
★★★★★ 머신러닝의 바이블! (s******u 님)
★★★★★ 머신러닝을 하는 개발자의 책장에서는 반드시 이 책을 찾을 수 있을 것입니다. (p******k 님)
♥♥♥♥ 매우 훌룡합니다 기본기까지 다져주는 책이라 생각합니다. (ho**76 님)
♥♥♥♥ 인기가 많다고 해서 구매했는데 왜 인기있는지 알거같아요. 이해하기 쉽습니다. (al**e0609 님)
이 책은 글로벌 베스트 셀러인 “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow 2nd Edition“의 번역서입니다.
교보문고 IT 전문서 머신러닝/딥러닝 분야 2020 올해의 책 선정

흔쾌히 추천사를 써 주신 권순선 님, 베타 리뷰에 참여해 주신 김대근, 김주현, 류회성, 박인창, 박찬성, 백혜림, 변성윤, 이고은, 이석곤, 이제현, 장대혁, 정도현, 최영철, 허민, 현재웅 님께 감사드립니다. 시작부터 끝까지 특별히 신경 써 주신 윤나리 님과 둔탁한 글을 다듬어 주신 백지선 님께 감사드립니다. 무엇보다도 번역서를 기다려 주시고 격려의 말을 보내 주신 모든 독자들에게 감사드립니다. 부디 즐거운 여행이 되시길 바라겠습니다! 🙂
- 온라인/오프라인 서점에서 판매중입니다. Yes24, 교보문고, 알라딘, 한빛미디어
- 952 페이지, 풀 컬러
- 종이책:
55,000원—>49,500원, 전자책: 44,000원 - 이 책에 실린 코드는 깃허브에 주피터 노트북으로 불 수 있습니다. Github, Nbviewer
- 이 책의 코드는 scikit-learn 0.22, 0.23, 0.24 TensorFlow 2.1, 2.2, 2.3, 2.4에서 테스트했습니다.
- 번역 후기를 여기에 적었습니다.
- 이 책을 읽은 독자들의 리뷰: 시나브로 님, Cory 님
- 이 책의 동영상 강의를 유튜브와 인프런에서 볼 수 있습니다! Youtube, 인프런
이 페이지에서 책의 에러타와 scikit-learn과 tensorflow 버전 변경에 따른 바뀐 점들을 계속 업데이트 하겠습니다. 이 책에 대해 궁금한 점이나 오류가 있으면 이 페이지 맨 아래 ‘Your Inputs’에 자유롭게 글을 써 주세요. 또 제 이메일을 통해서 알려 주셔도 되고 구글 그룹스 머신러닝 도서 Q&A에 글을 올려 주셔도 좋습니다.
감사합니다! 🙂
Outputs (aka. errata)
- 1~12: 2쇄에 반영되었습니다.
- ~35: 3쇄에 반영되었습니다.
- ~89: 4쇄에 반영되었습니다.
- ~103: 5쇄에 반영되었습니다.
- ~118: 6쇄에 반영되었습니다.
- ~122: 7쇄에 반영되었습니다.
- (p254) 아래에서 2번째 줄에 RandomForestClassifer를 RandomForestClassifier로 정정합니다.
- (p459) 위에서 7번째 줄에 “15비트”를 “16비트”로 정정합니다.(현*웅 님)
- (p236) 위에서 5번째 줄에
을
로 정정합니다.(이*석 님)
- (p239) 아래에서 4번째 줄에 “예를 들어
인 샘플의 클래스를 예측한다고”를 “예를 들어
- (p844) 연습문제 11번 답의 시작 부분에서 “인스턴스 기반 학습”을 “사례 기반 학습”으로 바꿉니다.
- (p299) 아래에서 2번째 줄에 “비지도 학습 방업인”을 “비지도 학습 방법인”으로 정정합니다.(이*범 님)
- (p113) CAUTION 상자의 문단 마지막의 주석 번호를 51에서 52로 정정합니다.(김*훈 님)
- (p179) CAUTION 안의 주석 번호 27을 24로 정정합니다.
- (p368) 아래에서 7번째 줄에 PlainML을 PlaidML로 정정합니다.
- (p168) CAUTION 안의 주석 번호 13을 11로 정정합니다.
- (p269) 첫 문장에서 ‘서브셋로 나눕니다’를 ‘서브셋으로 나눕니다’로 정정합니다.
- (p174) [그림 4-10] 아래에 있는 두 문단 사이에 CAUTION이 빠졌습니다. 다음을 추가합니다.
CAUTION: 확률적 경사 하강법을 사용할 때 훈련 샘플이 IID(independent and identically distributed)를 만족해야 평균적으로 파라미터가 전역 최적점을 향해 진행한다고 보장할 수 있습니다. 이렇게 만드는 간단한 방법은 훈련하는 동안 샘플을 섞는 것입니다(예를 들어, 각 샘플을 랜덤하게 선택하거나 에포크를 시작할 때 훈련 세트를 섞습니다). 만약 레이블 순서대로 정렬된 샘플처럼 샘플을 섞지 않은 채로 사용하면 확률적 경사 하강법이 먼저 한 레이블에 최적화하고 그다음 두 번째 레이블을 최적화하는 식으로 진행됩니다. 결국 이 모델은 최적점에 가깝게 도달하지 못할 것입니다. - (p97) 마지막 줄, (p98) 아래에서 5번째, 6번째 줄에 ‘침대‘를 ‘침실‘로 정정합니다.
