1.2 왜 머신러닝을 사용하는가? | 목차 | 1.4 머신러닝의 주요 도전 과제
머신러닝 시스템의 종류는 굉장히 많으므로 다음을 기준으로 넓은 범주에서 분류하면 도움이 됩니다.
- 사람의 감독 하에 훈련하는 것인지 그렇지 않은 것인지(지도, 비지도, 준지도, 강화 학습)
- 실시간으로 점진적인 학습을 하는지 아닌지(온라인 학습과 배치 학습)
- 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 훈련 데이터셋에서 과학자들처럼 패턴을 발견하여 예측 모델을 만드는지(사례 기반 학습과 모델 기반 학습)
이 범주들은 서로 배타적이지 않으며 원하는 대로 연결할 수 있습니다. 예를 들어 최첨단 스팸 필터가 심층 신경망 모델을 사용해 스팸과 스팸이 아닌 메일로부터 실시간으로 학습할 지도 모릅니다. 그렇다면 이 시스템은 온라인이고 모델 기반이며 지도 학습 시스템입니다.
이 범주들을 조금 더 자세히 들여다보겠습니다.
1.3.1 지도 학습과 비지도 학습
머신러닝 시스템을 ‘학습하는 동안의 감독 형태나 정보량’에 따라 분류할 수 있습니다. 지도 학습, 비지도 학습, 준지도 학습, 강화 학습 등 네 가지 주요 범주가 있습니다.
지도 학습
지도 학습supervised learning에는 알고리즘에 주입하는 훈련 데이터에 레이블label 3이라는 원하는 답이 포함됩니다(그림 1-5).

분류classification가 전형적인 지도 학습 작업이며, 스팸 필터가 좋은 예입니다. 스팸 필터는 많은 메일 샘플과 소속 정보(스팸인지 아닌지)로 훈련되어야 하며 어떻게 새 메일을 분류할지 학습해야 합니다.
또 다른 전형적인 작업은 예측 변수predictor variable라 부르는 특성feature (주행거리, 연식, 브랜드 등)을 사용해 중고차 가격 같은 타깃 수치를 예측하는 것입니다. 이런 종류의 작업을 회귀regression 4라고 부릅니다(그림 1-6). 시스템을 훈련시키려면 예측 변수와 레이블(중고차 가격)이 포함된 중고차 데이터가 많이 필요합니다.

일부 회귀 알고리즘은 분류에 사용할 수도 있고 또 반대의 경우도 있습니다. 예를 들어 분류에 널리 쓰이는 로지스틱 회귀는 클래스에 속할 확률을 출력합니다(예를 들면 스팸일 가능성 20 %).
다음은 가장 중요한 지도 학습 알고리즘들입니다(이 책에서 모두 다룹니다).
- k-최근접 이웃k-Nearest Neighbors
- 선형 회귀Linear Regression
- 로지스틱 회귀Logistic Regression
- 서포트 벡터 머신Support Vector Machines (SVM)
- 결정 트리Decision Tree와 랜덤 포레스트Random Forests
- 신경망Neural networks 6
비지도 학습
비지도 학습unsupervised learning에는 말 그대로 훈련 데이터에 레이블이 없습니다(그림 1-7). 시스템이 아무런 도움 없이 학습해야 합니다.

다음은 가장 중요한 비지도 학습 알고리즘7 입니다(8 장에서 차원 축소에 대해 다룹니다).
- 군집clustering
- k-평균k-Means
- 계층 군집 분석Hierarchical Cluster Analysis (HCA)
- 기댓값 최대화Expectation Maximization
- 시각화visualization와 차원 축소dimensionality reduction
- 주성분 분석Principal Component Analysis (PCA)
- 커널kernel PCA
- 지역적 선형 임베딩Locally-Linear Embedding (LLE)
- t-SNEt-distributed Stochastic Neighbor Embedding
- 연관 규칙 학습Association rule learning
- 어프라이어리Apriori
- 이클렛Eclat
예를 들어 블로그 방문자에 대한 데이터가 많이 있다고 합시다. 비슷한 방문자들을 그룹으로 묶기 위해 군집 알고리즘을 적용하려 합니다(그림 1 -8 ). 하지만 방문자가 어떤 그룹에 속하는지 알고리즘에 알려줄 수 있는 데이터 포인트가 없습니다. 그래서 알고리즘이 스스로 방문자 사이의 연결고리를 찾습니다. 예를 들어 40 %의 방문자가 만화책을 좋아하며 저녁때 블로그 글을 읽는 남성이고, 20 %는 주말에 방문하는 공상 과학을 좋아하는 젊은 사람임을 알게 될지도 모릅니다. 계층 군집hierarchical clustering 알고리즘을 사용하면 각 그룹을 더 작은 그룹으로 세분화할수 있습니다.8 그러면 각 그룹에 맞춰 블로그에 글을 쓰는 데 도움이 될 것입니다.

