2.3 지도 학습 알고리즘 | 목차 | 2.3.3 선형 모델
–
k-NNk-Nearest Neighbors 알고리즘은 가장 간단한 머신러닝 알고리즘입니다. 훈련 데이터셋을 그냥 저장하는 것이 모델을 만드는 과정의 전부입니다. 새로운 데이터 포인트에 대해 예측할 땐 알고리즘이 훈련 데이터셋에서 가장 가까운 데이터 포인트, 즉 ‘최근접 이웃’을 찾습니다.
k-최근접 이웃 분류
가장 간단한 k-NN 알고리즘은 가장 가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측에 사용합니다. 단순히 이 훈련 데이터 포인트의 출력이 예측이 됩니다. [그림 2-4]는 forge 데이터셋을 이렇게 분류한 것입니다.
In[11]:
mglearn.plots.plot_knn_classification(n_neighbors=1)

그림 2-4 forge 데이터셋에 대한 1-최근접 이웃 모델의 예측
이 그림에는 데이터 포인트 3개를 추가했습니다(별 모양으로 표시). 그리고 추가한 각 데이터 포인트에서 가장 가까운 훈련 데이터 포인트를 연결하였습니다. 1-최근접 이웃 알고리즘의 예측은 이 데이터 포인트의 레이블이 됩니다(같은 색으로 연결하였습니다).
가장 가까운 이웃 하나가 아니라 임의의 k개를 선택할 수도 있습니다. 그래서 k-최근접 이웃 알고리즘이라 부릅니다. 둘 이상의 이웃을 선택할 때는 레이블을 정하기 위해 투표를 합니다. 즉 테스트 포인트 하나에 대해 클래스 0에 속한 이웃이 몇 개인지, 그리고 클래스 1에 속한 이웃이 몇 개인지를 셉니다. 그리고 이웃이 더 많은 클래스를 레이블로 지정합니다. 다시 말해 k-최근접 이웃 중 다수의 클래스가 레이블이 됩니다. 다음은 세 개의 최근접 이웃을 사용하는 예입니다(그림 2-5).
In[12]:
mglearn.plots.plot_knn_classification(n_neighbors=3)

그림 2-5 forge 데이터셋에 대한 3-최근접 이웃 모델의 예측
여기에서도 예측은 연결된 데이터 포인트의 색으로 나타납니다. 새 데이터 포인트 중 왼쪽 위의 것은 이웃을 하나만 사용했을 때와 예측이 달라진 것을 알 수 있습니다.
이 그림은 이진 분류 문제지만 클래스가 다수인 데이터셋에도 같은 방법을 적용할 수 있습니다. 클래스가 여러 개일 때도 각 클래스에 속한 이웃이 몇 개인지를 헤아려 가장 많은 클래스를 예측값으로 사용합니다.
이제 scikit-learn을 사용해서 k-최근접 이웃 알고리즘을 어떻게 적용하는지 살펴보겠습니다. 먼저 1장에서 한 것처럼 일반화 성능을 평가할 수 있도록 데이터를 훈련 세트와 테스트 세트로 나눕니다.
In[13]:
from sklearn.model_selection import train_test_split X, y = mglearn.datasets.make_forge() X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
다음은 KNeighborsClassifier를 임포트import하고 객체를 만듭니다. 이때 이웃의 수 같은 매개변수들을 지정합니다. 여기서는 이웃의 수를 3으로 지정합니다.
In[14]:
from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=3)
이제 훈련 세트를 사용하여 분류 모델을 학습시킵니다. KNeighborsClassifier에서의 학습은 예측할 때 이웃을 찾을 수 있도록 데이터를 저장하는 것입니다.
In[15]:
clf.fit(X_train, y_train)
테스트 데이터에 대해 predict 메서드를 호출해서 예측을 합니다. 테스트 세트의 각 데이터 포인트에 대해 훈련 세트에서 가장 가까운 이웃을 계산한 다음 가장 많은 클래스를 찾습니다.
In[16]:
print("테스트 세트 예측: {}".format(clf.predict(X_test)))
Out[16]:
테스트 세트 예측: [1 0 1 0 1 0 0]
모델이 얼마나 잘 일반화되었는지 평가하기 위해 score 메서드에 테스트 데이터와 테스트 레이블을 넣어 호출합니다.