- (p404) 학습률 섹션의 첫 번째 문장에서 ‘가중 중요한 하이퍼파라미터입니다’를 ‘가장 중요한 하이퍼파라미터입니다’로 정정합니다.(김*교 님)
- (p14) 첫 번째 줄에서 ‘셀처럼’을 ‘셸처럼’으로 정정합니다.(김*모 님)
- (p146) 아래에서 4번째 줄에서 “10개의 이진 분류기를 훈련시키고”를 “45개의 이진 분류기를 훈련시키고”로 정정합니다.(최*민 님)
- (p132) 위에서 3번째 줄 코드의
StratifiedKFold클래스에서shuffle=False기본값을 그대로 두고random_state를 지정하면 경고가 발생합니다. 0.24버전부터는 에러가 발생될 예정이므로 명시적으로shuffle=True매개변수를 추가합니다. - (p93)
housing.plot()메서드 호출에서 x 축의 레이블을 올바르게 표시하기 위해sharex=False매개변수를 추가합니다. - (p364) 페이지 중간에 있는 두 번째 목록 ReLU 함수 옆에 “(9장 참조)“를 삭제합니다.(최*민 님)
- (p288) 첫 번째 줄에 “500보다 그고“를 “500보다 크고“로 정정합니다.(김*훈 님)
- (p655) 페이지 중간 21번 주석 앞에 “성능을 크게 향상했습니다”를 “성능을 크게 향상시켰습니다”로 바꿉니다.(김*훈 님)
- (p105) 44번 주석에서
Transformer Mixin을TransformerMixin으로 정정합니다.(김*훈 님) - (p138) 첫 번째 코드 블럭 마지막 줄을 다음과 같이 수정합니다.(김*훈 님)
>>> y_some_digit_pred = (y_scores > threshold)>>> y_some_digit_pred
array([ True]) - (p188) 아래에서 1번째와 2번째 줄에서 “
를 …”을 “
- (p198) 아래에서 2번째 줄에서 “수평한 직선들은”을 “나란한 직선들은”로 수정합니다.(김*훈 님)
- (p317) 9.1.4절 아래 첫 번째 문장에서 “알고리즘을 적용하지 전에”를 “알고리즘을 적용하기 전에”로 정정합니다.(김*훈 님)
- (p175) 18번 주석 학습률
공식에서 분모가
가 아니고
입니다.(조*기 님)
- (p309) 위에서 4번째 줄에서 “거리 계산을 많이 피함으로서“를 “거리 계산을 많이 피하여“로 수정합니다.(김*훈 님)
- (p462) 3번 주석에서 “커뮤티니에서 번역하고”를 “커뮤니티에서 번역하고”로 정정합니다.(김*훈 님)
- (p469) 7번 주석에서 “값을 증가하거나“를 “값을 증가시키거나“로 정정합니다.(김*훈 님)
- (p495) 위에서 2번째 줄에 “어떻게 사용지 알아봅시다”를 “어떻게 사용하는지 알아봅시다”로 정정합니다.(김*훈 님)
- (p83) NOTE에 있는 주석 번호 17을 18로 바꾸고 다음 주석을 페이지 아래 추가합니다. “18 옮긴이_ IPython kernel 4.4.0부터는 %matplotlib inline 매직 명령을 사용하지 않더라도 맷플롯립 1.5 이상에서는 자동으로 주피터 자체 백엔드로 설정됩니다.”(정*호 님)
- (p219) 주석 17번에서 “초평면(hyperplaine)”을 “초평면(hyperplane)”으로 정정합니다.(김*훈 님)
- (p275) 위에서 9번째 줄에서 “평균 거리는 약 428.25″를 “평균 거리는 약 408.25″로 정정합니다.
- (p64) 위에서 3번째 줄에서 “웹 사진과 모바일 앱 사진과 데이터가 불일치하지 때문인지”를 “웹 사진과 모바일 앱 사진의 데이터가 불일치하기 때문인지”로 정정합니다.(한*규 님)
- (p916) 첫 번째 문장에 있는 괄호 안에서 “여러 개의 레코드를 추출할 때는 추출할 원소의 개수를 지정해야 합니다”를 “후자의 경우 큐를 만들 때 추출할 원소의 개수를 지정해야 합니다”로 정정합니다.
- (p373) 두 번째 목록의 두 번째 줄에서
X.reshape(-1, 1)을X.reshape(-1, 28*28)로 정정합니다. - (p377) NOTE 블럭 아래 6번째 줄에서 “(하나 또는 그 이상의 이진 레이블을 가진) 이진 분류를 수행한다면”을 “이진 분류나 다중 레이블 이진 분류를 수행한다면”으로 수정합니다.
- (p454) 첫 번째 코드 블럭 바로 아래 “
training=True로 지정하여Dropout층을 활성화하고 테스트 세트에서 100번의 예측을 만들어 쌓습니다. 드롭아웃이 활성화되었기 때문에 예측이 모두 달라집니다.predict()메서드는 샘플이 행이고 클래스가 열로 이루어진 행렬을 반환합니다.“를 “model(X)는 넘파이 배열이 아니라 텐서를 반환한다는 것만 빼고는model.predict(X)와 비슷하고training매개변수를 지원합니다. 이 코드 예에서training=True로 지정하여Dropout층이 활성화되기 때문에 예측이 달라집니다. 테스트 세트에서 100개의 예측을 만들어 쌓았습니다. 모델을 호출할 때마다 샘플이 행이고 클래스마나 하나의 열을 가진 행렬이 반환됩니다.“로 수정합니다. - (p494) 목록 바로 아래 첫 번째 문장 “옵티마이저의
clipnorm이나clipvalue하이퍼파라미터를 지정하면 가중치를 자동으로 클리핑해줍니다“를 “만약 그레이디언트 클리핑(11장 참조)을 하고 싶다면clipnorm이나clipvalue하이퍼파라미터를 지정하세요“로 수정합니다. - (p740) 식 18-1에서
를
으로 정정합니다.
