2. 지도 학습 | 목차 | 2.3 지도 학습 알고리즘
–
지도 학습에서는 훈련 데이터로 학습한 모델이 훈련 데이터와 특성이 같다면 처음 보는 새로운 데이터가 주어져도 정확히 예측할 거라 기대합니다. 모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있으면 이를 훈련 세트에서 테스트 세트로 일반화generalization되었다고 합니다. 그래서 모델을 만들 때는 가능한 한 정확하게 일반화되도록 해야 합니다.
보통 훈련 세트에 대해 정확히 예측하도록 모델을 구축합니다. 훈련 세트와 테스트 세트가 매우 비슷하다면 그 모델이 테스트 세트에서도 정확히 예측하리라 기대할 수 있습니다. 그러나 항상 그런 것만은 아닙니다. 예를 들어 아주 복잡한 모델을 만든다면 훈련 세트에만 정확한 모델이 되어버릴 수 있습니다.
가상의 예를 만들어 설명해보겠습니다. 초보 데이터 과학자가 요트를 구매한 고객과 구매 의사가 없는 고객의 데이터를 이용해 누가 요트를 살지 예측하려 합니다. 1 그래서 관심없는 고객들을 성가시게 하지 않고 실제 구매할 것 같은 고객에게만 홍보 메일을 보내는 것이 목표입니다.
고객 데이터는 [표 2-1]과 같습니다.
표 2-1 고객 샘플 데이터
| 나이 | 보유차량수 | 주택보유 | 자녀수 | 혼인상태 | 애완견 | 보트구매 |
| 66 | 1 | yes | 2 | 사별 | no | yes |
| 52 | 2 | yes | 3 | 기혼 | no | yes |
| 22 | 0 | no | 0 | 기혼 | yes | no |
| 25 | 1 | no | 1 | 미혼 | no | no |
| 44 | 0 | no | 2 | 이혼 | yes | no |
| 39 | 1 | yes | 2 | 기혼 | yes | no |
| 26 | 1 | no | 2 | 미혼 | no | no |
| 40 | 3 | yes | 1 | 기혼 | yes | no |
| 53 | 2 | yes | 2 | 이혼 | no | yes |
| 64 | 2 | yes | 3 | 이혼 | no | no |
| 58 | 2 | yes | 2 | 기혼 | yes | yes |
| 33 | 1 | no | 1 | 미혼 | no | no |
초보 데이터 과학자가 데이터를 잠시 보더니 다음과 같은 규칙을 발견했습니다. “45세 이상이고 자녀가 셋 미만이며 이혼하지 않은 고객은 요트를 살 것입니다.” 이 규칙이 얼마나 잘 들어 맞을지 물어보면 초보 데이터 과학자는 “100% 정확해요”라고 대답할 것입니다. 사실 이 표의 데이터로 국한하면 이 규칙이 완벽하게 들어맞습니다. 그런데 이 데이터셋에서 요트를 사려고 하는 사람을 완벽하게 묘사할 수 있는 규칙은 많습니다. 데이터에 같은 나이가 두 번 나타나지 않으므로 66세, 52세, 53세, 58세 고객은 요트를 사려 하고 나머지는 그렇지 않다고 말할 수 있습니다. 이렇게 이 데이터를 만족하는 규칙을 많이 만들 수 있지만, 기억할 것은 우리가 예측하려는 대상은 이 데이터셋이 아니라는 것입니다. 이 고객들에 대한 답은 이미 알고 있습니다. 알고 싶은 것은 “새로운 고객이 요트를 구매할 것인가”입니다. 그러므로 새로운 고객에도 잘 작동하는 규칙을 찾아야 하며 훈련 세트에서 100% 정확도를 달성하는 것은 크게 도움되지 않습니다. 아마도 초보 데이터 과학자가 만든 규칙은 새로운 고객을 대상으로는 잘 작동하지 않을 것 같습니다. 이 모델은 너무 상세하고 너무 적은 데이터에 의존하고 있습니다. 예를 들어 이 규칙에서 이혼하지 않는다는 조건은 단지 한 명에만 적용됩니다.
