개발자들의 아지트 튜링의 사과에서 진행한 <머신러닝, 딥러닝 어떻게 공부할 것인가?>의 강의 영상이 유튜브에 업로드되었습니다! 시간이 여의치 않아 참석하지 못하신 분들에게도 온라인을 통해서나마 이야기를 전달해 드릴 수 있어서 기쁘네요. 재미있게 보시고 의견이나 궁금한 점 있으시면 댓글 남겨 주세요. 감사합니다!
“머신러닝, 딥러닝 어떻게 공부할 것인가!”
댓글 남기기
개발자들의 아지트 튜링의 사과에서 진행한 <머신러닝, 딥러닝 어떻게 공부할 것인가?>의 강의 영상이 유튜브에 업로드되었습니다! 시간이 여의치 않아 참석하지 못하신 분들에게도 온라인을 통해서나마 이야기를 전달해 드릴 수 있어서 기쁘네요. 재미있게 보시고 의견이나 궁금한 점 있으시면 댓글 남겨 주세요. 감사합니다!

<핸즈온 머신러닝 3판> 출간 기념으로 10월 18일 오후 7시 성수동 개발자 아지트 “튜링의 사과“에서 “머신러닝, 딥러닝 어떻게 공부할 것인가?“라는 주제로 강의를 합니다. 강의가 끝나고 사인회(!)도 합니다. 제가 쓰거나 번역한 책을 들고 놀러 오세요! 😀
이 강의는 무료이지만 노쇼(no-show)를 방지하기 위해 신청시 만원을 내시면 현장에서 돌려 받을 수 있습니다. 자리가 많지 않으니 서두르세요! 이벤트 안내 페이지: https://bit.ly/3ZLMyDn
튜링의 사과에 대한 소개는 여기를 참고하세요.

<핸즈온 머신러닝 3판>의 번역을 완료했습니다. 2판과 3판의 주요 차이점은 다음 그림을 참고하세요.
(3판 번역서는 9월 출간 예정이라고 합니다)

조금 더 자세하게 각 장의 내용을 요약하면 다음과 같습니다!
SimpleImputer외에 KNNImputer와 IterativeImputer로 언급합니다. 원-핫 인코딩 부분에서는 판다스의 get_dummies 함수를 추가로 소개하고 왜 사용하지 않는지 설명합니다. 최근 사이킷런에서 지원하는 데이터프레임 입력-데이터프레임 출력 기능을 잘 반영했습니다. 무엇보다도 새로운 ColumnTransformer를 적극 활용합니다. 사용자 정의 변환기는 TransformerMixin을 상속하는 방식에서 FunctionTransformer를 사용하는 예제로 바꾸었습니다. 마지막으로 하이퍼파라미터 튜닝 부분에서 HalvingGridSearchCV, HalvingRandomSearchCV 클래스도 잠깐 언급해 줍니다.DummyClassifier로 바꾸었습니다. 다중 분류에 대한 설명과 예제가 보강되었습니다. 오차 행렬에 대한 그래프가 대폭 변경, 추가되었고 설명도 상세해졌습니다. ClassifierChain에 대한 내용이 추가되었습니다. 코드는 전반적으로 새로 작성되었습니다.partial_fit()과 warm_start에 대한 설명이 추가되었고 규제항에 대한 공식을 변경했습니다. 조기 종료에 대한 코드와 설명이 보강되었습니다. 코드는 전반적으로 새로 작성되었습니다.LinearSVC와 SGDClassifier에 대한 설명이 보강되었고 힌지 손실과 제곱 힌지 손실에 대한 설명이 자세해졌습니다. 대신 콰드라틱 프로그래밍 절이 삭제되었습니다.n_iter_no_change를 사용하는 설명이 추가되었습니다. (드디어!) 히스토그램 부스팅 절이 추가되었습니다(하지만 XGBoost에 대해 자세히 다루지는 못했습니다). StackingClassifier를 사용하는 방식으로 스태킹 절이 대폭 수정되었습니다.PCA로 차원을 줄인후 하이퍼파라미터 튜닝을 하는 예제와 memmap 파일과 IPCA를 사용하는 예제가 추가되었습니다. 커널 PCA 절이 삭제되고 대신 랜덤 투영 절이 추가되었습니다.MLPRegressor 예제가 추가되었습니다. 케라스의 역사(?)에 대한 소개가 간략해졌고 설치 절이 삭제되었습니다. 전체적으로 케라스 API를 사용한 코드가 갱신되었습니다. 특히 캘리포니아 주택 데이터셋을 사용한 예제, 모델 저장과 복원, 콜백, 텐서보드 설명 등이 크게 바뀌었습니다. 그리고 드디어 하이퍼파라미터 튜닝을 위해 케라스 튜너를 다루는 절이 들어갔습니다! 꽤 상세히 설명하기 때문에 만족하실 것 같네요.Normalization, Discretization, CategoryEncoding, StringLookup, Hashing 층을 각각각의 절에서 자세히 설명합니다. 임베딩 소개 부분에서 StringLookup 층과 함께 사용하는 예시를 들어 보이며 텐서플로 허브에서 사전 훈련된 모델을 로드하는 방법을 소개합니다. 