- (p663) 첫 번째 문단 마지막 줄에서 “p=25와 (x 표시된) p=35 위치를”를 “p=22와 (x 표시된) p=35 위치를”로 정정합니다.
- (p317) 9.1.4절 아래 첫 번째 문장에서 “군집은 차원 축소에 효과적인 방법입니다. 특히 지도 학습 알고리즘을”을 “군집은 지도 학습 알고리즘을”로 수정합니다.
- (p319) 첫 번째 문장에서 “하지만 클러스터 개수 k를”을 “클러스터 개수 k를”로 수정합니다.
- (p319) 첫 번째 문단 앞에 새로운 문단을 추가합니다. “군집이 데이터셋의 차원을 (64에서 50으로) 감소시켰지만 성능 향상은 대부분 변환된 데이터셋이 원본 데이터셋보다 선형적으로 더 잘 구분할 수 있기 때문입니다. 따라서 로지스틱 회귀를 사용하기에 더 좋습니다.“
- (p291) 사이킷런 0.23 버전에서
KernelPCA의inverse_transform메서드에 있는 버그가 수정되었습니다. 따라서 이전 버전에서 만든 재구성 원상은 잘못된 그림입니다. 그림 8-11에 있는 왼쪽 아래 그림을 다음 그림으로 교체해주세요(주피터 노트북 In[59] 셀 참조).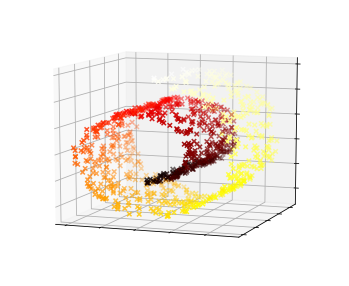
- (p326) 위에서 2번째 줄에 “열을 k 개 가진 행렬”을 “k 개 열을 가진 행렬”로 수정합니다.
- (p391) 48번 주석을 다음과 같이 바꿉니다. “옮긴이_ save() 메서드는 기본적으로 SavedModel 포맷으로 저장합니다. 파일의 확장자가 ‘.h5’이거나 save_format 매개변수를 ‘h5’로 지정하면 HDF5 포맷을 사용합니다.”
- (p845) 연습문제 18번 6번째 줄에서 “개발 세트에서 성능이 나쁘다면”을 “검증 세트에서 성능이 나쁘다면”으로 정정합니다.(김*훈 님)
- (p294) 위에서 3번째 줄에서 “더 구체적 말하면”을 “더 구체적으로 말하면”으로 수정합니다.(김*훈 님)
- (p850) 2번 문제에 대한 답변의 마지막 줄에서
를
로 수정합니다.(김*훈 님)
- (p43) 1.4.2절 아래 첫 번째 문장에서 “입력 데이터의 스트림stream부터”를 “입력 데이터의 스트림stream으로부터”로 수정합니다.(김*훈 님)
- (p100) 두 번째 문단 끝에 다음처럼 주석을 추가합니다. “…
SimpleImputer의 객체를 생성합니다.<주석>옮긴이_ 사이킷런 0.22버전에서 최근접 이웃 방식으로 누락된 값을 대체하는KNNImputer클래스가 추가되었습니다.</주석>” - (p109) 첫 번째 문단 끝에 다음처럼 주석을 추가합니다. “… 변환을 적용해보겠습니다.<주석>옮긴이_ 사이킷런 0.22버전에서 열 이름이나 데이터 타입을 기반으로 열을 선택할 수 있는
make_column_selector()함수가 추가되었습니다.</주석>” - (p118) 54번 주석 끝에 다음 문장을 추가합니다. “사이킷런 0.24버전에서 파라미터 탐색 범위를 좁혀가면서 컴퓨팅 자원을 늘려가는
HalvingGridSearchCV와HalvingRandomSearchCV가 추가됩니다. 이 예제는https://bit.ly/halving-grid-search를 참고하세요.” - (p128) 첫 번째 문장 끝에 다음처럼 주석을 추가합니다. “… 구조를 가지고 있습니다.<주석>옮긴이_ 사이킷런 0.22버전에서
fetch_openml()함수에as_frame매개변수가 추가되었습니다. 이 매개변수를True로 설정하면 판다스 데이터프레임을 반환합니다.</주석>” - (p140) 6번 주석 끝에 다음 문장을 추가합니다. “사이킷런 0.22버전에서 정밀도/재현율 곡선을 그려주는
plot_precision_recall_curve()함수가 추가되었습니다.” - (p142) 첫 번째 문장 끝에 다음처럼 주석을 추가합니다. “… 그래프를 그립니다.<주석>옮긴이_ 사이킷런 0.22버전에서 ROC 곡선을 그려주는
plot_roc_curve()함수가 추가되었습니다.</주석>” - (p149) 첫 번째 문장 끝에 다음처럼 주석을 추가합니다. “… 편리할 때가 많습니다.<주석>옮긴이_ 사이킷런 0.22버전에서 오차 행렬을 그래프로 그려주는
plot_confusion_matrix()함수가 추가되었습니다.</주석>” - (p188) 첫 번째 문단 2번째 줄에서 “2차방정식처럼 보이며 거의 선형적입니다“를 “3차방정식처럼 보입니다“로 정정합니다.