시각화visualization 알고리즘도 비지도 학습 알고리즘의 좋은 예입니다. 레이블이 없는 대규모의 고차원 데이터를 넣으면 도식화가 가능한 2D나 3D 표현을 만들어줍니다(그림 1-9). 이런 알고리즘은 가능한 한 구조를 그대로 유지하려 하므로(예를 들어 입력 공간에서 떨어져 있던 클러스터cluster는 시각화된 그래프에서 겹쳐지지 않게 유지됩니다) 데이터가 어떻게 조직되어 있는지 이해할 수 있고 예상하지 못한 패턴을 발견할 수도 있습니다.
비슷한 작업으로는 너무 많은 정보를 잃지 않으면서 데이터를 간소화하려는 차원 축소dimensionality reduction가 있습니다. 이렇게 하는 한 가지 방법은 상관관계가 있는 여러 특성을 하나로 합치는 것입니다. 예를 들어 차의 주행거리는 연식과 매우 연관되어 있으므로 차원 축소 알고리즘으로 두 특성을 차의 마모 정도를 나타내는 하나의 특성으로 합칠 수 있습니다. 이를 특성 추출feature extraction이라고 합니다.

또 하나의 중요한 비지도 학습은 이상치 탐지anomaly detection 입니다. 예를 들어 부정 거래를 막기 위해 이상한 신용카드 거래를 감지하고, 제조 결함을 잡아내고, 학습 알고리즘에 주입하기 전에 데이터셋에서 이상한 값을 자동으로 제거하는 것 등입니다. 시스템은 정상 샘플로 훈련되고, 새로운 샘플이 정상 데이터인지 혹은 이상치인지 판단합니다(그림 1 -10 ).
널리 사용되는 또 다른 비지도 학습은 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 연관 규칙 학습association rule learning 입니다.10 예를 들어 여러분이 슈퍼마켓을 운영한다고 가정합시다. 판매 기록에 연관 규칙을 적용하면 바비큐 소스와 감자를 구매한 사람이 스테이크도 구매하는 경향이 있다는 것을 찾을지도 모릅니다.

준지도 학습
어떤 알고리즘은 레이블이 일부만 있는 데이터도 다룰 수 있습니다. 보통은 레이블이 없는 데이터가 많고 레이블이 있는 데이터는 아주 조금입니다. 이를 준지도 학습semisupervised learning이라고 합니다(그림 1-11).
구글 포토 호스팅 서비스가 좋은 예입니다. 이 서비스에 가족사진을 모두 올리면 사람 A는 사진 1, 5, 11에 있고, 사람 B는 사진 2, 5, 7에 있다고 자동으로 인식합니다. 이는 비지도 학습(군집)입니다. 이제 시스템에 필요한 것은 이 사람들이 누구인가 하는 정보입니다. 사람마다 레이블이 하나씩만 주어지면11 사진에 있는 모든 사람의 이름을 알 수 있고, 편리하게 사진을 찾을 수 있습니다.
대부분의 준지도 학습 알고리즘은 지도 학습과 비지도 학습의 조합으로 이루어져 있습니다. 예를 들어 심층 신뢰 신경망deep belief network (DBN)은 여러 겹으로 쌓은 제한된 볼츠만 머신restricted Boltzmann machine (RBM)이라 불리는 비지도 학습에 기초합니다. RBM이 비지도 학습 방식으로 순차적으로 훈련된 다음 전체 시스템이 지도 학습 방식으로 세밀하게 조정됩니다.

강화 학습
강화 학습Reinforcement Learning은 매우 다른 종류의 알고리즘입니다. 여기서는 학습하는 시스템을 에이전트라고 부르며 환경environment을 관찰해서 행동action을 실행하고 그 결과로 보상reward (또는 [그림 1-12]처럼 부정적인 보상에 해당하는 벌점penalty )을 받습니다. 시간이 지나면서 가장 큰 보상을 얻기 위해 정책policy이라고 부르는 최상의 전략을 스스로 학습합니다. 정책은 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의합니다.