허깅 페이스를 사용한 예시는 16장으로 미룹니다. 또한 이미지를 위한 전처리 층도 간략히 소개합니다. 더 자세한 내용은 합성곱 신경망을 다루는 14장에서 설명할 예정입니다.statsmodels 라이브러리를 사용하고 몇가지 ARIMA 변종에 대해 살펴 볼 수 있습니다. 다변량 시계열 예측하기 절이 추가 되었고 여러 타임 스텝을 예측하는 절이 크게 바뀌었습니다. 시퀀스-투-시퀀스 방식을 사용하여 예측하는 방식이 추가되었습니다. 핍홀에 대한 설명이 삭제되었습니다.<핸즈온 머신러닝 2판>과 <Do It! 딥러닝 입문>의 주피터 노트북을 사이킷런 0.24와 텐서플로 2.4 버전에 맞추어 모두 다시 실행하여 깃허브(핸즈온 머신러닝 2 깃허브, Do It! 딥러닝 입문 깃허브)에 업데이트했습니다.
특히 <핸즈온 머신러닝 2판>의 노트북에는 원서 노트북의 변경 사항과 사이킷런, 텐서플로의 변경 사항이 다수 포함되어 있습니다. 알려진 버그를 회피하기 위한 코드 업데이트도 있습니다. 17장의 연습문제 9번의 솔루션이 이번에 추가되었습니다.
감사합니다! 🙂
안녕하세요. 핸즈온 머신러닝 2에 새롭게 에러타가 많이 추가되었습니다. 이번 에러타는 원서에 누적된 오류 보고를 포함하였고 사이킷런과 텐서플로 최신 버전에서 변경된 내용을 반영하였습니다. 다음 에러타 항목을 참고해 주세요. 핸즈온 머신러닝 2의 전체 에러타는 여기를 참고해 주세요. 감사합니다!
SimpleImputer의 객체를 생성합니다.<주석>옮긴이_ 사이킷런 0.22버전에서 최근접 이웃 방식으로 누락된 값을 대체하는 KNNImputer 클래스가 추가되었습니다.</주석>”make_column_selector() 함수가 추가되었습니다.</주석>”HalvingGridSearchCV와 HalvingRandomSearchCV가 추가됩니다. 이 예제는 https://bit.ly/halving-grid-search를 참고하세요.”fetch_openml() 함수에 as_frame 매개변수가 추가되었습니다. 이 매개변수를 True로 설정하면 판다스 데이터프레임을 반환합니다.</주석>”plot_precision_recall_curve() 함수가 추가되었습니다.”plot_roc_curve() 함수가 추가되었습니다.</주석>”plot_confusion_matrix() 함수가 추가되었습니다.</주석>”plot_tree() 함수도 추가되었습니다.”presort 매개변수로 얻을 수 있는 성능 향상이 크지 않기 때문에 사이킷런 0.24버전에서 결정 트리와 그레이디언트 부스팅 클래스의 presort 매개변수가 삭제됩니다.”min_impurity_decrease와 분할 대상이 되기 위해 … min_impurity_split가 추가되었습니다“를 “… min_impurity_decrease가 추가되었습니다. 분할 대상이 되기 위해 … min_impurity_split는 0.25버전에서 삭제됩니다“로 수정합니다. 또 10번 주석 끝에서 “… 지원합니다“를 “… 지원했지만 0.22버전에서 비용 복잡도 기반의 사후 가지치기를 위한 ccp_alpha 매개변수가 결정 트리와 트리 기반의 앙상블 모델에 추가되었습니다“로 수정합니다.max_samples 매개변수가 추가되었습니다. 샘플 크기를 정수로 입력하거나 비율을 실수로 지정할 수 있습니다. 기본값은 훈련 세트 전체 크기입니다.<주석>”validation_fraction 비율(기본값 0.1)만큼 떼어 내어 측정한 손실이 n_iter_no_change 반복 동안에 tol 값(기본값 1e-4) 이상 향상되지 않으면 훈련이 멈춥니다.</주석>”HistGradientBoostingClassifier와 HistGradientBoostingRegressor가 추가되었습니다.</주석>”StackingClassifier와 StackingRegressor가 추가되었습니다.</주석>”SelfTrainingClassifier가 추가됩니다.</주석>”compile() 메서드에 있는 steps_per_execution 매개변수를 1이상으로 설정하면 계산 그래프를 한 번 실행할 때 여러 배치를 처리할 수 있기 때문에 GPU를 최대로 활용하고 배치 크기를 바꾸지 않고 훈련 속도를 높일 수 있습니다.</주석>”tf.experimental.numpy가 추가되었습니다.</주석>”my_softplus 함수 옆의 주석을 “# tf.nn.softplus(z)와 반환값이 같습니다.