- (p230) 1번 주석 끝에 다음 문장을 추가합니다. “사이킷런 0.21버전에서 dot 파일을 만들지 않고 바로 트리를 그릴 수 있는
plot_tree()함수도 추가되었습니다.” - (p236) 5번 주석을 다음과 같이 바꿉니다. “옮긴이_ 사이킷런 0.21버전에서 히스토그램 기반 그레이디언트 부스팅이 추가되었고
presort매개변수로 얻을 수 있는 성능 향상이 크지 않기 때문에 사이킷런 0.24버전에서 결정 트리와 그레이디언트 부스팅 클래스의presort매개변수가 삭제됩니다.” - (p238) 9번 주석에서 “…
min_impurity_decrease와 분할 대상이 되기 위해 …min_impurity_split가 추가되었습니다“를 “…min_impurity_decrease가 추가되었습니다. 분할 대상이 되기 위해 …min_impurity_split는 0.25버전에서 삭제됩니다“로 수정합니다. 또 10번 주석 끝에서 “… 지원합니다“를 “… 지원했지만 0.22버전에서 비용 복잡도 기반의 사후 가지치기를 위한 ccp_alpha 매개변수가 결정 트리와 트리 기반의 앙상블 모델에 추가되었습니다“로 수정합니다. - (p254) 7.4절 아래 두 번째 문장 끝에 다음처럼 주석을 추가합니다. “… 크기로 지정합니다.<주석>옮긴이_ 사이킷런 0.22버전에서 랜덤 포레스트 클래스에 부트스트랩 샘플 크기를 지정할 수 있는
max_samples매개변수가 추가되었습니다. 샘플 크기를 정수로 입력하거나 비율을 실수로 지정할 수 있습니다. 기본값은 훈련 세트 전체 크기입니다.<주석>” - (p262) 7.5.2절에서 두 번째 문단, 첫 번째 줄에서 “그레이디언트 부스팅은 회귀 문제에도 아주 잘 작동합니다”를 “그레이디언트 부스팅은 분류 문제에도 아주 잘 작동합니다”로 정정합니다.
- (p266) 첫 번째 문단 끝에 다음처럼 주석을 추가합니다. “… 훈련을 멈춥니다.<주석>옮긴이_ 사이킷런 0.20버전에서 그래디언트 부스팅에 조기 종료 기능이 추가되었습니다. 훈련 데이터에서
validation_fraction비율(기본값 0.1)만큼 떼어 내어 측정한 손실이n_iter_no_change반복 동안에tol값(기본값 1e-4) 이상 향상되지 않으면 훈련이 멈춥니다.</주석>” - (p267) 두 번째 문단 끝에 다음처럼 주석을 추가합니다. “… 매우 비슷합니다.<주석>옮긴이_ 이외에도 히스토그램 기반 그레이디언트 부스팅을 구현한 LightGBM(https://lightgbm.readthedocs.io)이 있습니다. 사이킷런 0.21버전에서 히스토그램 기반 그레이디언트 부스팅을 구현한
HistGradientBoostingClassifier와HistGradientBoostingRegressor가 추가되었습니다.</주석>” - (p271) 첫 번째 문장 끝에서 다음처럼 주석을 추가합니다. “… 지원하지 않습니다.<주석>옮긴이_ 사이킷런 0.22버전에서
StackingClassifier와StackingRegressor가 추가되었습니다.</주석>” - (p319) 9.1.5절 아래 첫 번째 문단 끝에 다음처럼 주석을 추가합니다. “… 훈련해보겠습니다.<주석>옮긴이_ 사이킷런 0.24버전에서 준지도 학습을 위한
SelfTrainingClassifier가 추가됩니다.</주석>” - (p358) 첫 번째 문단 끝에서 “… 다중 출력 분류기multioutput classifier입니다.”를 “… 다중 레이블 분류기multilabel classifier입니다.”로 정정합니다.
- (p380) 아래에서 두 번째 문단 끝에서 “(89% 검증 정확도에 가까이 도달할 것입니다)”를 “(89.4% 검증 정확도에 가까이 도달할 것입니다)”로 수정합니다.
- (p405) 페이지 끝에 다음처럼 주석을 추가합니다. “… 배치 크기를 사용해보세요.<주석>옮긴이_ 텐서플로 2.4버전에서 케라스 모델의
compile()메서드에 있는steps_per_execution매개변수를 1이상으로 설정하면 계산 그래프를 한 번 실행할 때 여러 배치를 처리할 수 있기 때문에 GPU를 최대로 활용하고 배치 크기를 바꾸지 않고 훈련 속도를 높일 수 있습니다.</주석>” - (p408) 6번 문제 두 번째와 세 번째 항목에서 “가중치 벡터“를 “가중치 행렬“로 정정합니다.
- (p465) 12.2절 아래 첫 번째 문단 끝에 다음처럼 주석을 추가합니다. “… 방법을 알아봅니다.<주석>옮긴이_ 텐서플로 2.4버전에서 넘파이 호환 API인
tf.experimental.numpy가 추가되었습니다.</주석>” - (p475) 첫 번째 코드 블럭에서
my_softplus함수 옆의 주석을 “# tf.nn.softplus(z)와 반환값이 같습니다.“에서 “# tf.nn.softplus(z)가 큰 입력을 더 잘 다룹니다.“로 수정합니다. - (p492) 22번 주석 끝에 다음 문장을 추가합니다. “이 예는 번역서 깃허브에 있는
custom_model_in_keras.ipynb주피터 노트북을 참고하세요.” - (p531) 13.3.3절 아래 첫 번째 문장 끝에 다음처럼 주석을 추가합니다. “… 노력하고 있습니다.<주석>옮긴이_
tf.keras.layers.experimental.preprocessing아래 이미지 처리, 이미지 증식, 범주형 데이터에 관련된 전처리 층이 추가되었습니다.</주석>” - (p633) 첫 번째 문단 마지막 부분에 “타깃(마지막 글자)를 분리하겠습니다”를 “타깃(마지막 100개의 글자)를 분리하겠습니다”로 정정합니다.
