경사하강법gradient descent 최적화 알고리즘의 한 종류인 모멘텀momentum과 네스테로프 모멘텀nesterov momentum 방식은 여러 신경망 모델에서 널리 사용되고 있습니다. 비교적 이 두가지 알고리즘은 직관적이고 쉽게 이해할 수 있습니다. 이 글에서는 두 알고리즘이 실제 구현에서는 어떻게 적용되는지 살펴 보겠습니다.
모멘텀 알고리즘은 누적된 과거 그래디언트가 지향하고 있는 어떤 방향을 현재 그래디언트에 보정하려는 방식입니다. 일종의 관성 또는 가속도처럼 생각하면 편리합니다. 머신 러닝의 다른 알고리즘들이 그렇듯이 모멘텀 공식도 쓰는 이마다 표기법이 모두 다릅니다. 여기에서는 일리아 서스키버Ilya Sutskever의 페이퍼1에 있는 표기를 따르겠습니다. 모멘텀 알고리즘의 공식은 아래와 같습니다.
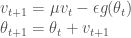


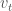
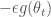


이 그림은 일리아 서스키버의 페이퍼1에서 캡쳐한 것입니다. 윗쪽의 그림이 일반 모멘텀 방식을 설명해 주고 있습니다. 파라미터 공간의 현재 위치 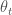


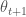

그럼 네스테로프 모멘텀은 어떻게 다를까요. Figure 1 의 하단 그림과 아래 공식을 함께 보면 조금 더 이해가 쉽습니다.

이 공식은 모멘텀의 공식과 거의 같습니다. 다만 현재 위치의 그래디언트 
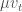
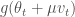
모멘텀 방식과 네스테로프 모멘텀은 확실히 다릅니다. 아래 그림에서 편의상 동일 지점에서 모멘텀과 네스테로프 모멘텀을 한번에 나타내었습니다. 이 그림에서 볼 수 있듯이 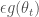
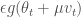

네스테로프 모멘텀의 진행과정을 조금 더 자세히 보기 위해 반복 스텝 t 의 전후를 이어서 그려 보겠습니다.

우리가 위에서 본 네스테로프 모멘텀 공식으로 현재 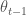
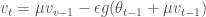
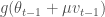
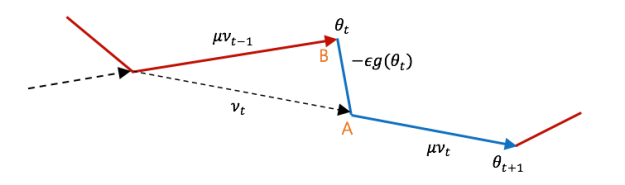
위 그림에서 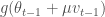
현재 위치에서 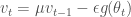
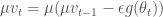
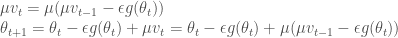
이렇게 쓰면 현재 그래디언트와 이전의 속도만 가지고 네스테로프 모멘텀의 궤적을 따라갈 수 있습니다. 사실 이 식은 요수아 벤지오Yoshua Bengio 교수의 페이퍼3에 잘 설명되어 있습니다. 다만 식을 쓰는 순서가 조금 다를 뿐입니다. 안드레이 카패시Andrej Karpathy도 CS231n 강의 노트4에 벤지오 교수의 표기와 유사하게 설명하고 있습니다. 위 그림을 CS231n 강의 노트 표기로 바꾸어 나타내어 보면 아래와 같습니다.
v_prev = v # back this up
v = mu * v - learning_rate * dx # velocity update stays the same
x += -mu * v_prev + (1 + mu) * v # position update changes form
이제 조금더 명확해 진 것 같습니다. 하지만 실제 코드들은 벤지오 교수의 표기 보다는 아래와 같이 쓰는 것을 즐겨합니다.
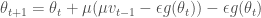
또 이식은 다음처럼 나누어 쓰면 패턴이 잘 보입니다.
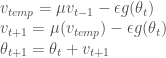
이렇게 보면 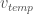


여기에서
그럼 실제 코드 구현을 확인해 보겠습니다. 제가 눈으로 확인한 것은 사이킷런scikit-learn의 멀티레이어 퍼셉트론multi-layer perceptron의 구현5과 케라스Keras의 구현6입니다.
사이킷런의 SGDOptimizer 클래스 중 일부 코드입니다.
updates = [self.momentum * velocity - self.learning_rate * grad
for velocity, grad in zip(self.velocities, grads)]
self.velocities = updates
if self.nesterov:
updates = [self.momentum * velocity - self.learning_rate * grad
for velocity, grad in zip(self.velocities, grads)]
다음은 케라스의 SGD 클래스 중 일부 코드입니다.
v = self.momentum * m - lr * g # velocity
self.updates.append(K.update(m, v))
if self.nesterov:
new_p = p + self.momentum * v - lr * g
else:
new_p = p + v
코드를 보면 이해가 더 잘 됩니다. 이렇게 네스테로프 모멘텀을 일반 모멘텀을 이용해 구하는 방식은 코드를 깔끔하고 읽기 좋게 만들어 줍니다. 사실 되짚어 보면 이런 테크닉이 매우 난해한 것은 아닙니다. 다만 구현된 코드들에 별다른 설명이 없고 대부분의 네스테로프 모멘텀의 방정식이 일리아 서스키버의 표현 방식으로 기술되어 있어서 처음 볼 때 고개를 갸우뚱하게 되는 것 같습니다. 🙂
- Ilya Sutskever, James Martens, George Dahl, Geoffrey Hinton. 2013. On the importance of initialization and momentum in deep. pdf
- Sebastian Ruder. 2016. An overview of gradient descent optimization algorithms. 1609.04747
- Yoshua Bengio, Nicolas Boulanger-Lewandowski, Razvan Pascanu. 2012. Advances in Optimizing Recurrent Networks. 1212.0901
- CS231n Convolutional Neural Networks for Visual Recognition. website.
- https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/neural_network/_stochastic_optimizers.py
- https://github.com/fchollet/keras/blob/master/keras/optimizers.py

어느정도 개념만 이해하고 넘어간 부분인데
시간날때 이 포스팅 보면서 제대로 정리해야겠습니다.
감사합니다.
좋아요Liked by 1명
시간을 들여서 차근히 들여다보았더니 겨우 이해했습니다. 감사합니다.
좋아요Liked by 1명
좋은 글 감사합니다. 저도 이 부분에 대해 한번 정리를 해보려고 했었는데 시간을 내여 포스팅 해주셨습니다.
좋아요Liked by 1명
정말 재미있게 읽어내려갔습니다.!!!
꼼꼼하게 정리해주시고 그림도 자세히 넣어 주셔서 이해하는데 도움이 많이 되었어요~
너무 감사드립니다 ^^
좋아요Liked by 1명
도움이 되셨다니 기쁘네요! 🙂
좋아요좋아요
이렇게 쉽게 식이 바뀌다니… 처음 식을 보고 gradient(θt + μvt) 를 어떻게 구현해야하나 막막했는데… 이렇게 보니까 훨씬 쉽게 구현할 수 있겠네요! 정말 감사합니다!
좋아요Liked by 1명
이해 안되던게 이해가 되네요. 감사합니다. 종종 찾아오겠습니다.
좋아요Liked by 1명