In[17]:
print("테스트 세트 정확도: {:.2f}".format(clf.score(X_test, y_test)))
Out[17]:
테스트 세트 정확도: 0.86
이 모델의 정확도는 86%로 나왔습니다. 즉 모델이 테스트 데이터셋에 있는 샘플 중 86%를 정확히 예측하였습니다.
KNeighborsClassifier 분석
2차원 데이터셋이므로 가능한 모든 테스트 포인트의 예측을 xy 평면에 그려볼 수 있습니다. 그리고 각 데이터 포인트가 속한 클래스에 따라 평면에 색을 칠합니다. 이렇게 하면 알고리즘이 클래스 0과 클래스 1로 지정한 영역으로 나뉘는 결정 경계decision boundary를 볼 수 있습니다. 다음 코드는 이웃이 하나, 셋, 아홉 개일 때의 결정 경계를 보여줍니다.
In[18]:
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n_neighbors, ax in zip([1, 3, 9], axes):
# fit 메서드는 self 객체를 반환합니다.
# 그래서 객체 생성과 fit 메서드를 한 줄에 쓸 수 있습니다.
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5,
ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{} 이웃".format(n_neighbors))
ax.set_xlabel("특성 0")
ax.set_ylabel("특성 1")
axes[0].legend(loc=3)

그림 2-6 n_neighbors 값이 각기 다른 최근접 이웃 모델이 만든 결정 경계
[그림 2-6]의 왼쪽 그림을 보면 이웃을 하나 선택했을 때는 결정 경계가 훈련 데이터에 가깝게 따라가고 있습니다. 이웃의 수를 늘릴수록 결정 경계는 더 부드러워집니다. 부드러운 경계는 더 단순한 모델을 의미합니다. 다시 말해 이웃을 적게 사용하면 모델의 복잡도가 높아지고([그림 2-1]의 오른쪽) 많이 사용하면 복잡도는 낮아집니다([그림 2-1]의 왼쪽). 훈련 데이터 전체 개수를 이웃의 수로 지정하는 극단적인 경우에는 모든 테스트 포인트가 같은 이웃(모든 훈련 데이터)을 가지게 되므로 테스트 포인트에 대한 예측은 모두 같은 값이 됩니다. 즉 훈련 세트에서 가장 많은 데이터 포인트를 가진 클래스가 예측값이 됩니다.
앞서 이야기한 모델의 복잡도와 일반화 사이의 관계를 입증할 수 있는지 살펴보겠습니다. 이를 위해 실제 데이터인 유방암 데이터셋을 사용하겠습니다. 먼저 훈련 세트와 테스트 세트로 나눕니다. 그런 다음 이웃의 수를 달리 하여 훈련 세트와 테스트 세트의 성능을 평가합니다. 결과는 [그림 2-7]과 같습니다.
In[19]:
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=66)
training_accuracy = []
test_accuracy = []
# 1에서 10까지 n_neighbors를 적용
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
# 모델 생성
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
# 훈련 세트 정확도 저장
training_accuracy.append(clf.score(X_train, y_train))
# 일반화 정확도 저장
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label="훈련 정확도")
plt.plot(neighbors_settings, test_accuracy, label="테스트 정확도")
plt.ylabel("정확도")
plt.xlabel("n_neighbors")
plt.legend()

그림 2-7. n_neighbors 변화에 따른 훈련 정확도와 테스트 정확도
이 그림은 n_neighbors 수(x 축)에 따른 훈련 세트와 테스트 세트 정확도(y 축)를 보여줍니다. 실제 이런 그래프는 매끈하게 나오지 않지만, 여기서도 과대적합과 과소적합의 특징을 볼 수 있습니다(이웃의 수가 적을수록 모델이 복잡해지므로 [그림 2-1]의 그래프가 수평으로 뒤집힌 형태입니다). 최근접 이웃의 수가 하나일 때는 훈련 데이터에 대한 예측이 완벽합니다. 하지만 이웃의 수가 늘어나면 모델은 단순해지고 훈련 데이터의 정확도는 줄어듭니다. 이웃을 하나 사용한 테스트 세트의 정확도는 이웃을 많이 사용했을 때보다 낮습니다. 이것은 1-최근접 이웃이 모델을 너무 복잡하게 만든다는 것을 설명해줍니다. 반대로 이웃을 10개 사용했을 때는 모델이 너무 단순해서 정확도는 더 나빠집니다. 정확도가 가장 좋을 때는 중간 정도인 여섯 개를 사용한 경우입니다. 이 그래프의 범위를 눈여겨 보면 가장 나쁜 정확도도 88%여서 수긍할만 합니다.
