<핸즈온 머신러닝 3판>의 번역을 완료했습니다. 2판과 3판의 주요 차이점은 다음 그림을 참고하세요.
(3판 번역서는 9월 출간 예정이라고 합니다)

조금 더 자세하게 각 장의 내용을 요약하면 다음과 같습니다!
- 1장은 큰 변화가 없습니다. 지도 학습, 비지도 학습, 준지도 학습 외에 자기 지도 학습 설명이 추가되었습니다. 삶의 만족도 예제를 위한 데이터를 최신으로 업데이트했습니다. 홀드아웃 검증에 대한 그림과 훈련-개발 세트를 설명하는 그림이 추가되었습니다.
- 2장은 그간 사이킷런이 많이 업데이트되었기 때문에 소소한 부분이 많이 바뀌었습니다. 먼저 주피터 노트북 대신 코랩에 대한 간략한 설명으로 시작합니다. 코랩의 편리함과 주의 사항도 언급합니다. 캘리포니아 주택 데이터셋을 사용하는 예제는 전반적으로 깔끔하게 코드를 정리했습니다.
SimpleImputer외에KNNImputer와IterativeImputer로 언급합니다. 원-핫 인코딩 부분에서는 판다스의get_dummies함수를 추가로 소개하고 왜 사용하지 않는지 설명합니다. 최근 사이킷런에서 지원하는 데이터프레임 입력-데이터프레임 출력 기능을 잘 반영했습니다. 무엇보다도 새로운ColumnTransformer를 적극 활용합니다. 사용자 정의 변환기는TransformerMixin을 상속하는 방식에서FunctionTransformer를 사용하는 예제로 바꾸었습니다. 마지막으로 하이퍼파라미터 튜닝 부분에서HalvingGridSearchCV,HalvingRandomSearchCV클래스도 잠깐 언급해 줍니다. - 3장은 큰 변화는 없고 자잘한 수정이 많습니다. 편향된 데이터셋에 대한 문제점을 보이기 위해 만든 자작 클래스를 사이킷런의
DummyClassifier로 바꾸었습니다. 다중 분류에 대한 설명과 예제가 보강되었습니다. 오차 행렬에 대한 그래프가 대폭 변경, 추가되었고 설명도 상세해졌습니다.ClassifierChain에 대한 내용이 추가되었습니다. 코드는 전반적으로 새로 작성되었습니다. - 4장도 큰 변화가 없습니다.
partial_fit()과warm_start에 대한 설명이 추가되었고 규제항에 대한 공식을 변경했습니다. 조기 종료에 대한 코드와 설명이 보강되었습니다. 코드는 전반적으로 새로 작성되었습니다. - 5장은
LinearSVC와SGDClassifier에 대한 설명이 보강되었고 힌지 손실과 제곱 힌지 손실에 대한 설명이 자세해졌습니다. 대신 콰드라틱 프로그래밍 절이 삭제되었습니다. - 6장은 거의 변화가 없고 결정 트리가 축 회전에 대한 민감하다는 것과 분산이 높다는 것을 설명하기 위한 절이 추가되었습니다.
- 7장은 그레이디언트 부스팅의 조기 종료를 위해
n_iter_no_change를 사용하는 설명이 추가되었습니다. (드디어!) 히스토그램 부스팅 절이 추가되었습니다(하지만 XGBoost에 대해 자세히 다루지는 못했습니다).StackingClassifier를 사용하는 방식으로 스태킹 절이 대폭 수정되었습니다. - 8장에서
PCA로 차원을 줄인후 하이퍼파라미터 튜닝을 하는 예제와memmap파일과IPCA를 사용하는 예제가 추가되었습니다. 커널 PCA 절이 삭제되고 대신 랜덤 투영 절이 추가되었습니다. - 9장에서 가우스 혼합 모델의 이론 부분이 삭제되었습니다. 사이킷런의 준지도 학습 클래스에 대한 소개가 추가되었습니다. 유사도 전파에 대한 설명이 보강되었습니다.
- 10장은 케라스를 사용한 인공 신경망을 소개합니다. 그간 편향 뉴런을 따로 표기했는데 3판에서 드디어 이를 뺐습니다.
