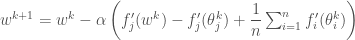Scikit-Learn 0.19 버전에서 추가된 기능 중 이번에는 모델 선택 패키지 하위에 있는 RepeatedKFold와 RepeatedStratifiedKFold를 알아 보겠습니다. 이 두 클래스는 각각 KFold와 StratifiedKFold를 감싸고 있는 래퍼 클래스처럼 보아도 무방합니다. 데이터셋의 크기가 크지 않을 경우, LOOCV를 사용하기에는 결과가 불안정해서 교차 검증을 반복적으로 여러번 수행하곤 합니다. 0.19 버전에서는 이런 반복적인 교차 검증을 수행할 수 있는 두 개의 클래스를 추가하였습니다.
RepeatedKFold와 RepeatedStratifiedKFold를 사용하는 방법은 다른 분할 클래스들과 매우 비슷합니다. 이 클래스들은 폴드를 한번만 나누는 것이 아니고 지정한 횟수(n_repeats)만큼 반복해서 나누게 되고 교차 검증 점수도 반복한 만큼 얻을 수 있습니다. 이때 기본적으로 랜덤하게 나누므로 분할기에 자동으로 Shuffle=True 옵션이 적용됩니다. n_repeats의 기본값은 10입니다.
붓꽃 데이터셋으로 이 클래스들을 사용해서 교차 검증을 해 보겠습니다.
사이킷런 0.19 버전 이하에서는 LinearSVC와 liblinear를 사용하는 LogisticRegression의 verbose 매개변수가 0이 아니고 max_iter 반복 안에 수렴하지 않을 경우 반복 횟수를 증가하라는 경고 메세지가 나옵니다. 사이킷런 0.20 버전부터는 verbose 매개변수에 상관없이 max_iter 반복 안에 수렴하지 않을 경우 반복 횟수 증가 경고가 나옵니다. 경고 메세지를 피하기 위해 max_iter 매개변수의 기본값을 증가시킵니다.
향후 사이킷런 0.22 버전에서 LogisticRegression 클래스의 solver 매개변수 기본값이 liblinear에서 lbfgs로 변경될 예정입니다. 사이킷런 0.20 버전에서 solver 매개변수를 지정하지 않는 경우 이에 대한 경고 메세지를 출력합니다. 경고 메세지를 피하고 향후 변경될 내용을 적용하기 위하여 solver 매개변수를 lbfgs로 설정합니다.
사이킷런 0.20 버전에서 LogisticRegression의 multi_class 매개변수 옵션에 auto가 추가되었습니다. auto로 설정하면 이진 분류이거나 solver가 liblinear일 경우에는 ovr을 선택하고 그 외에는 multinomial을 선택합니다. 사이킷런 0.22 버전부터는 multi_class 매개변수의 기본값이 ovr에서 auto로 변경됩니다. 경고 메세지를 피하기 위해 명시적으로 ovr 옵션을 지정합니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score, KFold, StratifiedKFold
from sklearn.linear_model import LogisticRegression
iris = load_iris()
logreg = LogisticRegression(solver='liblinear', multi_class='auto', max_iter=1000)
먼저 가장 기본이 되는 KFold를 사용한 교차 검증입니다.
kfold = KFold(n_splits=5)
scores = cross_val_score(logreg, iris.data, iris.target, cv=kfold)
scores, scores.mean()
(array([ 1. , 0.93333333, 0.43333333, 0.96666667, 0.43333333]),
0.7533333333333333)
iris 데이터셋은 타깃값의 순서대로 훈련 데이터가 정렬되어 있기 때문에 기본 KFold에서는 교차 검증 점수가 매우 들쭉 날쭉 합니다.
이번엔 RepeatedKFold를 사용해 보겠습니다. 사용법은 KFold와 같지만 반복 횟수(n_repeats)를 설정해 주고 결과를 일정하게 고정하기 위해 random_state를 지정했습니다.
from sklearn.model_selection import RepeatedKFold
rkfold = RepeatedKFold(n_splits=5, n_repeats=5, random_state=42)
scores = cross_val_score(logreg, iris.data, iris.target, cv=rkfold)
scores, scores.mean()
(array([ 1. , 0.93333333, 0.9 , 0.96666667, 0.96666667,
0.96666667, 0.93333333, 1. , 1. , 0.83333333,
0.93333333, 0.9 , 0.96666667, 0.9 , 0.93333333,
0.96666667, 1. , 0.96666667, 0.93333333, 0.93333333,
0.96666667, 0.9 , 1. , 0.93333333, 0.93333333]),
0.94666666666666677)
교차 검증 점수가 반복 횟수만큼 5개 행으로 출력되었습니다. 이전 보다 훨씬 고른 점수 분포를 보여 주며 전체 점수의 평균은 0.95 정도입니다. 교차 검증 점수의 범위를 박스플롯으로 가늠해 볼 수 있습니다.