k-최근접 이웃 회귀
k-최근접 이웃 알고리즘은 회귀 분석에도 쓰입니다. 이번에는 wave 데이터셋을 이용해서 이웃이 하나인 최근접 이웃을 사용해보겠습니다. x 축에 세 개의 테스트 데이터를 녹색 별 모양으로 표시했습니다. 최근접 이웃을 한 개만 이용할 때 예측은 그냥 가장 가까운 이웃의 타깃값입니다. 이 예측은 [그림 2-8]에 파란 별 모양으로 표시하였습니다.
In[20]:
mglearn.plots.plot_knn_regression(n_neighbors=1)
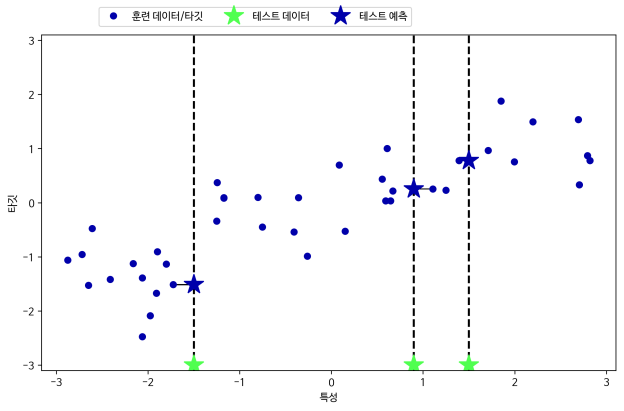
그림 2-8 wave 데이터셋에 대한 1-최근접 이웃 회귀 모델의 예측
여기에서도 이웃을 둘 이상 사용하여 회귀 분석을 할 수 있습니다. 여러 개의 최근접 이웃을 사용할 땐 이웃 간의 평균 1 이 예측이 됩니다(그림 2-9).
In[21]:
mglearn.plots.plot_knn_regression(n_neighbors=3)

그림 2-9 wave 데이터셋에 대한 3-최근접 이웃 회귀 모델의 예측
scikit-learn에서 회귀를 위한 k-최근접 이웃 알고리즘은 KNeighborsRegressor에 구현되어 있습니다. 사용법은 KNeighborsClassifier와 비슷합니다.
In[22]:
from sklearn.neighbors import KNeighborsRegressor X, y = mglearn.datasets.make_wave(n_samples=40) # wave 데이터셋을 훈련 세트와 테스트 세트로 나눕니다. X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) # 이웃의 수를 3으로 하여 모델의 객체를 만듭니다. reg = KNeighborsRegressor(n_neighbors=3) # 훈련 데이터와 타깃을 사용하여 모델을 학습시킵니다. reg.fit(X_train, y_train)
그리고 테스트 세트에 대해 예측을 합니다.
In[23]:
print("테스트 세트 예측:\n{}".format(reg.predict(X_test)))
Out[23]:
테스트 세트 예측: [-0.054 0.357 1.137 -1.894 -1.139 -1.631 0.357 0.912 -0.447 -1.139]
역시 score 메서드를 사용해 모델을 평가할 수 있습니다. 이 메서드는 회귀일 땐 R2 값을 반환합니다. 결정 계수라고도 하는 R2 값은 회귀 모델에서 예측의 적합도를 0과 1 사이의 값으로 계산한 것입니다. 2 1은 예측이 완벽한 경우고, 0은 훈련 세트의 출력값인 y_train의 평균으로만 예측하는 모델의 경우입니다. 3
In[24]:
print("테스트 세트 R^2: {:.2f}".format(reg.score(X_test, y_test)))
Out[24]:
테스트 세트 R^2: 0.83
우리가 얻은 점수는 0.83이라 모델이 비교적 잘 들어맞은 것 같습니다.