- (p662) [식 16-2] 위 두 번째 줄에서 “아래쪽에 (전치되어) 표현되어 있습니다”를 “위쪽에 (전치되어) 표현되어 있습니다”로 정정합니다.
- (p663) 위에서 네 번째 줄에서 “왼쪽 아래 수직 점선으로”를 “왼쪽 위 수직 점선으로”로 정정합니다.
- (p711) [그림 17-19] 위의 “예를 들어 생성자의 출력을 ~ 풀링 층이 뒤따릅니다).” 문단을 다음 문단으로 교체합니다.
“예를 들어 생성자의 출력을 4 × 4에서 8 × 8로 크게하려면(그림 17-19) 기존 합성곱 층(“합성곱 층 1”)에 (최근접 이웃 필터링을 사용한27) 업샘플링 층을 추가하여 8 × 8 크기 특성 맵을 출력합니다. 이 특성 맵이 새로운 합성곱 층(“합성곱 층 2”)으로 주입되고 다시 새로운 출력 합성곱 층으로 주입됩니다. “합성곱 층 1”의 훈련된 가중치를 잃지 않기 위해 ([그림 17-19]에 점선으로 표시된) 두 개의 새로운 합성곱 층을 점진적으로 페이드-인fade-in하고 원래 출력층을 페이드-아웃fade-out합니다. 이렇게 하기위해 새로운 출력(가중치 α)과 원래 출력(가중치 1 – α)의 가중치 합으로 최종 출력을 만듭니다. 비슷한 페이드-인fade-in/페이드-아웃fade-out 기법이 판별자에 새로운 합성곱 층을 추가할 때 사용됩니다(다운샘플링을 위해 평균 풀링 층이 뒤따릅니다). 모든 합성곱 층은 “same” 스트라이드 1을 사용하므로 입력의 높이와 너비를 보존합니다. 원래 합성곱 층도 마찬가지입니다. 따라서 (입력이 8 × 8이기 때문에) 8 × 8 출력을 만듭니다. 마지막으로 출력층의 커널 크기는 1입니다. 이를 사용해 입력을 필요한 컬러 채널 수 (일반적으로 3)로 투영합니다.” - (p756) 위에서 3번째 줄에 “오차는 전이 (s, r, s’)가 매우 놀랍다는”를 오차는 전이 (s, a, s’)가 매우 놀랍다는”로 정정합니다.
- (p811) 주석 16번 끝에 다음 문장을 추가합니다. “텐서플로 2.4에서 GPU 메모리 사용량을 반환하는
tf.config.experimental.get_memory_usage()함수가 추가되었습니다.” - (p834) 첫 번째 문단 끝에 다음처럼 주석을 추가합니다. “… 훈련 코드를 실행합니다.<주석>옮긴이_
MultiWorkerMirroredStrategy는 텐서플로 2.4에서experimental을 벗어나 안정 API가 됩니다.</주석>” 또한 마지막 문단, 마지막 문장 끝에 다음처럼 주석을 추가합니다. “… 생성자에 전달하세요.<주석>옮긴이_ 텐서플로 2.4에서CollectiveCommunication클래스의 이름이CommunicationImplementation로 바뀝니다.</주석> - (p835) 두 번째 문단 끝에 다음처럼 주석을 추가합니다. “… 전략과 동일합니다).<주석>옮긴이_
TPUStrategy는 텐서플로 2.3에서experimental을 벗어나 안정 API가 되었습니다.</주석> - (p849) 7번 문제 답의 마지막 항목에서 “
는
의 오른쪽에서
단위 행렬
이 추가되고 … 채워진 행렬입니다.”를 “
이 추가되고 … 채워진 행렬입니다(
을
으로 정정합니다.
- (p857) 6번 문제 답에서 2번째, 3번째 항목에 “가중치 벡터“를 “가중치 행렬“로 정정합니다.
- (p889) [식 C-4]의 우변의 두 항의 순서를 다음과 같이 바꿉니다.
그리고 [식 C-4] 아래 “여기서일 때”를 “여기서
일 때”로 정정합니다.
[식 C-4] 다음 문장에서 “이 함수를 최소화하고 …인 벡터 …”를 “이 함수를 최대화하고 …
인 벡터 …”로 정정합니다.
또한 [식 C-5] 아래에 “여기에서는 서포트 벡터의 개수입니다” 문장을 추가합니다.
- (p917) 첫 번째 문장 끝에 다음처럼 주석을 추가합니다. “… 그래프를 살펴보겠습니다.<주석>옮긴이_ 이 부록의 코드는 12장의 주피터 노트북에 포함되어 있습니다.</주석>”
- (p138) (3쇄, 4쇄) 첫 번째 코드 블럭의 아래 두 번째 줄과 세 번째 줄 사이에 다음과 같이 코드를 추가합니다.
>>> threshold = 0
>>> y_some_digit_pred = (y_scores > threshold)
>>> y_some_digit_pred
array([ True ]) - (p247) 주석 1번에서의 이항 계수 공식이 잘못 쓰여져 있습니다.