“에서 “# tf.nn.softplus(z)가 큰 입력을 더 잘 다룹니다.“로 수정합니다.custom_model_in_keras.ipynb 주피터 노트북을 참고하세요.”tf.keras.layers.experimental.preprocessing 아래 이미지 처리, 이미지 증식, 범주형 데이터에 관련된 전처리 층이 추가되었습니다.</주석>”tf.config.experimental.get_memory_usage() 함수가 추가되었습니다.”MultiWorkerMirroredStrategy는 텐서플로 2.4에서 experimental을 벗어나 안정 API가 됩니다.</주석>” 또한 마지막 문단, 마지막 문장 끝에 다음처럼 주석을 추가합니다. “… 생성자에 전달하세요.<주석>옮긴이_ 텐서플로 2.4에서 CollectiveCommunication 클래스의 이름이 CommunicationImplementation로 바뀝니다.</주석>TPUStrategy는 텐서플로 2.3에서 experimental을 벗어나 안정 API가 되었습니다.</주석> 는
는  의 오른쪽에서
의 오른쪽에서  단위 행렬
단위 행렬 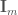 이 추가되고 … 채워진 행렬입니다.”를 “는 의 오른쪽에서
이 추가되고 … 채워진 행렬입니다.”를 “는 의 오른쪽에서 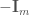 이 추가되고 … 채워진 행렬입니다(은 단위 행렬).”로 정정합니다. 또한 바로 아래 A 행렬의 첫 번째 행
이 추가되고 … 채워진 행렬입니다(은 단위 행렬).”로 정정합니다. 또한 바로 아래 A 행렬의 첫 번째 행 ![[\textbf{A}' \;\; \textbf{I}_m]](https://s0.wp.com/latex.php?latex=%5B%5Ctextbf%7BA%7D%27+%5C%3B%5C%3B+%5Ctextbf%7BI%7D_m%5D&bg=ffffff&fg=444444&s=0&c=20201002) 을
을 ![[\textbf{A}' \,\, -\textbf{I}_m]](https://s0.wp.com/latex.php?latex=%5B%5Ctextbf%7BA%7D%27+%5C%2C%5C%2C+-%5Ctextbf%7BI%7D_m%5D&bg=ffffff&fg=444444&s=0&c=20201002) 으로 정정합니다.
으로 정정합니다.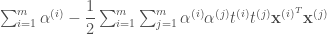
 일 때”를 “여기서 이고
일 때”를 “여기서 이고 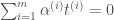 일 때”로 정정합니다.
일 때”로 정정합니다.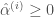 인 벡터 …”를 “이 함수를 최대화하고 … 이고
인 벡터 …”를 “이 함수를 최대화하고 … 이고 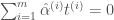 인 벡터 …”로 정정합니다.
인 벡터 …”로 정정합니다. 는 서포트 벡터의 개수입니다” 문장을 추가합니다.
는 서포트 벡터의 개수입니다” 문장을 추가합니다.사이킷런 0.20 버전에 맞추어 <핸즈온 머신러닝> 도서에 반영될 내용을 정리하였습니다. 깃허브 주피터 노트북에는 더 많은 내용이 반영되어 있습니다! 🙂
sklearn.preprocessing.Imputer 클래스는 사이킷런 0.22 버전에서 삭제될 예정입니다. 대신 0.20 버전에서 추가된 sklearn.impute.SimpleImputer 클래스로 변경합니다.
OneHotEncoder 클래스가 종전에는 훈련 데이터에 나타난 0~최댓값 사이 범위를 카테고리로 인식하여 원-핫 인코딩하지만 앞으로는 고유한 정수 값 또는 문자열을 원-핫 인코딩할 수 있습니다. 정수 특성과 문자열 특성이 함께 있는 경우에는 에러가 발생합니다. 경고 메세지를 피하고 고유한 값을 사용하는 방식을 선택하기 위해 categories 매개변수를 'auto'로 지정합니다.
encoder = OneHotEncoder()를 encoder = OneHotEncoder(categories='auto')로 변경합니다.RandomForestClassifier, RandomForestRegressor 모델의 n_estimators 기본값이 10에서 100으로 늘어납니다. 경고 메세지를 피하기 위해 명시적으로 트리 개수를 10으로 지정합니다.