다음엔 계층별 교차 검증인 StratifiedKFold를 적용해 보겠습니다.
skfold = StratifiedKFold(n_splits=5)
scores = cross_val_score(logreg, iris.data, iris.target, cv=skfold)
scores, scores.mean()
(array([ 1. , 0.96666667, 0.93333333, 0.9 , 1. ]),
0.96000000000000019)
StratifiedKFold는 타깃값 클래스 비율을 고려하므로 전체적으로 고르게 폴드를 나누어서 교차 검증 점수가 안정되었습니다. 그럼 RepeatedStratifiedKFold를 사용해서 비교해 보겠습니다.
from sklearn.model_selection import RepeatedStratifiedKFold
rskfold = RepeatedStratifiedKFold(n_splits=5, n_repeats=5, random_state=42)
scores = cross_val_score(logreg, iris.data, iris.target, cv=rskfold)
scores, scores.mean()
(array([ 0.96666667, 0.96666667, 0.96666667, 0.93333333, 0.96666667,
0.86666667, 0.96666667, 0.96666667, 0.93333333, 0.96666667,
1. , 1. , 0.93333333, 0.93333333, 0.93333333,
1. , 0.96666667, 0.96666667, 0.9 , 0.96666667,
0.96666667, 0.96666667, 0.96666667, 0.9 , 0.96666667]),
0.95466666666666655)
평균 교차 검증 점수는 0.955 정도로 RepeatedKFold와 StratifiedKFold의 중간에 해당하는 값입니다. 박스 플롯 끼리 비교해 보면 거의 비슷하지만 RepeatedStratifiedKFold가 약간 더 집중되어 있음을 알 수 있습니다.

