 연결하는 멋진 세계를 지금 바로 경험해 보세요!

2017년 처음 이 책을 작업할 때 사이킷런 코드를 보면서 무식하게 노트에 한 줄 한 줄 펜으로 번역해서 옮겼던 기억이 납니다. 사이킷런 개발자가 쓴 책인만큼 잘 옮기고 싶었고 그때는 지금처럼 좋은 책이 많지 않아서 더 그랬던 것 같습니다.
무슨 생각이 들었는지 읽을만한 책을 만들자고 호기롭게 시작한 그 도전이 5년을 지나 오늘 여기까지 오게된 것 같네요. 이 책이 없었다면 아마 지금 다른 일을 하고 있을 것 같습니다.
2019년 번역개정판을 내고도 많은 분들에게 꾸준히 사랑을 받았습니다. 정말 감사드립니다. 새로운 번역개정2판은 최근 릴리즈된 사이킷런 1.0 버전을 반영하였습니다. 새로운 기능과 변경된 내용을 많이 담아서 500페이지가 넘었습니다. 또 구글 코랩에서 실습할 수 있도록 코드를 업데이트했습니다. 흔쾌히 번역개정2판을 허락해 주신 한빛미디어 출판사에 감사드립니다. 다시 한 번 머신러닝 학습의 엔트로피를 줄이는데 도움이 되기를 기대합니다! 감사합니다! 🙂

드디어 <머신러닝 파워드 애플리케이션>이 출간되었습니다! 이 책은 아마존 베스트셀러인 Building Machine Learning Powered Applications의 번역서입니다.
이 책에는 머신러닝 제품을 만들기 위해 고려해야할 많은 내용이 포함되어 있습니다. 머신러닝 제품을 만들기 위해 필요한 기술에서 알고리즘이 차지하는 부분은 작습니다. 책을 읽으면서 얼마나 많은 것들을 준비하고 생각해야 하는지 새삼 깨달았습니다. 책을 번역하면서 많은 것을 배웠습니다. 다른 분들에게도 도움이 되었으면 좋겠습니다. 감사합니다! 🙂

여름 내 작업했던 <머신러닝 파워드 애플리케이션>이 곧 출간됩니다. 아마도 다음 주 부터 온라인 서점에서 예약 판매가 시작될 예정입니다.
이 책은 아마존 베스트 셀러인 <Building Machine Learning Powered Applications>의 번역서입니다. 많은 머신러닝 책이 알고리즘 설명에 집중하고 있다보니 상대적으로 머신러닝 애플리케이션을 만드는데 도움이 되는 자료는 찾기 힘듭니다. 이 책은 이런 부분의 간극을 채우기 위한 좋은 시도입니다. 문제 정의, 데이터셋 찾기, 모델 구축, 디버깅, 배포에 이르기까지 실전에서 고려해야 할 좋은 가이드와 피해야 할 위험 요소를 잘 설명하고 있습니다. 특히 이 분야 리더들과의 인터뷰를 함께 싣고 있어서 설명이 조금 더 피부에 와 닿는 것 같습니다.
저자 에마뉘엘 아메장이 특별히 한국어판을 위한 서문을 보내 주었습니다. 책에 에마뉘엘의 사진과 함께 실을 예정인데요. 맛보기로 에마뉘엘이 쓴 서문을 공개합니다! ㅎ

많은 관심 부탁드립니다! 😀

세바스찬 라시카Sebastian Raschka와 바히드 미자리리Vahid Mirjalili가 쓴 아마존 베스트셀러 <Python Machine Learning 3rd Ed.>의 번역판인 <머신 러닝 교과서 3판>이 출간되었습니다!
3판은 사이킷런과 텐서플로 최신 버전의 변경 사항을 담았으며 코랩에서 실행할 수 있습니다. 특히 딥러닝 파트는 완전히 새롭게 리뉴얼되어 콘텐츠가 크게 보강되었습니다. 무엇보다도 이번에 새롭게 GAN과 강화 학습이 추가되어 머신러닝의 끝판왕이라고 부를만합니다!
출간에 맞추어 동영상 강의를 제작해 유튜브에 올리고 있습니다. 혼자 공부하시는 분들에게 도움이 되었으면 좋겠습니다. 궁금한 점이 있다면 블로그나 카카오 오픈채팅(http://bit.ly/tensor-chat, 참여코드: tensor)으로 알려 주세요!
온라인/오프라인 서점에서 판매 중입니다! 868페이지, 풀 컬러: 39,600원 [Yes24], [교보문고], [알라딘]
<파이썬 라이브러리를 활용한 머신러닝>의 주피터 노트북을 사이킷런 0.24.1 버전에 맞추어 모두 재실행하여 깃허브에 업데이트했습니다. 또 사이킷런 버전 변화에 따른 에러타를 새로 추가했습니다. 아래 목록을 참고해 주세요.
이 책은 2017년에 처음 번역서가 출간되었고 2019년에 개정판을 냈습니다. 처음 출간 시에는 흑백이었지만 개정판을 내면서 컬러를 입혔습니다. 이렇게 오랫동안 생명력을 유지할 수 있었던 것은 많은 독자들 덕분입니다. 다시 한번 이 책을 선택해 주신 독자들에게 감사드립니다. 책을 읽은 시간이 결코 아깝지 않기를 바랄 뿐입니다.
감사합니다.
KNeighborsClassifier 클래스의 n_neighbors 매개변수 기본값은 5입니다.</주석>X_train = data_train.date[:, np.newaxis]를 X_train = data_train.date.to_numpy()[:, np.newaxis]로 수정하고 X_all = ram_prices.date[:, np.newaxis]를 X_all = ram_prices.date.to_numpy()[:, np.newaxis]로 수정합니다.svc = SVC(C=1000)을 svc = SVC(C=20)으로 수정합니다.mlp = MLPClassifier(solver='lbfgs', random_state=0, hidden_layer_size=[10, 10])를 mlp = MLPClassifier(solver='lbfgs', random_state=0, hidden_layer_size=[10, 10], max_iter=1000)로 수정합니다.logreg=LogisticRegression()을 logreg=LogisticRegression(max_iter=1000)로 수정합니다.svm = SVC(C=100)을 svm = SVC(gamma='auto')로 수정합니다.mglearn.plots.plot_nmf_faces(X_train, X_test, image_shape)을 mglearn.plots.plot_nmf_faces(X_train, X_test[:3], image_shape)로 수정합니다.nmf = NMF(n_components=15, random_state=0, max_iter=1000, tol=1e-2)를 nmf = NMF(n_components=15, init='nndsvd', random_state=0, max_iter=1000, tol=1e-2)로 수정합니다.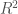 , 분류일 경우에는 정확도입니다. direction 매개변수가 ‘forward’일 경우 전진 선택법, ‘backward’일 때 후진 선택법을 수행합니다. 기본값은 ‘forward’입니다.</주석>
, 분류일 경우에는 정확도입니다. direction 매개변수가 ‘forward’일 경우 전진 선택법, ‘backward’일 때 후진 선택법을 수행합니다. 기본값은 ‘forward’입니다.</주석>spacy.load('en'을 spacy.load('en_core_web_sm'으로 수정합니다.