KNeighborsRegressor 분석
이 1차원 데이터셋에 대해 가능한 모든 특성 값을 만들어 예측해볼 수 있습니다(그림 2-10). 이를 위해 x 축을 따라 많은 포인트를 생성해 테스트 데이터셋을 만듭니다.
In[25]:
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# -3과 3 사이에 1,000개의 데이터 포인트를 만듭니다.
line = np.linspace(-3, 3, 1000).reshape(-1, 1)
for n_neighbors, ax in zip([1, 3, 9], axes):
# 1, 3, 9 이웃을 사용한 예측을 합니다.
reg = KNeighborsRegressor(n_neighbors=n_neighbors)
reg.fit(X_train, y_train)
ax.plot(line, reg.predict(line))
ax.plot(X_train, y_train, '^', c=mglearn.cm2(0), markersize=8)
ax.plot(X_test, y_test, 'v', c=mglearn.cm2(1), markersize=8)
ax.set_title(
"{} 이웃의 훈련 스코어: {:.2f} 테스트 스코어: {:.2f}".format(
n_neighbors, reg.score(X_train, y_train),
reg.score(X_test, y_test)))
ax.set_xlabel("특성")
ax.set_ylabel("타깃")
axes[0].legend(["모델 예측", "훈련 데이터/타깃", "테스트 데이터/타깃"],
loc="best")

그림 2-10 n_neighbors 값에 따라 최근접 이웃 회귀로 만들어진 예측 비교
이 그림에서 볼 수 있듯이 이웃을 하나만 사용할 때는 훈련 세트의 각 데이터 포인트가 예측에 주는 영향이 커서 예측값이 훈련 데이터 포인트를 모두 지나갑니다. 이는 매우 불안정한 예측을 만들어 냅니다. 이웃을 많이 사용하면 훈련 데이터에는 잘 안 맞을 수 있지만 더 안정된 예측을 얻게 됩니다.
장단점과 매개변수
일반적으로 KNeighbors 분류기에 중요한 매개변수는 두 개입니다. 데이터 포인트 사이의 거리를 재는 방법과 이웃의 수입니다. 실제로 이웃의 수는 3개나 5개 정도로 적을 때 잘 작동하지만, 이 매개변수는 잘 조정해야 합니다. 거리 재는 방법을 고르는 문제는 이 책에서 다루지 않습니다만, 기본적으로 여러 환경에서 잘 동작하는 유클리디안 거리 방식을 사용합니다. 4
k-NN의 장점은 이해하기 매우 쉬운 모델이라는 점입니다. 그리고 많이 조정하지 않아도 자주 좋은 성능을 발휘합니다. 더 복잡한 알고리즘을 적용해보기 전에 시도해볼 수 있는 좋은 시작점입니다. 보통 최근접 이웃 모델은 매우 빠르게 만들 수 있지만, 훈련 세트가 매우 크면 (특성의 수나 샘플의 수가 클 경우) 예측이 느려집니다. k-NN 알고리즘을 사용할 땐 데이터를 전처리하는 과정이 중요합니다(3장 참고). 5 그리고 (수백 개 이상의) 많은 특성을 가진 데이터셋에는 잘 동작하지 않으며, 특성 값 대부분이 0인 (즉 희소한) 데이터셋과는 특히 잘 작동하지 않습니다.
k-최근접 이웃 알고리즘이 이해하긴 쉽지만, 예측이 느리고 많은 특성을 처리하는 능력이 부족해 현업에서는 잘 쓰지 않습니다. 이런 단점이 없는 알고리즘이 다음에 설명할 선형 모델입니다.
–
–
- 옮긴이_ 원문에는 ‘average or mean’ 으로 표현되어 있습니다. KNeighborsRegressor의 weights 매개변수가 기본값 ‘uniform’일 때는 np.mean 함수를 사용하여 단순 평균을 계산하고, ‘distance’일 때는 거리를 고려한 가중치 평균(average)을 계산합니다.
- 옮긴이_ R2을 구하는 공식은
입니다. y는 타깃값이고
는 타깃값의 평균,
은 모델의 예측값입니다.