예를 들어 보행 로봇을 만들기 위해 강화학습 알고리즘을 많이 사용합니다. 딥마인드DeepMind 의 알파고AlphaGo 프로그램도 강화 학습의 좋은 예입니다. 2017년 5월 바둑 세계챔피언인 커제 선수를 이겨서 신문의 헤드라인을 장식했습니다. 알파고는 수백만 개의 게임을 분석해서 승리에 대한 전략을 학습했으며 자기 자신과 많은 게임을 했습니다. 알파고가 세계챔피언과 게임할 때는 학습 기능을 끄고 그동안 학습했던 전략을 적용한 것입니다. 12
1.3.2 배치 학습과 온라인 학습
머신러닝 시스템을 분류하는 데 사용하는 다른 기준은 입력 데이터의 스트림stream 으로부터 점진적으로 학습할 수 있는지 여부입니다.
배치 학습
배치 학습batch learning에서는 시스템이 점진적으로 학습할 수 없습니다. 가용한 데이터를 모두 사용해 훈련시켜야 합니다. 일반적으로 이 방식은 시간과 자원을 많이 소모하므로 보통 오프라인에서 수행됩니다. 먼저 시스템을 훈련시키고 그런 다음 제품 시스템에 적용하면 더 이상의 학습없이 실행됩니다. 즉, 학습한 것을 단지 적용만 합니다. 이를 오프라인 학습offline learning이라고 합니다.
배치 학습 시스템이 (새로운 종류의 스팸 같은) 새로운 데이터에 대해 학습하려면 (새로운 데이터뿐만 아니라 이전 데이터도 포함한) 전체 데이터를 사용하여 시스템의 새로운 버전을 처음부터 다시 훈련해야 합니다. 그런 다음 이전 시스템을 중지시키고 새 시스템으로 교체합니다.
다행히 ([그림 1-3]에 보았듯이) 머신러닝 시스템을 훈련, 평가, 론칭하는 전체 과정이 쉽게 자동화될 수 있어서 배치 학습 시스템도 변화에 적응할 수 있습니다. 데이터를 업데이트하고 시스템의 새 버전을 필요한 만큼 자주 훈련시키면 됩니다.
이런 방식이 간단하고 잘 작동하지만 전체 데이터셋을 사용해 훈련하는 데 몇 시간이 소요될 수 있습니다. 보통 24시간마다 또는 매주 시스템을 훈련시킵니다. 시스템이 빠르게 변하는 데이터에 적응해야 한다면(예를 들면 주식가격) 더 능동적인 방법이 필요합니다.
또한 전체 데이터셋을 사용해 훈련한다면 많은 컴퓨팅 자원이 필요합니다(CPU , 메모리 공간, 디스크 공간, 디스크 IO , 네트워크 IO 등). 대량의 데이터를 가지고 있는데 매일 처음부터 새로 훈련시키도록 시스템을 자동화한다면 큰 비용이 발생할 것입니다. 데이터 양이 아주 많으면 배치 학습 알고리즘을 사용하는 게 불가능할 수도 있습니다.
마지막으로, 자원이 제한된 시스템(예를 들면 스마트폰 또는 화성 탐사 로버rover )이 스스로 학습해야 할 때 많은 양의 훈련 데이터를 나르고 학습을 위해 매일 몇 시간씩 많은 자원을 사용하면 심각한 문제를 일으킵니다.
이런 경우에는 점진적으로 학습할 수 있는 알고리즘을 사용하는 편이 낫습니다.
온라인 학습
온라인 학습online learning 에서는 데이터를 순차적으로 한 개씩 또는 미니배치mini-batch 라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킵니다. 매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 대로 즉시 학습할 수 있습니다(그림 1 -13).

온라인 학습은 연속적으로 데이터를 받고(예를 들면 주식가격) 빠른 변화에 스스로 적응해야 하는 시스템에 적합합니다. 컴퓨팅 자원이 제한된 경우에도 좋은 선택입니다. 온라인 학습 시스템이 새로운 데이터 샘플을 학습하면 학습이 끝난 데이터는 더 이상 필요하지 않으므로 버리면 됩니다(이전 상태로 되돌릴 수 있도록 데이터를 재사용하기 위해 보관할 필요가 없다면). 이렇게 되면 많은 공간을 절약할 수 있습니다.
컴퓨터 한 대의 메인 메모리에 들어갈 수 없는 아주 큰 데이터셋을 학습하는 시스템에도 온라인 학습 알고리즘을 사용할 수 있습니다(이를 외부 메모리out-of-core 학습이라고 합니다). 알고리즘이 데이터 일부를 읽어 들이고 훈련 단계를 수행합니다. 전체 데이터가 모두 적용될 때까지 이 과정을 반복합니다(그림 1 -14 ).