를
로 정정하고
를
로 정정합니다.(박*하 님)
- (p313) 마지막에서 2번째 줄에 “이 클러스에 포함된”을 “이 클러스터에 포함된”으로 정정합니다.(이*은 님)
- (p756) 위에서 9번째 줄에 “
이면 균등하게 샘플링하고
이면 완전한 중요도 샘플링입니다”로 정정합니다.(신*근 님)
- (p415) 첫 번째 코드 블럭 바로 아래 문장에서 “
대신
기반의 균등분포”를 “
기반의 균등분포”로 정정합니다.(함*정 님)
- (p255) 7.4.1절 위 코드에서
DecisionTreeClassifier(max_features="auto", max_leaf_nodes=16, n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1)을DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16, n_estimators=500)로 정정합니다. - (p424) 마지막 코드 블럭 위 문장 끝에 주석을 추가합니다. “<주석>옮긴이_
updates속성은 향후 삭제될 예정입니다.</주석>” - (p749) 가운데 코드 블럭
epsilon_greedy_policy함수에서np.random.randint(2)를np.random.randint(n_outputs)로 수정합니다. - (p192,193) 192페이지 코드 블럭 1번째 줄에서
from sklearn.base import clone을from copy import deepcopy로 수정합니다. 193페이지 코드 블럭 마지막 줄에서best_model = clone(sgd_reg)를best_model = deepcopy(sgd_reg)로 수정합니다. - (p206) 그림 5-2에서 오른쪽 그래프의 x 축 이름을
에서
으로 수정합니다.
- (p240) 식 6-4의 2번째 줄에서
를
로 수정합니다.
- (p635) 2번째 코드 블럭의 2번째 줄에서
Y_pred = model.predict_classes(X_new)를Y_pred = np.argmax(model(X_new), axis=-1)로 수정합니다. - (p636) 1번째 코드 블럭의 1번째 줄에서
y_proba = model.predict(X_new)[0, -1:, :]를y_proba = model(X_new)[0, -1:, :]로 수정합니다. - (p750) 3번째 코드 블럭의 3번째 줄에서
lr=1e-3을lr=1e-2로 수정합니다. - (p548) 아래에서 6번째 줄에 “
에서
까지”를 “
에서
까지”로 정정합니다.
- (p128) 위에서 두 번째 줄에
fetch_openml('mnist_784', version=1)을fetch_openml('mnist_784', version=1, as_frame=False)로 수정합니다. 2번 주석 끝에 ‘0.24버전에서as_frame매개변수의 기본값이False에서'auto'로 바뀌어 기본적으로 판다스 데이터프레임이 반환됩니다’를 추가합니다. - (p255) (5쇄) 위에서 7번째 줄에 있는 코드 블럭에서
DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16, n_estimators=500)을DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16), n_estimators=500)로 정정합니다.(김*태 님) - (p647) 첫 번째 코드 블럭에서
https://tfhub.dev/google/tf2-preview/nnlm-en-dim50/1를https://tfhub.dev/google/nnlm-en-dim50/2로 수정합니다. - (p377, 387, 396, 398, 431, 436, 437, 440, 441, 446, 493, 582, 613, 676, 679, 736, 750, 769) 옵티마이저의
lr매개변수를 deprecated 경고를 피하기 위해learning_rate으로 수정합니다. - (p418) 위에서 3번째 줄에 “ELU가 수렴할 값을“을 “ELU가 수렴할 값의 역수를“로 정정합니다.
- (p357) 그림 10-4에서
를
로 수정합니다.(M*Kim 님)
- (p363) 위에서 3번째 줄에 “미니 매치에 있는”을 “미니 배치에 있는”으로 정정합니다.(M*Kim 님)
- (p197) 넘파이 1.20버전부터
np.int가 deprecated 되었기 때문에 첫 번째 코드 블럭의 마지막 줄에서astype(np.int)를astype(int)로 수정합니다. - (p179) 사이킷런 1.0에서
get_feature_names()메서드를 가진 변환기에get_feature_names_out()메서드가 추가되었고get_feature_names()는 deprecated 되어 1.2 버전에서 삭제될 예정입니다. 따라서 23번 주석에서get_feature_names()를get_feature_names_out()으로 수정합니다. - (p282) 위에서 9번째 줄에 “두 화살표가 놓인 평면에 수직 축입니다“를 “두 화살표가 놓인 평면 위에 있으며 서로 직교합니다“로 정정합니다.(배*철 님)
- (p38) 아래에서 11번째 줄에 “이상치 탐지와 특이치 탐지” 항목을 한 수준 위로 높입니다.(이*철 님)
- (p310) 위에서 7번째 줄에 “증가함에 따라 더 커지는 것을”을 “증가함에 따라 차이가 더 커지는 것을”로 수정합니다.(배*철 님)
- (p90) 주석 27번에서 “호출된 데이터프레임 자체를 수정하고“를 “호출된 객체에 새로운 데이터프레임을 재할당하고“로 정정합니다.
- (p307) 마지막 줄에서 “평균 제곱 거리이며”를 “제곱 거리 합이며”로 정정합니다.