MLPRegressor예제가 추가되었습니다. 케라스의 역사(?)에 대한 소개가 간략해졌고 설치 절이 삭제되었습니다. 전체적으로 케라스 API를 사용한 코드가 갱신되었습니다. 특히 캘리포니아 주택 데이터셋을 사용한 예제, 모델 저장과 복원, 콜백, 텐서보드 설명 등이 크게 바뀌었습니다. 그리고 드디어 하이퍼파라미터 튜닝을 위해 케라스 튜너를 다루는 절이 들어갔습니다! 꽤 상세히 설명하기 때문에 만족하실 것 같네요. - 11장은 신경망 훈련을 위한 다양한 기술을 다룹니다. 기존 활성화 함수 설명외에 추가로 GELU, Swish, Mish가 포함되었습니다. 옵티마이저에서는 AdamW가 추가되었습니다. 배치 정규화, 전이 학습, 학습률 스케줄링, 몬테 카를로 드롭아웃 등 주요 코드와 설명이 업데이트되었습니다. 특히 실용 가이드라인이 최신 기술에 맞게 바뀌었습니다.
- 12장은 텐서플로로 사용자 정의 모델을 만들고 훈련하는 내용을 다룹니다. 더이상 사용되지 않는 케라스 백엔드 관련 내용이 업데이트되었습니다. 사용자 정의 지표, 층, 모델, 훈련을 위한 코드와 설명이 최신 케라스 버전에 맞추어 모두 업데이트 되었습니다. 텐서플로 그래프 섹션에 XLA 설명이 추가되었습니다.
- 13장은 데이터 전처리에 대한 소개하며 이전 판에 비해 많은 수정이 있습니다. tf.Transform을 삭제하고 케라스 전처리 층에 대한 내용을 크게 확대했습니다. tf.data API를 사용한 코드가 개선되었고 케라스와 함께 사용하는 예시도 대폭 변경되었습니다. 케라스 전처리 층으로
Normalization,Discretization,CategoryEncoding,StringLookup,Hashing층을 각각각의 절에서 자세히 설명합니다. 임베딩 소개 부분에서StringLookup층과 함께 사용하는 예시를 들어 보이며 텐서플로 허브에서 사전 훈련된 모델을 로드하는 방법을 소개합니다. 허깅 페이스를 사용한 예시는 16장으로 미룹니다. 또한 이미지를 위한 전처리 층도 간략히 소개합니다. 더 자세한 내용은 합성곱 신경망을 다루는 14장에서 설명할 예정입니다. - 14장에서 텐서플로 저수준 연산을 사용하는 합성곱 신경망의 예제가 케라스 코드와 설명으로 바뀌었습니다. 깊이 방향 풀링을 구현하는 예시를 텐서플로 저수준 연산과 람다 층을 사용한 코드에서 케라스 사용자 정의 층으로 바꾸었습니다. 대표적인 CNN 구조 소개에서 SENet이 추가되었습니다. 또한 마지막에 간략하지만 Xception, ResNeXt, DenseNet, MobileNet, CSPNet, EfficientNet도 소개하고 CNN 구조 선택 가이드라인을 제시합니다. 객체 탐지에 대한 설명이 보강되고 객체 추적이 추가되었습니다.