온라인 학습 시스템에서 중요한 파라미터 하나는 변화하는 데이터에 얼마나 빠르게 적응할 것인지 입니다. 이를 학습률learning rate 이라고 합니다.13 학습률을 높게 하면 시스템이 데이터에 빠르게 적응하지만 예전 데이터를 금방 잊어버릴 것입니다(최근에 나타난 스팸의 종류만 걸러낼 수 있는 스팸 필터를 원할 리는 없습니다). 반대로 학습률이 낮으면 시스템의 관성이 더 커져서 더 느리게 학습됩니다. 하지만 새로운 데이터에 있는 잡음이나 대표성 없는 데이터 포인트에 덜 민감해집니다.
온라인 학습에서 가장 큰 문제점은 시스템에 나쁜 데이터가 주입되었을 때 시스템 성능이 점진적으로 감소한다는 점입니다. 운영 중인 시스템이라면 고객이 눈치챌지 모릅니다. 예를 들어 로봇의 오작동 센서로부터, 혹은 검색 엔진을 속여 검색 결과 상위에 노출시키려는 누군가로부터 나쁜 데이터가 올 수 있습니다. 이런 위험을 줄이려면 시스템을 면밀히 모니터링하고 성능 감소가 감지되면 즉각 학습을 중지시켜야 합니다(가능하면 이전 운영 상태로 되돌립니다). 입력 데이터를 모니터링해서 비정상 데이터를 잡아낼 수도 있습니다(예를 들면 이상치 탐지 알고리즘을 사용해서).
1.3.3 사례 기반 학습과 모델 기반 학습
머신러닝 시스템은 어떻게 일반화되는가에 따라 분류할 수도 있습니다. 대부분의 머신러닝 작업은 예측을 만드는 것입니다. 이 말은 주어진 훈련 데이터로 학습하지만 훈련 데이터에서는 본적 없는 새로운 데이터로 일반화되어야 한다는 뜻입니다. 훈련 데이터에서 높은 성능을 내는 것이 좋지만 그게 전부는 아닙니다. 진짜 목표는 새로운 샘플에 잘 작동하는 모델입니다.
일반화를 위한 두 가지 접근법은 사례 기반 학습과 모델 기반 학습입니다.
사례 기반 학습
아마도 가장 간단한 형태의 학습은 단순히 기억하는 것입니다. 스팸 필터를 이러한 방식으로 만들면 사용자가 스팸이라고 지정한 메일과 동일한 모든 메일을 스팸으로 분류합니다. 최악의 방법은 아니지만 최선도 아닙니다.
스팸 메일과 동일한 메일을 스팸이라고 지정하는 대신 스팸 메일과 매우 유사한 메일을 구분하도록 스팸 필터를 프로그램할 수 있습니다. 이렇게 하려면 두 메일 사이의 유사도similarity를 측정해야 합니다. 두 메일 사이의 매우 간단한 유사도 측정 방법은 공통으로 포함한 단어의 수를 세는 것입니다. 스팸 메일과 공통으로 가지고 있는 단어가 많으면 스팸으로 분류합니다.
이를 사례 기반 학습instance-based learning이라고 합니다. 시스템이 사례를 기억함으로써 학습합니다. 그리고 유사도 측정을 사용해 새로운 데이터에 일반화합니다(그림 1-15).

모델 기반 학습
샘플로부터 일반화시키는 다른 방법은 이 샘플들의 모델을 만들어 예측에 사용하는 것입니다. 이를 모델 기반 학습model-based learning이라고 합니다(그림 1-16).

예를 들어 돈이 사람을 행복하게 만드는지 알아본다고 가정합시다. OECD 웹사이트(https://goo.gl/0Eht9W)에서 더 나은 삶의 지표Better Life Index 데이터와 IMF 웹사이트(http://goo.gl/j1MSKe)에서 1 인당 GDP 통계를 내려받습니다. 두 데이터 테이블을 합치고 1 인당 GDP 로 정렬합니다. [표 1 -1]에 그 일부를 나타냈습니다.