- (p169) 13번 주석 첫 번째 줄에서 “X는 샘플 수 m, 특성 수 n인”을 “(편의상 편향을 제외하고) X는 샘플 수 m, 특성 수 n인”로 수정합니다.(조*철 님)
- (p850) 5번 문제의 답에서
을
으로,
을
으로 수정합니다.(박*훈 님)
- (p454) 아래에서 8번째 줄에 “클래스마나 하나의 열을 가진”을 “클래스마다 하나의 열을 가진”으로 정정합니다.(김*수 님)
- (p137) 첫 번째 줄에서 “정확도가 30%만 되더라도”를 “정밀도가 30%만 되더라도”로 정정합니다.(이*영 님)
- (p767) 아래에서 다섯 번째 줄에서 “두 번째는 8×8 필터 32개와 스트라이드 2, 세 번째는 8×8 필터 32개와 스트라이드 1을 사용합니다”를 “두 번째는 4×4 필터 64개와 스트라이드 2, 세 번째는 3×3 필터 64개와 스트라이드 1을 사용합니다”로 정정합니다.(오*택 님)
- (p601) 15.1.2절 아래 1번째 문장에서 “출력 시퀀스 만들 수 있습니다”를 “출력 시퀀스를 만들 수 있습니다”로 정정합니다.(이*재 님)
- (p914) 아래에서 10째줄에
b = tf.constant([[5, 6, 9, 11], [13, 0, 0, 0, 0]])를b = tf.constant([[5, 6, 9, 11], [13, 0, 0, 0]])로 정정합니다.(오*택 님) - (p208) 첫 번째 코드 블록 아래 1번째 줄에 “오른쪽 그래프가 이 코드로”를 “왼쪽 그래프가 이 코드로”로 수정합니다.(배*철 님)
- (p192)
SGDRegressor의tol매개변수 값을-np.infty에서None으로 수정합니다. - (p95) 아래에서 3번째 줄에서 “숫자형 특성이 11개 이므로 총
개의 그래프가 되어”를 “숫자형 특성이 9개 이므로 총
개의 그래프가 되어”로 정정합니다.
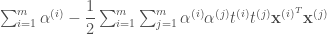
Your Inputs

sklearn stacking regressor를 이용해서 모델구성 중입니다. 혹시 sklearn 모델에서 train, test, vaildation의 각각의 평가점수와 모델에 사용된 feature를 뽑아내서 한꺼번에 저장하려하는데 알려주실수 있으신가요?
좋아요좋아요
안녕하세요. 그리드 서치 클래스의 객체에서 train/validation 점수를 얻을 수 있고 스태킹 객체의 estimators_ 속성에서 각 모델에 접근하실 수 있습니다. 감사합니다.
좋아요좋아요
안녕하세요. 도움이 필요해서 댓글남깁니다.
우선 제가 진행하고 있는 stacking regressor 관련질문입니다.
stacking 진행시에 만약 weak_model1, weak_model2, weak_model3 3개의 모델이 있고, 최종 meta_model이 있을때 기존의 데이터 셋을 이용하여 먼저 weak_model을 학습시킬때 sklearn에서 각각의 weak_model1,2,3에 대해서 feature를 지정할수 있는지, 안된다면 처음 데이터 셋의 feature를 같이 공유해서 사용하는지 궁금합니다. 3주째 교수님이 그럴리가 없다고(개별 feature를 지정) 하는데 이제 제가 맞는지 틀린지도 모르겠어서 정말 마지막 확인차 댓글을 남깁니다. 제 생각에는 처음 데이터 셋의 feature를 같이 공유해서 사용해서 각각의 weak_model들이 선택해서 진행하는 것으로 판단이 되는데 제가 근거를 제시를 못해서 몇주째 제자리걸음 입니다..
좋아요좋아요
안녕하세요. 많은 앙상블 모델이 샘플이나 특성을 무작위로 선택하여 사용합니다. 스태킹처럼 아예 다른 종류의 학습기를 사용하기도 하죠. 각 서브 모델이 전체 특성을 사용할지 서로 다른 특성을 사용할지는 선택의 문제이고 어느 것이 더 높은 성능을 낼지는 사전에 알 수 없습니다. 예를 들어 랜덤 포레스트는 랜덤하게 선택한 샘플과 특성을 사용해 훈련한 결정 트리를 사용합니다.
죄송하지만 제가 개인적인 연구 주제에 대해 의견을 드리기는 어렵습니다. 교수님의 의견에 대한 더 자세한 논의가 필요하다면 학과 동료들이나 인터넷 포럼에 문의 부탁드립니다. 감사합니다.
좋아요좋아요
각 서브 모델이 전체 특성을 사용할지 서로 다른 특성을 사용할지는 선택의 문제이고 어느 것이 더 높은 성능을 낼지는 사전에 알 수 없습니다. -> 이 부분이 제가 생각이 좁았습니다 . 개별적인 문제를 질문해서 죄송합니다. 화학에다 머신러닝을 합지다 하다보니 제가 찾아봤어야 했는데 아직 부족하네요. 다음 번 질문 때는 정말 머신러닝 부분만 질문하도록 하겠습니다. 다시 한번 죄송합니다
좋아요Liked by 1명
안녕하세요 2판 5쇄 읽고 있습니다.
356, 357쪽에 나와 있는 z 값이 서로 다르게 나와있어요.
356쪽에는 z= xTw, 357 그림 10-4에는 wTx로 나와있네요. 값은 같겠지만요ㅎㅎ
좋아요Liked by 1명
p363 3째줄 미니매치 > 미니배치도 부탁드립니다
좋아요Liked by 1명
아이고 실수가 있었네요. 에러타를 찾아 주셔서 감사합니다! 🙂
좋아요좋아요
앗. 그러네요. 특별히 저자가 의도를 가지고 다르게 한 것 같지 않습니다. 그림 10-4의 식을 x^T w로 바꾸어 주세요.
좋아요좋아요
이 책과 제공해주신 노트북을 보면서 정말 재밌게 공부하고 있습니다.