- 옮긴이_ 무조건 y_train의 평균값을 예측으로 사용하면
의 공식에서
- 옮긴이_ KNeighborsClassifier와 KNeighborsRegressor의 객체를 생성할 때 metric 매개변수를 사용하여 거리 측정 방식을 변경할 수 있습니다. metric 매개변수의 기본값은 민코프스키 거리를 의미하는 ‘minkowski’이며 거듭제곱의 크기를 정하는 매개변수인 p가 기본값 2일 때 유클리디안 거리와 같습니다.
- 옮긴이_ 이웃 간의 거리를 계산할 때 특성마다 값의 범위가 다르면 범위가 작은 특성에 크게 영향을 받습니다. 따라서 k-NN 알고리즘을 사용할 때는 특성들이 같은 스케일을 갖도록 정규화하는 것이 일반적입니다.
—
2.3 지도 학습 알고리즘 | 목차 | 2.3.3 선형 모델
–

책은 흑백으로 되어 있어 그래프를 이해하는데 다소 시간이 걸리네요. Color로 다시 출판하실 계획은 없나요?
좋아요좋아요
출판사의 결정이라서 힘들지 않나 싶습니다. 깃허브 노트북에 있는 이미지를 참고하시면 도움이 되실 것 같습니다. ^^
좋아요좋아요
‘파이썬 라이브러리를 활용한 머신러닝’ 책을 사서 공부중인데
k-NN 알고리즘은 가까운 이웃을 찾아 그 이웃의 클래스로 분류하는 것이라고 이해되는 데,
특성(feature)이 2개인 경우에는 이해가 되는 데, 3개 이상인 경우에는 어떻게 분류하는 지 잘 이해가 되지 않습니다. 예를 들어, iris 붓꽃의 꽃잎과 꽃받침의 폭과 길이 총 4개의 특성이 있을 때 이 특성들의 각각의 조합 ( “꽃잎의 폭과 꽃받침의 폭”, “꽃잎의 길이와 꽃받침의 길이” 등 Scatter Matrix ) 중에서 클래스를 가장 잘 구분하는 조합을 알고리즘이 선택해서 분류하는 것인가요? 아니면 다른 방법이 있는 건가요? 아시는 분 있으면 설명해 주시면 감사하겠습니다.
좋아요좋아요
안녕하세요. k-NN 알고리즘은 기본값에서 이웃과의 유클리디안 거리를 계산하여 가장 가까운 이웃을 찾습니다. 2개 이상의 특성이 있더라도 유클리디안 거리를 계산하는 방식은 동일합니다. 책에서는 그림으로 표현하기 위해서 2차원 특성을 사용했을 뿐입니다. 도움이 되셨는지 모르겠네요. 🙂
좋아요좋아요
유클리디안 거리 방식이란 걸 몰랐습니다…이제야 이해가 되네요…감사합니다.
좋아요Liked by 1명
안녕하세요, matplotlib으로 플롯을 만들때 한글이 깨지는데, 혹시 어떤 설정을 하셨는지 여쭤봐도 될까요? 구글링해보니 매번 그래프에 한글이 나올때마다 fm.FontProperties를 나눔글꼴로 지정해주는 방법은 찾았는데 혹시 주피터 노트북이 실행될 때마다 디폴트 폰트를 나눔으로 설정하는 방법은 없을까요?
좋아요좋아요
matplotlib.rc()로 설정할 수 있습니다. 깃헙의 https://github.com/rickiepark/introduction_to_ml_with_python/blob/master/preamble.py 코드를 참고하세요. 🙂
좋아요좋아요
안녕하세요! 많은 도움이 되는 글입니다!
한가지 궁금한 점이 있는데요.
훈련 데이터셋을 그냥 저장하는 것이 모델을 만드는 과정의 전부라고 하셨는데 그럼 clf.fit(x_train, y_train)이 다른 모델들처럼 모델링을 하는 것이 아니라 그냥 데이터를 저장하는 게 끝인 건가요?
즉 clf.fit이 다른 모델과는 다른 방식으로 작동 되는 것인가요?
감사합니다.
좋아요좋아요
안녕하세요. 클래스마다 fit 메서드의 역할이 조금씩 다를 수 있습니다. 최근접 이웃 모델은 fit 메서드에서 훈련 데이터를 저장하는 것이 전부입니다. 조금 더 자세히 말하면 fit 메서드에서 샘플 사이의 거리를 계산하여 저장합니다. 🙂
좋아요좋아요