일부 국가를 무작위로 골라서 그래프를 그려봅시다(그림 1 -17).

여기서 어떤 경향을 볼 수 있습니다! 데이터가 흩어져 있지만 (즉, 어느 정도 무작위성이 있지만) 삶의 만족도는 국가의 1 인당 GDP 가 증가할수록 거의 선형으로 같이 올라갑니다. 그러므로 1 인당 GDP 의 선형 함수로 삶의 만족도를 모델링해보겠습니다. 이 단계를 모델 선택model selection이라고 합니다. 1 인당 GDP 라는 특성 하나를 가진 삶의 만족도에 대한 선형 모델linear model 입니다(식 1 -1).
식 1-1 간단한 선형 모델
삶의_만족도 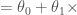
이 모델은 두 개의 모델 파라미터 
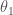

모델을 사용하기 전에
여기에서 선형 회귀Linear Regression 알고리즘이 등장합니다. 알고리즘에 훈련 데이터를 공급하면 데이터에 가장 잘 맞는 선형 모델의 파라미터를 찾습니다. 이를 모델을 훈련training시킨다고 말합니다. 이 경우에는 알고리즘이 최적의 파라미터로 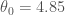

[그림 1 -19]에서 볼 수 있듯이 모델이 훈련 데이터에 (선형 모델로서) 가능한 한 가깝게 맞춰졌습니다.