알고리즘이 새로운 데이터도 잘 처리하는지 측정하는 방법은 테스트 세트로 평가해보는 것밖에 없습니다. 그러나 직관적으로 보더라도 (아마 수학적으로 볼 때도) 간단한 모델이 새로운 데이터에 더 잘 일반화될 것이라고 예상할 수 있습니다. 만약 “50세 이상인 사람은 보트를 사려고 한다”라는 규칙을 만들었다면 이 규칙은 모든 고객 데이터를 만족시킬 뿐 아니라, 나이 외에 자녀 수나 혼인 상태를 추가한 규칙보다 더 신뢰할 수 있습니다. 그렇기 때문에 우리는 언제나 가장 간단한 모델을 찾으려고 합니다. 초보 데이터 과학자가 했던 것처럼 가진 정보를 모두 사용해서 너무 복잡한 모델을 만드는 것을 과대적합overfitting이라고 합니다. 과대적합은 모델이 훈련 세트의 각 샘플에 너무 가깝게 맞춰져서 새로운 데이터에 일반화되기 어려울 때 일어납니다. 반대로 모델이 너무 간단하면, 즉 “집이 있는 사람은 모두 요트를 사려고 한다”와 같은 경우에는 데이터의 면면과 다양성을 잡아내지 못할 것이고 훈련 세트에도 잘 맞지 않을 것입니다. 너무 간단한 모델이 선택되는 것을 과소적합underfitting이라고 합니다.
모델을 복잡하게 할 수록 훈련 데이터에 대해서는 더 정확히 예측할 수 있습니다. 그러나 너무 복잡해지면 훈련 세트의 각 데이터 포인트에 너무 민감해져 새로운 데이터에 잘 일반화되지 못합니다.
우리가 찾으려는 모델은 일반화 성능이 최대가 되는 최적점에 있는 모델입니다.
과대적합과 과소적합의 절충점이 [그림 2-1]에 나타나 있습니다.
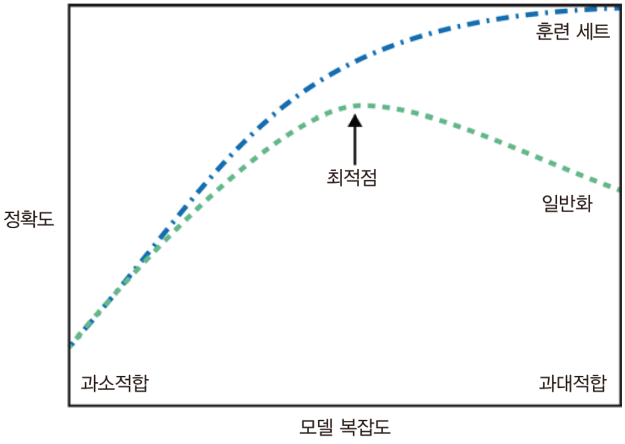
그림 2-1 모델 복잡도에 따른 훈련과 테스트 정확도의 변화
2.2.1 모델 복잡도와 데이터셋 크기의 관계
모델의 복잡도는 훈련 데이터셋에 담긴 입력 데이터의 다양성과 관련이 깊습니다. 데이터셋에 다양한 데이터 포인트가 많을수록 과대적합 없이 더 복잡한 모델을 만들 수 있습니다. 보통 데이터 포인트를 더 많이 모으는 것이 다양성을 키워주므로 큰 데이터셋은 더 복잡한 모델을 만들 수 있게 해줍니다. 그러나 같은 데이터 포인트를 중복하거나 매우 비슷한 데이터를 모으는 것은 도움이 되지 않습니다.
요트 판매 예로 돌아가 보면, 고객 데이터를 10,000개 모아봤더니 전부 “45세 이상이고 자녀가 셋 미만이며 이혼하지 않는 고객은 요트를 사려고 한다”라는 규칙을 만족한다면 [표 2-1]의 12개만 사용할 때보다 훨씬 좋은 규칙이라고 할 수 있습니다.
데이터를 더 많이 수집하고 적절하게 더 복잡한 모델을 만들면 지도 학습 문제에서 종종 놀라운 결과를 얻을 수 있습니다. 이 책에서는 고정 크기의 데이터셋을 사용하는 데 집중하겠습니다. 모델을 변경하거나 조정하는 것보다 이득일 수 있으므로 실제 환경에서는 데이터를 얼마나 많이 모을지 정해야 합니다. 데이터양의 힘을 과소평가하지 마세요.
–
–
–
2. 지도 학습 | 목차 | 2.3 지도 학습 알고리즘

표에는 보트라고 되어있고 글에는 요트라고 되어있는데 같은 대상을 말하는 게 맞나요? 해당 샘플 데이터로부터 이미 보트를 구매한 사람을 가지고 과적합 모델의 예를 든게 맞나요?
좋아요좋아요
앗 표에 보트라고 되어 있군요. ㅜㅜ. 보트가 아니라 요트가 맞습니다. 🙂
좋아요좋아요