- 15장은 큰 폭으로 바뀌었습니다. 인공 데이터셋을 사용하지 않고 시카고 교통 데이터를 사용하도록 전체 예제를 바꾸었습니다. 기준 모델로 선형 모델 외에 ARIMA 모델이 추가되었습니다. 이를 위해
statsmodels라이브러리를 사용하고 몇가지 ARIMA 변종에 대해 살펴 볼 수 있습니다. 다변량 시계열 예측하기 절이 추가 되었고 여러 타임 스텝을 예측하는 절이 크게 바뀌었습니다. 시퀀스-투-시퀀스 방식을 사용하여 예측하는 방식이 추가되었습니다. 핍홀에 대한 설명이 삭제되었습니다. - 16장은 NLP를 다루며 책 전체에서 가장 많이 바뀐 장이 아닐까 합니다. 그만큼 NLP 분야의 변화가 크다는 의미 같습니다. 셰익스피어 텍스트를 생성하는 예제는 15장에서 윈도 데이터셋을 상당히 다룬 덕분에 코드와 설명이 간소화되었습니다. 대신 텍스트 전처리 층을 최종 모델에 포함하는 예시가 추가되었습니다. IMDb 감성 분석 예제는 케라스 전처리 층을 사용하도록 코드와 설명이 모두 바뀌었습니다. 케라스에서 마스킹 처리에 대한 설명이 업데이트되었습니다. 사전 훈련된 단어 임베딩의 설명을 업데이트하고 언어 모델에 대한 소개가 추가되었습니다. 영어-프랑스어 번역 예제를 영어-스페인어 번역 예제로 바꾸고 전체 코드와 설명이 업데이트되었습니다. 텐서플로 애드온을 사용했던 어텐션 예제를 케라스 어텐션 층으로 바꾸었습니다. 트랜스포머에 대한 설명이 업데이트되었고 인코더와 디코더 구조를 직접 구현하는 예시가 포함되었습니다. 최근에 등장한 다양한 언어 모델에 대한 소개가 많이 추가되었고 마지막에 허깅 페이스 트랜스포머스 라이브러리를 사용하는 예시가 포함되었습니다!
- 17장은 기존 컨텐츠를 거의 그대로 유지하고 확산 모델만 추가되었습니다. 확산 모델의 개념과 이론을 설명하고 정방향 과정과 역방향 과정을 직접 구현하여 패션 MNIST와 유사한 이미지를 생성하는 예제를 다룹니다.
- 18장은 강화 학습을 다룹니다. 2판의 내용을 그대로 승계하고 주로 코드를 최신으로 업데이트했습니다. 부족한 지면 때문에 TF-Agents 절이 삭제되었습니다.
- 19장은 분산 훈련과 배포에 관한 주제를 다룹니다. 텐서플로 서빙에 대한 설명과 코드가 많이 변경되었습니다. GCP AI 플랫폼에 대한 부분을 모두 버텍스 AI로 업데이트했습니다(거의 새로 작성 했네요). 웹 페이지에서 모델 실행을 위한 TFJS 설명이 보강되었고 예제도 추가되었습니다. 병렬화 기술 소개에 PipeDream과 Pathways가 추가되었습니다. 마지막으로 버텍스 AI의 하이퍼파라미터 튜닝 방법과 케라스 튜너를 사용한 하이퍼파라미터 튜닝 방법이 추가되었습니다.



 는
는  의 오른쪽에서
의 오른쪽에서  단위 행렬
단위 행렬 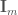 이 추가되고 … 채워진 행렬입니다.”를 “
이 추가되고 … 채워진 행렬입니다.”를 “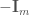 이 추가되고 … 채워진 행렬입니다(
이 추가되고 … 채워진 행렬입니다(![[\textbf{A}' \;\; \textbf{I}_m]](https://s0.wp.com/latex.php?latex=%5B%5Ctextbf%7BA%7D%27+%5C%3B%5C%3B+%5Ctextbf%7BI%7D_m%5D&bg=ffffff&fg=444444&s=0&c=20201002) 을
을 ![[\textbf{A}' \,\, -\textbf{I}_m]](https://s0.wp.com/latex.php?latex=%5B%5Ctextbf%7BA%7D%27+%5C%2C%5C%2C+-%5Ctextbf%7BI%7D_m%5D&bg=ffffff&fg=444444&s=0&c=20201002) 으로 정정합니다.
으로 정정합니다.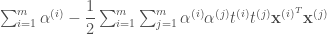
 일 때”를 “여기서
일 때”를 “여기서 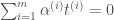 일 때”로 정정합니다.
일 때”로 정정합니다.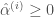 인 벡터 …”를 “이 함수를 최대화하고 …
인 벡터 …”를 “이 함수를 최대화하고 … 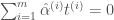 인 벡터 …”로 정정합니다.
인 벡터 …”로 정정합니다. 는 서포트 벡터의 개수입니다” 문장을 추가합니다.
는 서포트 벡터의 개수입니다” 문장을 추가합니다.