다만,,책이 넘나 두꺼워서.. 차라리 두 권으로 구성되면 좋았지 않을까 싶습니다.
좋아요Liked by 1명
안녕하세요. 좋은 의견 감사드립니다. 다음 번에는 출판사와 두 권으로 나누는 것에 대해 의논해 보겠습니다. ^^
좋아요좋아요
p.158에서 주피터 노트북으로 만든 선형대수와 미분에 대한 기초 튜토리얼이 깃허브에 있다는데 못 찾겠습니다.
좋아요좋아요
math_linear_algebra.ipynb 와 math_differential_calculus.ipynb 입니다. 감사합니다!
좋아요좋아요
추가적으로 eta가 정확히 무엇인지 잘 모르겠습니다
좋아요좋아요
학습률은 learning rate로 알고 있는데 eta와 동일한 의미인가요?
좋아요Liked by 1명
eta를 학습률로 사용하는 경우도 있지만 절대적인 것은 아닙니다. 어떤 의미인지 알려면 관련 문서나 논문을 참고해 보세요. 감사합니다.
좋아요좋아요
https://github.com/rickiepark/handson-ml2/blob/master/10_neural_nets_with_keras.ipynb
p.399
param_distribs 부분 관련해서 “learning_rate is not a legal parameter” 오류가 나서
“learning_rate”: reciprocal(3e-4, 3e-2) 부분을 “lr”: reciprocal(3e-4, 3e-2) 로 고쳐서 실행 성공했습니다.
좋아요좋아요
실행 버전은
tensorflow 2.3.0
keras 2.4.0 입니다.
좋아요좋아요
안녕하세요. 깃허브 코드를 실행하실 때는 텐서플로 최신 버전을 사용해 주세요. 이전 버전을 사용하신다면 108번 항목을 참고해 주세요. 감사합니다.
좋아요좋아요
안녕하세요
914페이지 여러 쌍의 합집합 계산 코드에서 b의 두번째 원소에서 0이 하나 빠져야 될 거 같습니다.
수정 전: b = tf.constant([[5, 6, 9, 11], [13, 0, 0, 0, 0]])
수정 후: b = tf.constant([[5, 6, 9, 11], [13, 0, 0, 0]])
좋은 번역 해주셔서 항상 감사드립니다
좋아요Liked by 1명
아이쿠, 그렇네요. 알려 주셔서 감사합니다!
좋아요좋아요
안녕하세요 2판
p759에서 env=suite_gym.load(‘Breakout-v4’) 시 실행이 안됩니다. 현재 모듈들의 버전이 바뀌어서 그런지는 모르겠지만, colab과 jupyter-notebook에서 둘다 같은 오류를 보이네요.(저만의 문제인지 잘 모르겠습니다.)
시행착오를 거쳐서 일반적인 방법이 아니라 다른 방법을 통해 모듈 import까지 제대로 되어 env=suite_gym.load(‘Breakout-v4’) 실행이 잘 되긴 했는데
p760 에 env.reset() 시 오류가 납니다.
setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (2,) + inhomogeneous part.
env=suite_gym.load(‘Breakout-v4’) 을 하면서 env의 데이터 크기가 바뀐 것 같은데요.
개인적인 생각으로는 모듈들의 버전이 바뀌면서 제대로 시행되지 않는 것 같습니다. 확인 부탁드립니다.
좋아요좋아요
안녕하세요. 박해선입니다. gym 버전과 호환성 문제가 있는 것 같습니다. 저는 코랩에서 다음과 같이 설치하여 18장 노트북을 실행했습니다.
%pip install -U tf-agents==0.13.0 pyvirtualdisplay
%pip install -U gym~=0.21.0
%pip install -U gym[box2d,atari,accept-rom-license]
%pip install pyglet==1.5.27
자세한 내용은 18장 주피터 노트북을 참고하세요.
https://github.com/rickiepark/handson-ml2/blob/master/18_reinforcement_learning.ipynb
감사합니다!
좋아요좋아요
안녕하세요.
208페이지 중간 “[그림 5-4]의 오른쪽 그래프가 이 코드로 만들어진 것입니다.”라고 되어있는데 C 값이 1로 설정된것으로 봐서는 왼쪽 그래프가 맞는거 아닌가해서 문의드립니다.
좋아요좋아요
앗 그렇네요. 알려 주셔서 감사합니다!
좋아요좋아요
저자님 안녕하세요.
95쪽 맨 아래 코드블록 윗 단락 2번째 줄이
“… 숫자형 특성이 11개이므로 …” 라고 기술돼 있는데,
`housing` 데이터셋은 총 특성 수 10개, 숫자형 특성 수 9개가 아닌가 하여 글을 남깁니다.
감사합니다.
좋아요좋아요
앗, 그러네요. 아마도 나중에 3개의 특성을 만들어 추가하는데 이때는 11개가 됩니다. 저자가 혼동을 한 것 같으네요. 해당 문장을 다음과 같이 바꾸어 주세요. “숫자형 특성이 9개 이므로 총 9^2=81개의 그래프가 되어” 감사합니다!
좋아요좋아요
저자님 안녕하세요, 혹시 핸즈온 머신러닝 3판에 대한 번역본 출간이 계획에 있으신지 궁금합니다! 만일 있으시다면 언제쯤 출간될까요?
좋아요좋아요
안녕하세요. 핸즈온 3판을 지금 작업하고 있지만 정확한 출간 일정을 제가 알긴 어렵습니다. 늦어도 여름 전에는 나오지 않을까 생각됩니다. 감사합니다.
좋아요좋아요