RandomForestRegressor()를 RandomForestRegressor(n_estimators=10)으로 변경합니다.RandomForestClassifier()를 RandomForestClassifier(n_estimators=10)으로 변경합니다.fetch_mldata 함수가 mldata.org 사이트의 잦은 에러로 openml.org 를 사용하는 fetch_openml 함수로 변경되었습니다.
mnist = fetch_mldata('MNIST original')을 mnist = fetch_openml('mnist_784', version=1)로 변경합니다. openml.org의 MNIST 타깃 데이터는 문자열로 저장되어 있으므로 mnist.target = mnist.target.astype(np.int)와 같이 정수로 바꾸는 것이 좋습니다.LogisticRegression 클래스의 solver 매개변수 기본값이 'liblinear'에서 'lbfgs'로 변경될 예정입니다. 경고 메세지를 피하고 출력 결과를 일관되게 유지하기 위하여 solver 매개변수를 'liblinear'로 설정합니다.
LogisticRegression()을 LogisticRegression(solver='liblinear')로 변경합니다.SVC, SVR 클래스의 gamma 매개변수 옵션에 'auto'외에 'scale'이 추가되었습니다. 'auto'는 1/n_features, 즉 특성 개수의 역수입니다. 'scale'은 1/(n_features * X.std())로 스케일 조정이 되지 않은 특성에서 더 좋은 결과를 만듭니다. 사이킷런 0.22 버전부터는 gamma 매개변수의 기본값이 'auto'에서 'scale'로 변경됩니다. 서포트 벡터 머신을 사용하기 전에 특성을 표준화 전처리하면 'scale'과 'auto'는 차이가 없습니다. 경고를 피하기 위해 명시적으로 'auto' 옵션을 지정합니다.
SVR(kernel="poly", degree=2, C=100, epsilon=0.1)을SVR(kernel="poly", gamma='auto', degree=2, C=100, epsilon=0.1)로 변경합니다.SVC()를 SVC(gamma='auto')로 변경합니다.LinearSVC의 verbose 매개변수가 0이 아닐 때 max_iter 반복 횟수가 부족하면 경고 메세지가 출력됩니다. 사이킷런 0.20 버전부터는 verbose 매개변수에 상관없이 max_iter 반복 안에 수렴하지 않을 경우 반복 횟수 증가 경고가 나옵니다. 경고 메세지를 피하기 위해 max_iter 매개변수의 기본값을 1,000에서 2,000으로 증가시킵니다.
LinearSVC(C=10, loss="hinge")를 LinearSVC(C=10, loss="hinge", max_iter=2000)으로 변경합니다.핸즈온 머신러닝 깃허브에 있는 부록 중 넘파이 튜토리얼을 번역하여 커밋하였습니다. 내용이 길어 생각보다 훨씬 오래 걸린 것 같습니다. 이 노트북을 막다운으로 변경하여 블로그의 핸즈온 머신러닝 1장, 2장 문서에도 포함했습니다. 재미있게 봐주세요! 🙂
핸즈온 머신러닝의 원서 주피터 노트북이 조금 업데이트되었습니다. 변경된 내용을 번역서의 깃허브에도 반영하였습니다. 다음은 변경된 상세 내용입니다.
my_reber_classifier의 경로를 변경하고 추정 확률을 퍼센트로 나타냅니다.
with tf.Session() as sess:
saver.restore(sess, "my_reber_classifier")
y_proba_val = y_proba.eval(feed_dict={X: X_test, seq_length: l_test})
print()
print("레버 문자열일 추정 확률:")
for index, string in enumerate(test_strings):
print("{}: {:.2f}%".format(string, y_proba_val[index][0]))
을 다음으로 변경합니다.
with tf.Session() as sess: saver.restore(sess, "./my_reber_classifier") y_proba_val = y_proba.eval(feed_dict={X: X_test, seq_length: l_test}) print() print("레버 문자열일 추정 확률:") for index, string in enumerate(test_strings): print("{}: {:.2f}%".format(string, 100 * y_proba_val[index][0]))
ColumnTransformer를 사용하면 책의 예제에서처럼 DataFrameSelector와 FeatureUnion을 사용하지 않고 간단히 전체 파이프라인을 만들 수 있습니다. 아직 사이킷런 0.20 버전이 릴리스되기 전이므로 여기서는 future_encoders.py에 ColumnTransformer를 넣어 놓고 사용합니다.
from future_encoders import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
housing_prepared
hidden3 = tf.get_default_graph().get_tensor_by_name("dnn/hidden4/Relu:0")
을 다음으로 변경합니다.
hidden3 = tf.get_default_graph().get_tensor_by_name("dnn/hidden3/Relu:0")
for var in output_layer_vars:
var.initializer.run()
감사합니다! 🙂