이제 이 모델을 사용해 예측을 할 수 있습니다. 예를 들어 OECD 데이터에 없는 키프로스Cyprus 15 사람들이 얼마나 행복한지 알아보려면 이 모델을 사용해 예측할 수 있습니다. 키프로스의 1 인당 GDP 를 보면 22 ,587 달러이므로 이를 모델에 적용해 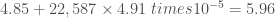
[예제 1 -1]의 파이썬 코드16는 데이터를 로드하고 준비한 다음 산점도scatterplot를 그려 시각화하고 선형 모델을 훈련하여 예측하는 과정을 보여줍니다.17
예제 1-1 사이킷런을 이용한 선형 모델의 훈련과 실행
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn
# 데이터 적재
oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
# 데이터 준비
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# 데이터 시각화
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# 선형 모델 선택
model = sklearn.linear_model.LinearRegression()
# 모델 훈련
model.fit(X, y)
# 키프로스에 대한 예측
X_new = [[22587]] # 키프로스 1인당 GDP
print(model.predict(X_new)) # 결과 [[ 5.96242338]]
이전 코드에서 선형 회귀 모델을 k-최근접 이웃 회귀로 바꾸려면 아래 한 줄을
model = sklearn.linear_model.LinearRegression()
다음과 같이 바꾸면 됩니다.
model = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
모든 게 다 잘되면 모델은 좋은 예측을 내놓을 것입니다. 아니면 더 많은 특성(고용률, 건강, 대기오염 등)을 사용하거나, 좋은 훈련 데이터를 더 많이 모으거나, 더 강력한 모델(예를 들면 다항 회귀 모델)을 선택해야 할지 모릅니다.
지금까지의 작업을 요약해보겠습니다.
- 데이터를 분석합니다.
- 모델을 선택합니다.
- 훈련 데이터로 모델을 훈련시킵니다(즉, 학습 알고리즘이 비용 함수를 최소화하는 모델 파라미터를 찾습니다).
- 마지막으로 새로운 데이터에 모델을 적용해 예측을 하고(이를 추론inference이라고 합니다), 이 모델이 잘 일반화되길 기대합니다.
이것이 전형적인 머신러닝 프로젝트의 형태입니다. 2장에서 완전한 프로젝트를 진행하면서 직접 경험해볼 것입니다.
지금까지 많은 부분을 다뤘습니다. 머신러닝이 무엇인지, 왜 유용한지, 머신러닝 시스템의 가장 일반적인 분류는 무엇인지, 그리고 전형적인 머신러닝 프로젝트의 작업 흐름이 어떤지 배웠습니다. 다음 절에서는 학습 과정에서 발생할 수 있는 문제와 정확한 예측을 방해하는 것들에 대해 알아보겠습니다.
3 옮긴이_ 머신러닝에서 레이블의 범주를 클래스(class )라고 부릅니다. 이 책에서는 프로그램 언어의 클래스와 같은 용어를 사용하므로 혼동하지 않도록 주의하세요.
4 재미있는 사실: 이 이상한 이름은 프란시스 골턴(Francis Galton)이 키가 큰 사람의 아이가 부모보다 작은 경향이 있다는 사실을 연구하면서 소개한 통계학 용어입니다. 부모보다 아이가 더 작기 때문에 이를 평균으로 회귀한다고 불렀습니다. 그 후 프란시스가 두 변수 사이의 상관관계를 분석하기 위해 사용한 방법에 이 이름을 붙였습니다.
5 옮긴이_ 이러한 이유로 원서에서는 데이터의 열(column)을 표현할 때 특성과 속성을 혼용하고 있습니다. 번역서에서는 데이터의 열 또는 변수를 의미할 때는 ‘특성’으로, 파이썬 클래스나 인스턴스의 변수를 의미하는 ‘property’와 ‘attribute’는 ‘속성’으로 번역했습니다.
6 오토인코더나 제한된 볼츠만 머신(restricted Boltzmann machine) 같이 일부 신경망 구조는 비지도 학습일 수 있습니다. 신경망은 또한 심층 신뢰 신경망(deep belief networks)이나 비지도 사전훈련(unsupervised pretraining )처럼 준지도 학습일 수도 있습니다. 옮긴이_ 비지도 사전훈련은 11장을, 제한된 볼츠만 머신과 심층 신뢰 신경망은 부록 E를 참조하세요. 오토인코더는 15장에서 자세히 설명합니다.
7 옮긴이_ k-평균, 계층 군집 등 여러 가지 비지도 학습 알고리즘은 『파이썬 라이브러리를 활용한 머신러닝』(한빛미디어, 2017)을 참고하세요.
8 옮긴이_ 여기에서 설명하는 계층 군집은 하향식(top-down)인 분할 군집(divisive clustering )을 말합니다. 사이킷런(Scikit-Learn)에서는 상향식(bottom-up) 계층 군집인 병합 군집(agglomerative clustering, https://goo.gl/9xKpxQ) 알고리즘을 제공하고 있습니다.
9 동물이 운송 수단과 잘 구분되어 있고 말이 사슴과 가깝지만 새와 떨어져 있는 것 등을 확인할 수 있습니다. 이 그림은 소셔(Socher), 간주(Ganjoo), 매닝(Manning), 앤드류 응(Andrew Ng)의 「T-SNE visualization of the semantic word space」(2013)입니다. 옮긴이_ 이 그림은 「Zero-Shot Learning Through Cross-Modal Transfer」(https://arxiv.org/abs/1301.3666)에서 발췌했습니다.
10 옮긴이_ 연관 규칙은 규칙 기반(rule-based) 학습의 한 종류로, 사이킷런에서는 제공하지 않습니다.
- 이는 시스템이 완벽했을 때입니다. 실제로는 사람마다 여러 개의 군집이 만들어지고 때로는 비슷한 외모의 두 사람이 섞이기도 합니다. 그래서 사람마다 레이블링을 여러 번 하고 어떤 군집은 수동으로 정리해야 합니다.
12 옮긴이_ 딥마인드는 2017년 10월에 기보 없이 스스로 학습하여 기존 알파고를 능가하는 알파고 제로(AlphaGo Zero)를 공개했습니다. https://goo.gl/MeFZmM
13 옮긴이_ 학습률은 대표적인 하이퍼파라미터입니다. 하이퍼파라미터에 대해서는 1.4.5절을 참조하세요.
14 관습적으로 그리스 문자  (세타)는 모델 파라미터를 표현할 때 자주 사용합니다. 옮긴이_
(세타)는 모델 파라미터를 표현할 때 자주 사용합니다. 옮긴이_ 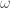 (오메가)와
(오메가)와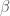 (베타)도 자주 사용합니다.
(베타)도 자주 사용합니다.
15 옮긴이_ 키프로스는 터키 아래쪽에 위치한 아름다운 지중해 섬나라입니다. 1974년에 일어난 내전 이후 터키계인 북부와 그리스계인 남부로 분단되어 있습니다.
16 이 코드는 GDP와 삶의 만족도 데이터를 하나의 판다스 데이터프레임으로 합치는 prepare_country_stats( ) 함수가 미리 정의되어 있다고 가정합니다. 옮긴이_ 1장의 주피터 노트북 안에 이 함수가 정의되어 있습니다.
17 전체 코드를 이해하지 못해도 괜찮습니다. 다음 장에서 사이킷런에 대해 소개합니다.
1.2 왜 머신러닝을 사용하는가? | 목차 | 1.4 머신러닝의 주요 도전 과제