이 두 클래스가 더욱 유용해질 때는 그리드서치에 사용할 때 입니다. cross_val_score와 마찬가지로 GridSearchCV의 분할은 회귀일 때는 KFold, 분류일 때는 StratifiedKFold가 기본입니다. 자원이 허락된다면 RepeatedKFold와 RepeatedStratifiedKFold로 바꾸지 않을 이유가 없습니다.
앞에서는 책의 예제와 비슷한 모양을 갖추기 위해 데이터셋을 나누지 않았습니다. 여기서는 훈련 데이터와 테스트 데이터로 나누고 RepeatedStratifiedKFold를 그리드서치에 적용해 보겠습니다.
사이킷런 0.22 버전부터는 GridSearchCV와 RandomizedSearchCV의 iid 매개변수 기본값이 True에서 False로 바뀝니다. 0.24 버전에서는 이 매개변수가 아예 삭제될 예정입니다. iid 매개변수가 True이면 독립 동일 분포라고 가정하고 테스트 세트의 샘플 수로 폴드의 점수를 가중 평균합니다. False로 지정하면 단순한 폴드 점수의 평균입니다. False일 때 기본 교차 검증과 동작 방식이 같습니다. 사이킷런 0.20 버전에서 iid 매개변수가 기본값일 때 가중 평균과 단순 평균의 차이가 10^-4 이상이면 경고 메세지가 발생합니다. 경고 메세지를 피하고 향후 변경될 방식을 사용하기 위해 GridSearchCV의 iid 매개변수를 False로 설정합니다
from sklearn.model_selection import GridSearchCV, train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=42)
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]}
grid = GridSearchCV(logreg, param_grid, cv=rskfold, return_train_score=True, iid=False)
grid.fit(X_train, y_train)
grid.score(X_test, y_test), grid.best_params_, grid.best_score_
테스트 점수는 완벽하고 규제 매개 변수 C의 최적값은 100이 선택되었습니다. 교차 검증 최고 점수는 0.96 입니다.
(1.0, {'C': 100}, 0.96250000000000002)
cv_results_에 있는 교차 검증 결과를 출력해 보면 훈련과 테스트에 대해 모두 5번 반복해서 각각 25개의 점수가 있는 것을 확인할 수 있습니다.
for k in grid.cv_results_:
if 'split' in k:
print(k, grid.cv_results_[k])
내용이 장황하므로 일부만 추렸습니다. 전체 출력 내용은 깃허브를 참고해 주세요.
split21_test_score [ 0.34782609 0.65217391 0.82608696 0.91304348 0.86956522 0.91304348
0.86956522]
split6_test_score [ 0.34782609 0.65217391 0.7826087 0.91304348 0.95652174 0.95652174
0.95652174]
split24_train_score [ 0.34065934 0.64835165 0.83516484 0.94505495 0.96703297 0.96703297
0.96703297]
split3_train_score [ 0.34444444 0.65555556 0.82222222 0.95555556 0.96666667 0.96666667
0.96666667]
...
split16_test_score [ 0.34782609 0.65217391 0.91304348 0.95652174 0.95652174 1.
0.95652174]
split23_test_score [ 0.31818182 0.63636364 0.77272727 0.95454545 0.95454545 0.95454545
0.95454545]
split1_test_score [ 0.34782609 0.65217391 0.86956522 0.82608696 0.91304348 0.95652174
1. ]
split18_train_score [ 0.34444444 0.65555556 0.82222222 0.95555556 0.96666667 0.96666667
0.96666667]
폴드 분할을 여러번 반복하여 그리드서치의 결과를 조금 더 안정적으로 만들 수 있을 것 같습니다. 반복 횟수가 클수록 훈련 시간은 느려지게 되므로 파이프라인 캐싱을 활용하고 가용한 자원내에서 반복을 수행하는 것이 좋을 것 같습니다.
이 샘플 코드는 ‘파이썬 라이브러리를 활용한 머신러닝‘ 깃허브(https://github.com/rickiepark/introduction_to_ml_with_python/blob/master/RepeatedKFold.ipynb)에서 확인할 수 있습니다.
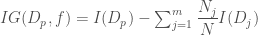
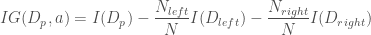



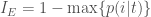




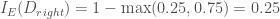
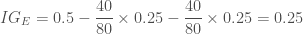
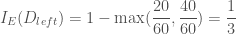

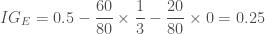


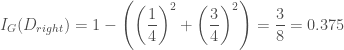


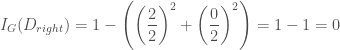

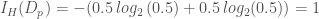
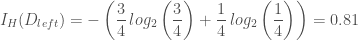

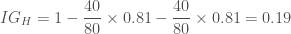

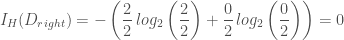














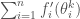 입니다. 그리고 현재 스텝에서 구한 그래디언트를
입니다. 그리고 현재 스텝에서 구한 그래디언트를 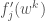 더하되 혹시 이전에 누적된 것에 포함이 되어 있다면, 즉 랜덤하게 추출한 적이 있는 샘플이라면 이전의 그래디언트 값을
더하되 혹시 이전에 누적된 것에 포함이 되어 있다면, 즉 랜덤하게 추출한 적이 있는 샘플이라면 이전의 그래디언트 값을  빼 줍니다. 혼돈을 줄이기 위해 현재의 스텝의 파라미터와 이전의 스텝의 파라미터를
빼 줍니다. 혼돈을 줄이기 위해 현재의 스텝의 파라미터와 이전의 스텝의 파라미터를 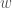 와
와  로 구별하였습니다.
로 구별하였습니다.